
OCRで業務を効率化!~1年間運用してわかったこと~

はじめに
初めての方ははじめまして、そうでない方はこんにちは。
タクシーアプリ『GO』のGO株式会社、QAエンジニアの松見です。
QAチームにありがちな課題として、『たくさんの機材・資材をどう管理するか』というものがあるかと思います。
GO株式会社クオリティマネジメント部においても1000個以上の機材を管理しており、バーコードで機材管理を簡略化したりと取り組んできました。

取扱いに困るのは借用品。
ペタペタラベルを張るわけにもいかず、棚卸ルールが異なるので1年前までは目視確認で棚卸を行っていました。
これをOCR(Optical Character Recognition)によって効率化し、昨年12月でちょうど運用1年を迎えましたのでどのように効率化したのか、運用してわかったことを書いていきます。
OCRで何をどのように効率化したのか
とある借用品の棚卸ルールは『1日2回、朝と夕に棚卸を行い証跡画像を取得の上、棚卸結果を関係者に報告する』というものでした。

さらっと聞けばどありがちなルールですが…
管理番号が10~16桁
対象がたくさんある
それを朝夕2回
管理者はメンバーの報告を待たねばならず、メンバーもいちいち報告しなくてはならない
と、毎日行うにしてはなかなかの重さです。
具体的には年間1人月くらいのコストがかかっていました。
効率化のアプローチ
借用機材の証跡画像撮影が運用上マストだったので、これを起点にOCRで文字列を認識させることを発想しました。撮影画像から機材の管理番号を読み取ることができれば後はどうにでもなるのです。
OCRは、Google Apps Script で DriveAPI を使えばほんの数行で実現できます。以下は実際の処理。(DrveAPIはv2なのでコピペで動かない可能性がありますがあしからず。)
let resource = {
title: "copiedFile"
};
let option = {
"ocr": true,
"ocrLanguage": "ja",
};
//fileIdはOCRする画像ファイルのidをわたす
let copiedFileID = Drive.Files.copy(resource, fileId, option).id;
const ocrText = DocumentApp.openById(copiedFileID).getBody().getText();あとは撮影日などのExifとあわせてチェックし、結果をSlackで通知するようにしました。(この部分は900行くらいある上、特筆すべきこともないので割愛します)
こうして、これまで通り「機材を撮影してアップロード」するだけで一連の棚卸作業が完了するようになりました。

運用して分かったこと
まず、過去の棚卸結果を正確に集計できるようになりました。
これは全く意図していなかったことなのですが、大部分を自動化したことでログから結果を集計することが容易になったためです。
そして集計結果を見ると、当事者も把握していなかったことも可視化されるようになりました。
結果として、さらなる改善の余地が見えることになったのです。
「棚卸NG」の発生状況
集計してみると1年間で100回近くの「棚卸NG」が発生していました。
当事者の誰もがこれほど多くの「棚卸NG」が発生しているとは思っていませんでした。
次のグラフは、「棚卸NG」の発生件数と原因を月ごとに集計したものです。

2023年5月から「棚卸忘れ」を別カウントとしています。理由は「棚卸忘れ」が原因の多くを占めていたためです。
意外と多い「ヒューマンエラー」
集計して意外だったのはOCRの誤認識よりも「棚卸忘れ」、「撮影日不正」(別の日や時間の画像が誤ってアップロードされていた)といった「ヒューマンエラー」が原因の7割弱を占めていたことです。

