
【標準版】ChatGPTを使用した多機能LINEbotを設置しよう【LineBotForGPT1.2】

はじめに
近年、AI技術の進化により、自然言語処理がますます人間のような対話を実現できるようになっています。その中でも、OpenAIのChatGPTは、様々な会話を行うことができるAIとして注目を集めています。今回は、コードの編集なしで設置可能な多機能なLINEボットを作成しましたので、その機能と設置手順ご紹介をさせていただきます。本ボットは小規模な運用から大規模な運用まで幅広いレンジでの利用の応用が可能です。これからGoogle Cloud PlatformのCloud Runでアプリケーションを設置される方も参考になるかと思います。
注意事項
コード編集不要とはいえ設置手順は非常に複雑なので手に負えないと思ったら先に以下の記事で紹介されているものを設置してみてください。
設置がさらに複雑になりますが高機能版もあります。
掲載されている手順は2024年4月に確認したものです。
このボットは、OpenAI APIを利用しているため、事前にAPIキーが必要です。APIキーは、OpenAIのウェブサイトから取得できます。
このボットはGoogle Cloud Platformを使用しているため事前にGoogleアカウントが必要です。
このボットはLINEを使用しているため事前にLINE Businessアカウントが必要です。
このボットの設置にはGithubを使用しているためGithubアカウントが必要です。Githubアカウントの作成手順については手順の中で解説しています。
OpenAI APIとGoogle Cloud Platformの利用料が発生します。料金については記事内で説明しています。
主な機能
色々な機能を実装していますが以下に主な機能を挙げます。
WEB検索
「検索」「調べて」等のユーザーメッセージをトリガーにインターネット検索を行いその結果を得ることができます。


地図検索
「場所」「スポット」等のユーザーメッセージあるいはLINEアプリケーションの位置送信機能をトリガーに周辺情報の検索が行なえます。
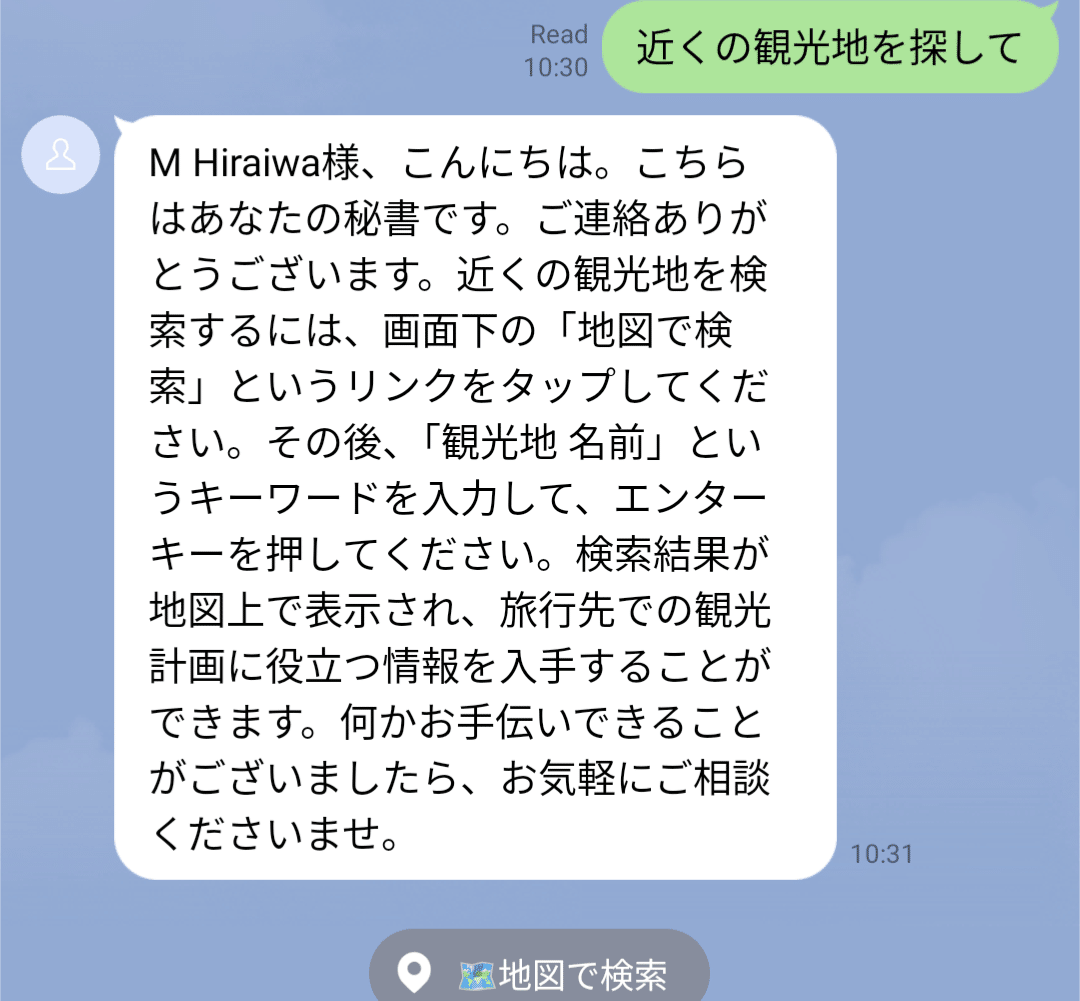

