
ChatGPTのベースとなった論文を簡単に解説①

ChatGPTは、OpenAIが開発した大規模言語モデルであり、GPT(Generative Pre-trained Transformer)シリーズの一部です。GPTの最初のバージョンは、Radfordらによる
「Improving Language Understanding by Generative Pre-Training」(2018)
という論文で発表されました。その後、GPT-2とGPT-3が発表されました。これらのモデルは、それぞれRadfordらによる
「Language Models are Unsupervised Multitask Learners」(2019)「Language Models are Few-Shot Learners」(2020)
という論文で紹介されています。

「Improving Language Understanding by Generative Pre-Training」という論文は、大量の自然言語データを用いて事前学習されたニューラルネットワークを使って、自然言語処理のタスクを解決する手法を提案したものです。
この手法では、大量のテキストデータを用いて、ニューラルネットワークを事前学習します。そして、その学習済みのニューラルネットワークを、自然言語処理のタスクを解決するために転移学習に利用します。転移学習とは、学習済みのモデルを別のタスクに適応することで、学習コストを削減する手法です。
自然言語処理の多くのタスクで高い精度を発揮し、BERTやGPTなどの大規模言語モデルの基盤となっています。また、この手法は自然言語処理だけでなく、画像認識や音声認識などの分野でも応用されています。
この手法が成功した理由の1つは、自然言語データを用いた「事前学習」の効果です。従来の機械学習では、データが不足している場合には、精度が低下する傾向がありました。しかし、この手法では、大量のテキストデータを用いて、モデルが自然言語の構造や文法を学習することができます。そのため、膨大なデータを用いて学習したモデルは、新しいタスクに対しても高い精度を発揮することができます。
また、Transformerと呼ばれるニューラルネットワークを用いています。Transformerは、自然言語処理のタスクにおいて高い精度を発揮することが知られており、GPTやBERTなどの大規模言語モデルにも利用されています。
※Transformerについては後日、別記事で纏めます

最近では、この手法を発展させた多数の大規模言語モデルが開発され、自然言語処理の精度が大幅に向上しています。これにより、機械翻訳、対話システム、文章生成などのタスクで、人間に匹敵するレベルの成果が得られるようになっています。
しかしながら、大規模言語モデルの学習には膨大な計算資源が必要であり、その開発や運用には高度な技術や資源が必要となります。また、大量のデータを用いた学習には、プライバシーや偏りなどの問題もあります。
そのため、今後はより小規模なモデルの開発や、データを効率的に活用するための研究が重要となってきます。例えば、転移学習や半教師あり学習などの技術を用いて、より少ないデータで高い精度を発揮する手法が研究されています。
また、大規模言語モデルの開発に伴い、エシックスやフェアネスなどの問題も浮上してきています。特に、差別や偏りを含むデータを用いた場合には、モデルがそれを反映してしまうことがあるため、それを避けるための研究が必要となっています。
さらに、大規模言語モデルは、自然言語処理に限らず、他の分野でも有用な応用が期待されています。例えば、画像処理や音声認識などでも、大規模言語モデルを応用することができます。また、自然言語処理においても、より高度なタスクに挑戦するために、より複雑なモデルの開発や、複数のモデルを組み合わせた手法などが研究されています。