『7日に2回は誰かがミスしていた』と考えると感覚的には少し多い気がします。自動化以前のデータは無い為比較できませんが、「棚卸忘れ」は自動化によって業務の負荷が減った(≒結果として棚卸のマインドシェアが低下した?)影響があったりするのでしょうか。
余談ですが、改善後だけでなく改善前も計測しておく必要があるでしょう。よいことばかりがおきるとは限りません。想像もしないところに影響が出るものだということは我々QAエンジニアなら日常的に経験しているはずです。
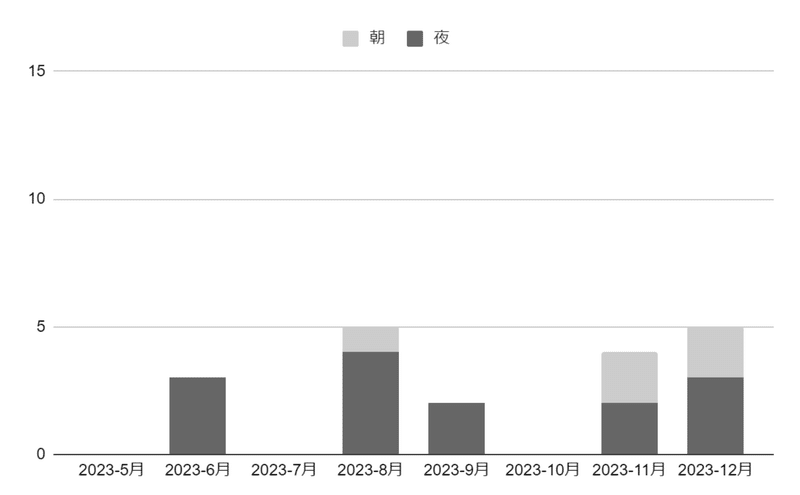
「ヒューマンエラー」は夜起きている
前述の「ヒューマンエラー」を時間帯ごとに集計してみると、夜は朝の3倍近く「ヒューマンエラー」が起きていることがわかりました。

実は、これは集計するまでもなくチームの共通認識としても存在していて、『夕方はバタバタしているので時間を変更してほしい』という意見を受けて7月から棚卸時間に柔軟性を持たせたのですが、あまり効果はなかったように見えます。
他の要因を探ったり、もう少し働き方に配慮した運用をデザインすべきでしょう。
OCRの誤認識とその原因
「その他の問題」はほぼOCRの誤認識と考えて差し支えありません。
OCRにありがちな「Iと1」や「Oと0」といった誤認識は対策済みですが、それでも年間30件と結構な誤認識があります。OCRの誤認識も夜のほうが多いことがわかりました。
OCRの誤認識はたいていの場合認識対象文字列の汚損や摩耗、そして撮影状況によって起こっていました。

2023年8月は読み取りエラーが多発していました。

裏地が透けて余計な文字列まで読み取ってしまったケース
当時は機材に貼付した付箋がクタクタになってしまったために起きたものだと考えていたのですが、こうして集計してみると発生時間が夜に集中しているので、光量が足りていないこととの合わせ技で読み取りエラーが起きていたような気がします。
とはいえ撮影に気を遣うのも本末転倒なので、OCRの前に画像処理を行うなど検討してもいいかもしれません。
誤認識にどう向き合うか
1年運用してチームがたどり着いた結論は「NG時だけ対象を目視確認すればいいよね」です。
これくらいの頻度でNG対象を目視確認するくらい十分許容できるという話です。
目視確認を容易にするため、棚卸NG時はNG機材と撮影画像が自動でスレッドに展開されるようにしました。(添付画像の時は20秒程度で「目視確認OK」のレスがついていました)

学び、気づき
棚卸にOCRというチョイスは、今にして思えば選択を誤ったと思います。
確かにOCRの認識精度は想像よりずっと良かったが校正は必要で、基本的には放置しておきたい自動運用には向かなかった。
運用手順を増やさずに撮影した画像をそのまま利用しようとするのも悪くない考えでしたが、より確実な手段(バーコード、QRコード)の検討から目を背けてしまった。
そもそも、借用品にラベルを直接貼付できないにしてもケースに入れるなどを考えればよかった。
ひいき目に見ても仕組みとしては50点くらいだと思います。
それでもシステム自体は短時間で作成され、プラスの価値を生み出せたことを考えるとたとえ50点でもやらないよりはずっとよかったんじゃないかなと思います。
業務ではつい完璧で劇的な成果を求めてしまいがちですが、「改善」は別に完璧である必要も劇的である必要もないわけです。
さいごに
思い付きから始まった取り組みにも関わらず「やってみればええ!やらない理由ある?」と背中を押してくださった関係者のみなさま、ありがとうございました。
本当によい仲間に恵まれているなと感じます。
そんなGO株式会社では、私たちと一緒にチャレンジしてくれる仲間を募集中です。
興味のある方は採用ページからご連絡頂けると嬉しいです!
この記事が気に入ったらサポートをしてみませんか?