画像認識
画像を読ませてその返信を得ることができます。例えば書類を翻訳してもらったり、文章をまとめてもらったりすることが可能です。

時刻認識
時刻を意識したボットの行動付けが可能になります。

音声認識
LINEの機能を使用した声による会話が可能です。使える言語はWhisperの機能に依存します。

音声出力
音声出力機能をオンにすることで音声で受信することが可能です。この機能は初期値ではオフになっています。管理者が機能をオンにした状態に限りユーザーがクイックリプライでオンにすることができます。日本で需要の多そうな日本語、英語、中国語、韓国語に対応しています。



グループチャット
グループチャットにボットを参加させると、ボット名で話しかけることでボットからの回答を得られます。

利用制限
管理者が一日の利用回数を制限したり、無制限利用に設定することが可能です。

英語や中国語の音声切り替え
英語や中国語の切り替えモードがあります。「英語音声」「中国語音声」をトリガーにクイックリプライで切り替えます。

音声速度変更
音声速度変更モードがあります。「音声速度」をトリガーにクイックリプライで切り替えます。

利用料金
本システムを運用するための料金ですが、コード自体は無料です。利用するAPIやインフラが利用規模に応じて従量制の有料となります。
ChatGPTと音声認識、音声生成を保存するためのストレージ領域以外は小規模運用であれば無料で利用できます。無料を枠を超えたとしても大規模展開しなければ大した費用にはならないはずです。
2024年4月現在の料金は以下のようになっています。
OpenAI ChatGPT API
本コードでのチャットエンジンはリーズナブルなgpt-3.5-turboが標準です。1トークンは日本語一文字ぐらいで概算してください。
入力0.5ドル/1Mトークン
出力1.5ドル/1Mトークン
その他の料金はここを参照
OpenAI Whisper API
音声認識はリーズナブルなWhisperを使用しています。
0.006ドル/分
Google Cloud Build
ソースコードを実行できるようにビルドする際に最低スペックのサーバーでビルドする基準の料金です。
無料枠に収まると思うのでほぼ気にする必要はないです。
$0.003/ビルド分。1 日あたり最初の 120 ビルド分は無料
その他の料金はここを参照
Google Cloud Run
ソースコードを実行するサーバーの利用料金です。
小規模利用であれば無料枠で運用できるかと思います。
CPU:毎月最初の 180,000 vCPU 秒は無料
メモリ:毎月最初の 360,000 GiB 秒は無料
リクエスト:毎月 200 万リクエストは無料
その他の料金はここを参照
FireStore
会話ログを保存するためのデータベースです。
小規模利用であれば無料枠で運用できるかと思います。
ドキュメントの読み取り:50,000回/日まで無料
ドキュメントの書き込み:20,000回/日まで無料
ドキュメントの削除:20,000回/日まで無料