最近では、オープンソースで利用可能な言語モデルの開発や、APIの提供などが進み、多くの企業や研究機関がこれらのモデルを利用しています。これにより、自然言語処理技術の普及が進み、様々な分野での応用が広がることが期待されています。
ただし、大規模言語モデルの開発は、まだ始まったばかりであり、今後ますます高度な技術や知見が求められることが予想されます。
また、自然言語処理技術の普及に伴い、様々な分野での利用が進んでいます。例えば、検索エンジンの改善や、自動要約、感情分析、音声アシスタント、自動翻訳、自動生成など、多くの分野で自然言語処理技術が応用されています。
自然言語処理技術は、社会におけるコミュニケーションの改善にも役立つことが期待されます。例えば、多言語翻訳技術により、異なる言語を話す人々がコミュニケーションを取りやすくなり、文化や価値観の共有が促進されることが期待されます。
ただし、自然言語処理技術の応用には、倫理的、社会的な問題もあるため、技術的な側面だけでなく、社会的、倫理的な側面にも注目が必要となります。例えば、個人情報の保護、偏見や差別の排除、情報の透明性や公正性などが問題となっています。
自然言語処理技術を用いた応用に取り組む際には、技術的な側面だけでなく、社会的、倫理的な側面にも配慮し、慎重に検討することが重要です。
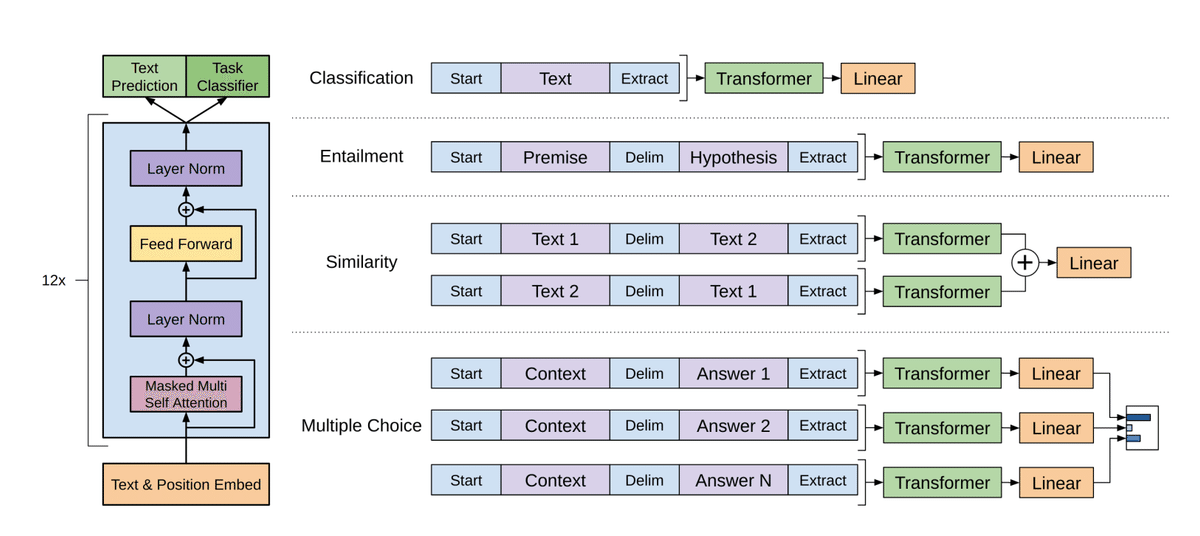
自然言語理解には、テキストの推論、質問応答、意味的類似性の評価、文書の分類など、多様なタスクが含まれます。大量の未ラベルデータが存在する一方、これらのタスクを学習するためのラベル付きデータは不足しており、区別的に学習されたモデルが適切に機能することは困難です。そこで、未ラベルのテキストコーパスで言語モデルを生成的に事前学習し、その後、各特定のタスクについて区別的な微調整を行うことで、これらのタスクにおける大幅な改善が実現できることを示します。以前の手法とは異なり、微調整中にタスクに適応した入力変換を行うことで、モデルアーキテクチャを最小限変更しながら、効果的な転移学習を実現します。私たちは、自然言語理解の様々なベンチマークで私たちのアプローチの有効性を示しました。タスクに依存しない一般的なモデルは、タスクごとに専用に設計されたアーキテクチャを使用する区別的に学習されたモデルよりも優れた性能を発揮し、12のタスクのうち9つで最先端技術を大幅に改善しました。例えば、常識的な推論(Stories Cloze Test)で8.9%、質問応答(RACE)で5.7%、テキスト推論(MultiNLI)で1.5%の絶対改善を達成しました。
自然言語処理において、未加工のテキストから効果的に学習する能力は、教師あり学習に依存することを緩和するために重要です。ほとんどの深層学習手法は、大量の手動ラベル付けされたデータが必要であり、注釈付けリソースが不足している多くのドメインでの適用範囲が制限されています。これらの状況では、未ラベルデータから言語情報を活用できるモデルは、アノテーションを集めることが時間と費用がかかるため、貴重な代替手段を提供します。利用可能な場合でも、教師なし学習で良い表現を学習することが大幅なパフォーマンス向上につながることがあります。
ただし、未ラベルのテキストから単語レベルの情報以上の情報を活用することは、2つの主要な理由から困難です。まず、どの種類の最適化目的が転移に有用なテキスト表現を学習するために最も効果的かは不明です。最近の研究は、言語モデリング、機械翻訳、および談話の整合性などのさまざまな目的を調べ、それぞれの手法が異なるタスクで他の手法よりも優れた結果を出しています。
このような課題に対処するために、大規模な事前学習された言語モデルを提案します。この方法では、多様な未ラベルのテキストコーパスで言語モデルを事前学習し、その後、特定のタスクに対して微調整することで、転移学習を実現します。このアプローチでは、事前学習された言語モデルは、ベクトル表現を作成するために単語と文脈を学習すると同時に、より高次元の表現を学習することができます。そして、微調整フェーズでは、タスクに適応するようにモデルを微調整することで、転移学習を実現します。