保存データ:1GBまで無料
その他の料金はここを参照
Places
地図検索を行うためのAPIです。
まず使い切ることのできない豊富な無料枠があります。
$200/月まで無料
その他の料金はここを参照
Custom Search
Web検索を行うためのAPIです。
小規模利用であれば無料枠で運用できるかと思います。
100回/日までは無料
その他の料金はここを参照
Cloud Vision
画像認識を行うためのAPIです。
価格計算がユニットという単位で計算されるので計算しにくいです。回数ではないです。小規模利用であれば無料枠で運用できるかと思います。
超えたとしても大した金額ではないです。
1,000 ユニット/月までは無料
その他の料金はここを参照
Cloud Text-to-Speech
テキストを音声に変換するAPIです。
小規模利用であれば無料枠で運用できるかと思います。
0〜400 万文字/月までは無料
その他の料金はここを参照
Cloud Strage
音声に変換したファイルを置いておく場所です。
料金計算がとにかく複雑ですがタダではないので無料枠で運用したい人は音声出力機能をオフにしてください。
料金はここを参照
Artifact Registry
デプロイ時に利用される領域です。デプロイ履歴を放置しておくと蓄積されます。
少量だと問題ない程度の料金ですがため込むと高額請求されますので注意してください。
その他の料金はここを参照
LINE
Botから自発的(Push)に送信しなければどれだけやり取りしても無料枠内で運用できる良心価格です。
音声出力の文字と音声の併用機能をオンにした場合は200通/月まで無料です。200通以上は月額5000円になりますので利用される前に再度ご検討ください。
料金はここを参照
動作デモ
動作デモを用意しました。LINEアプリで以下のQRコードを読み込んでください。

動作デモでは以下のように設定しております。制限内容は利用状況により予告なしに代わります。また、予告なしにメンテナンスのため停止したり過去のデータを削除することがあります。
・一日で利用できる会話数は通常チャット1日20回+グループチャット1日20回まで。
・音声出力は「True」設定なため「音声設定」コマンドでモードを変更することによりGoogle Cloud Text-to-Speechにて音声出力可能。
設定
以下に設定手順を記載します。
GitHubの設定
まずはGithubという場所にソースコードをコピーするためにアカウントを作成するところから始めます。
🔗GitHub Japan | GitHubにアクセスし「GitHubに登録する」を押します。

登録情報を入力し「Crate accont」を押します。

メールにコードをが届くのでそれを入力します。
GitHubのURLコピー
筆者が作成したソースコードをあなたのGithubのアカウントにコピーします。
🔗Githubの筆者のソースコードが置いてあるページにアクセスします。
右上の「fork」から「Create a new fork」を選びます。

「Create fork」を押します。
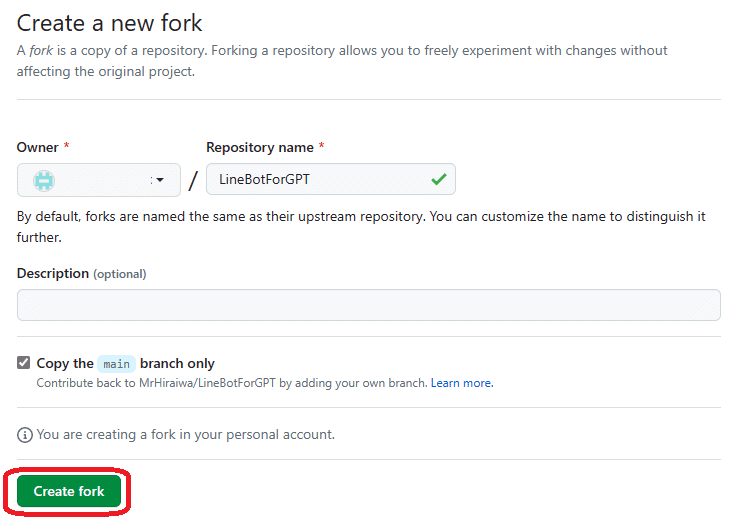
以上でコードが自分のGithubアカウントにコピーされました。
Identity and Access Management APIの有効化
Googleが提供するサーバー上でスクリプトを実行するための作業を行っていきます。
Googleアカウントを作成済みでGoogle Cloud Platformの🔗コンソール画面にログインできることを前提とします。
画面中央上側の検索ボックスに「identity and access management」と入力し「Identity and Access Management(IAM) API」を選択します。
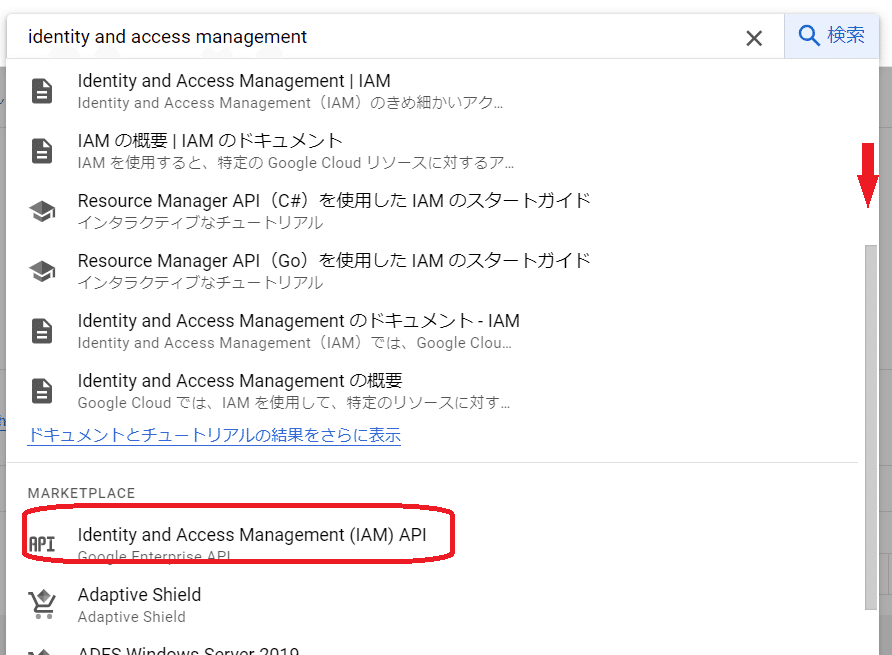
「有効にする」を押します。

Cloud Runの設定
次に実行環境の設定を行います。
画面中央上側の検索ボックスに「cloud run」と入力し「Cloud Run」を選択します。

「サービスの作成」を選択します。
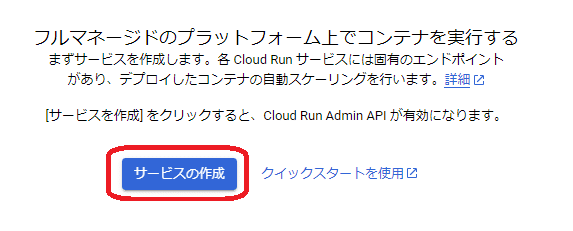
「ソースリポジトリから新しいリビジョンを断続的にデプロイする」を選択し「CLOUD BUILDの設定」を押します。
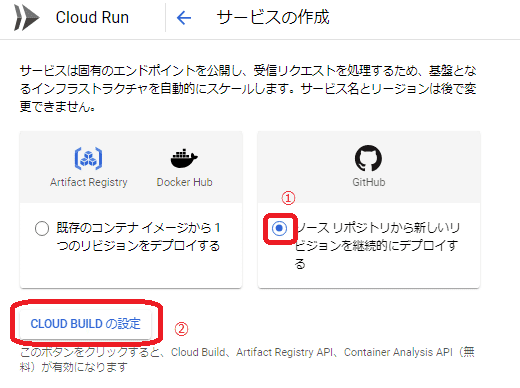
Githubの認証画面が表示される場合は「Username or email address」には自分のGitHubアカウント、「Password」にはGitHubのパスワードを入力し「Sign in」を押します。
リポジトリから「LineBotForGPT」を選択し、チェックをつけたら「次へ」を押します。