自然言語推論、問いに答える、文章分類などの幅広いタスクでアプローチの有効性を示しました。特に、この方法は、タスクに特化したアーキテクチャを使用する区別的に学習されたモデルを凌駕し、最先端の成果を大幅に改善することができました。
このような大規模な事前学習された言語モデルの開発により、ラベル付きデータが不足している多くのNLPタスクでの性能向上が期待されます。これは、人間の言語処理に対するより深い理解を提供し、自然言語処理の様々な応用分野での発展を促進することが期待されます。
この論文では、未監督事前学習と監督微調整を組み合わせた、言語理解タスクの半教師ありアプローチを探究しています。目標は、広範なタスクに対して適応性の高い一般的な表現を学習することです。未ラベルのテキストコーパスといくつかの手動注釈付きトレーニングデータセットがあることを前提にしています。このセットアップでは、未ラベルコーパスとターゲットタスクが同じドメインである必要はありません。2段階のトレーニング手順を採用しています。まず、未ラベルデータに対して言語モデリングの目的を使用して、ニューラルネットワークモデルの初期パラメータを学習します。その後、対応する監視目的を使用して、これらのパラメータをターゲットタスクに適応します。
モデルアーキテクチャには、多様なタスクで優れた性能を発揮することが示されているTransformer を使用しています。このモデル選択により、再帰ネットワークなどの代替手段と比較して、テキストの長期依存関係を扱うためのより構造化されたメモリが得られ、多様なタスクに対する堅牢な転移性能が実現できます。転移中には、トラバーサルスタイルのアプローチから派生したタスク特定の入力適応を使用し、構造化されたテキスト入力をトークンの単一連続シーケンスとして処理します。私たちは、実験でこれらの適応を使用して、事前学習されたモデルのアーキテクチャに最小限の変更で効果的に微調整することができることを示しました。
つまり ChatGPTでは再帰ネットワークを敢えて捨てることで並列度を高め、モデル学習量を飛躍的に高めたといえます。
自然言語推論、質問応答、意味的類似性、文書分類など、4つの種類の言語理解タスクでアプローチを評価しました。タスクに特化したアーキテクチャを使用する区別的に学習されたモデルよりも、一般的なタスクに対応するモデルの方が、12のタスクのうち9つで最先端の成果を大幅に改善することができました。たとえば、一般的な常識推論(Stories Cloze Test)では、8.9%の絶対改善を実現し、質問応答(RACE)では5.7%、テキスト同値性(MultiNLI)では1.5%、最近導入されたGLUEマルチタスクベンチマークでは5.5%の絶対改善を実現しました。また、プレトレーニングされたモデルのゼロショット行動を4つの異なる設定で分析し、下流タスクに役立つ言語知識を獲得することを示しました。
要するに、大量の未ラベルデータを使用して、汎用的な言語モデルを事前学習し、それを特定のタスクに微調整することで、タスクに特化したモデルを超える高い性能を実現することを示しています。これにより、ラベル付きデータが不足している多くの自然言語処理タスクにおいて、高い性能向上が期待されます。また、この手法により、自然言語処理の様々な応用分野での発展が促進され、人間の言語処理に対するより深い理解を提供することが期待されます。
「Improving Language Understanding by Generative Pre-Training」(2018)
の1章は以上です。

https://note.com/modern_ferret431/n/n214fb910b144
へ続きます。
この記事が気に入ったらサポートをしてみませんか?