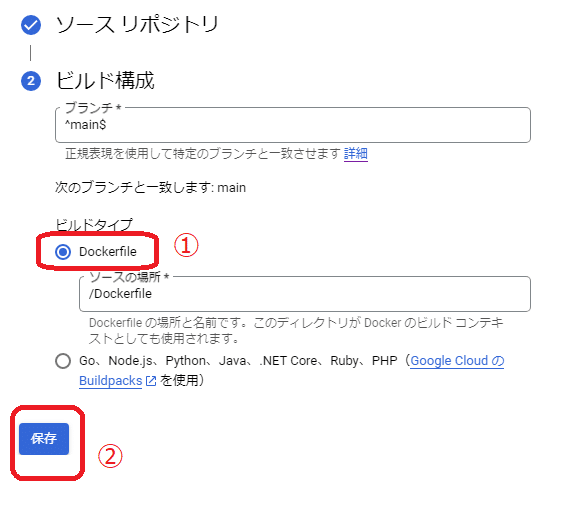
「Dockerfile」を選択して「保存」を押します。
リージョンに「asia-northeast1(東京)」を選択、認証で「未承認の呼び出しを許可」を選択して「作成」を押します。

エラーが表示されますがそのまま待ちます。

状況が改善されない場合上部の「断続的デプロイを編集します」を選択します。CLOUD BUILDERの設定と同じ設定画面が出るので設定をやり直します。

デプロイが一向に進まない場合はCloud Buildの管理画面を確認します。

画面中央上側の検索ボックスに「cloud build」と入力し「Cloud Build」を選択してCloud Buildの管理画面を呼び出します。
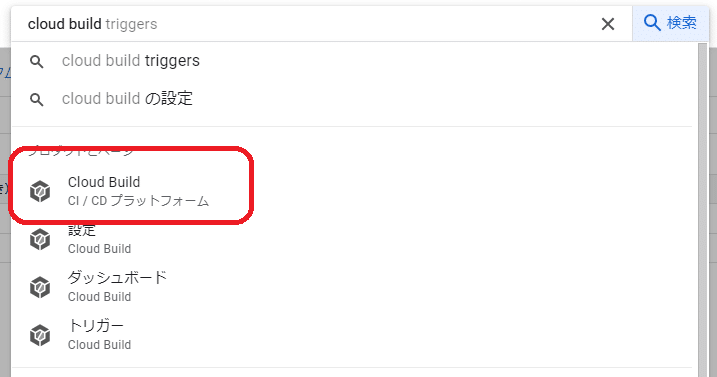
画面左側にマウスカーソルをあてるとメニューが表示されるので「トリガー」を選択します。

「リージョン」で「グローバル(非リージョン)」を選択し一覧に項目があった場合「実行」を押します。一覧に何もない場合はCloud runの管理画面から「断続的デプロイを編集します」をやり直してください。

「トリガーの実行」を押します。
エラーメッセージが表示され、トリガーが実行できない場合はエラーメッセージの指示に従ってください。

たとえばこのようなエラーが表示されたら、エラーメッセージ内に書かれているURLにアクセスして対象のAPIを有効にしてからトリガーを再実行してください。

画面中央上側の検索ボックスに「cloud run」と入力し「Cloud Run」を選択しCloudRun画面を呼び出します。
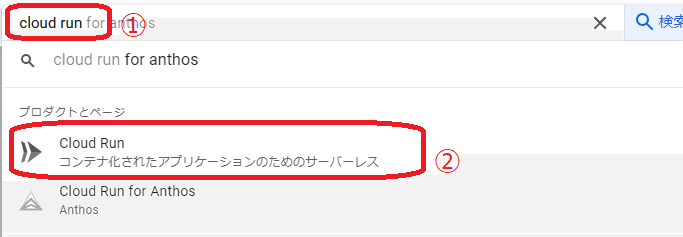
「linebotforgpt」を押します。

画面が以下の状態になっていることを確認します。なっていない場合はまだデプロイ中です。

以下の図の部分をクリックするとクリップボードにURLがコピーされます。
メモ帳か何かに貼り付けておいてください。LINEの設定時に使用します。

FireStoreAPIの設定
会話データと設定を保管しておくためにデータベースとして利用するFireStoreを設定していきます。画面中央上部の検索に「firestore」を入力し「Firestore」を選択します。

APIが無効で自動で有効にする警告メッセージが表示されるので少し待ってってからブラウザの更新ボタンで画面を更新します。
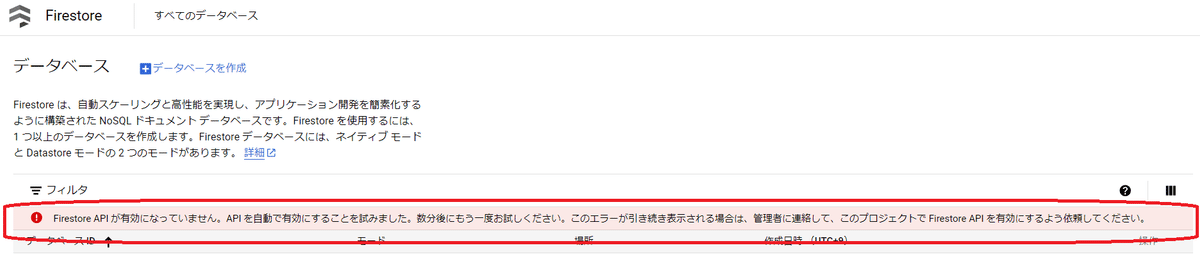
「データベースを作成」を押します。

「続行」を押します。
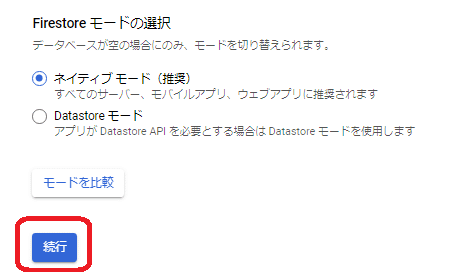
「データーベースID」を「linebotforgpt」にロケーションタイプを「リージョン」に、「リージョン」を「asia-northeast1(東京)」にして「データベースを作成」を押します。
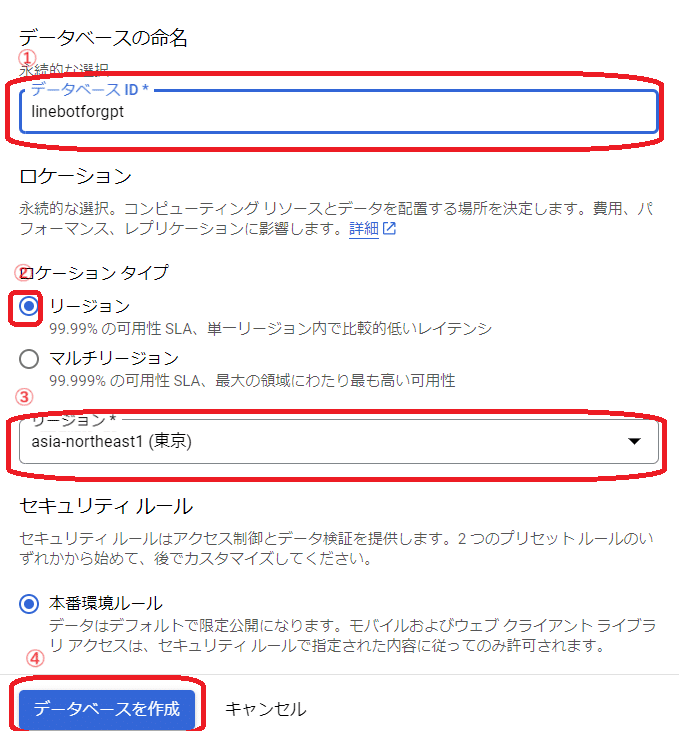
この画面に飛ばされたらデータベースの作成は完了です。

Google Cloud PlatformのAPIキー作成
一部のサービスと接続を行うのに必要になるAPIキーを作成していきます。
上部の検索ボックスに「認証情報」と入力し「認証情報(APIとサービス)」を選択します。

「認証情報を作成」を選択し「APIキー」を選択します。

APIキーの右側のアイコンをクリックしAPIキーをクリップボードにコピーします。「GOOGLE_API_KEY」に設定する情報となります。メモ帳などに貼り付けて一時保存しておきます。保存が終わったら「閉じる」を選択します。

Places APIの設定
地図検索を利用するのに必要な機能を設定します。
上部の検索ボックスに「Place」と入力し「Places API」を選択します。

「有効にする」を押します。

Custom Search APIの設定
Web検索に必要な機能を設定します。
Google Cloud Platformの上の検索ボックスに「custom search」と入力して「Custom Search API」を選択します。
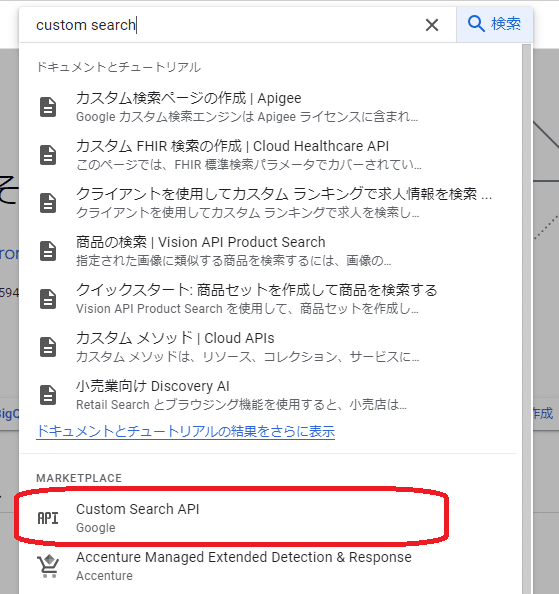
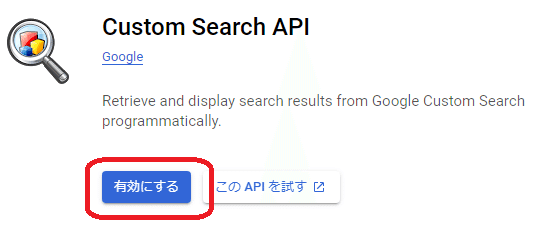
「有効にする」を押します。
Googleの🔗「プログラム可能な検索エンジン」のページに移動し「追加」を押します。

自分の任意の名前を「検索エンジンの名前を入力してください」に入れ「ウェブ全体を検索」「私はロボットではありません」を選択した後に「作成」を押します。

「カスタマイズ」を選択します。
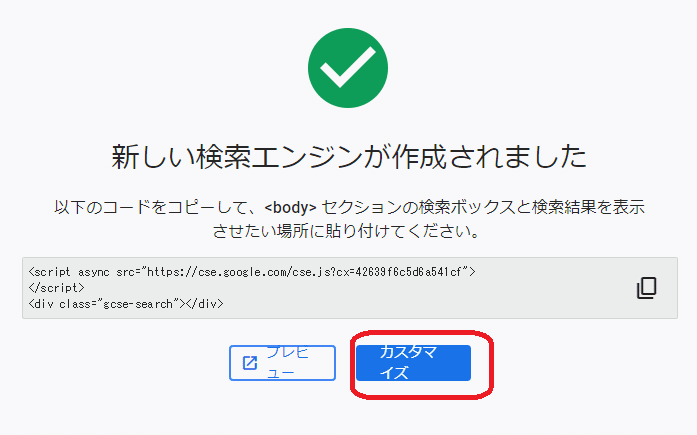
検索エンジンIDの右のアイコンを押しクリップボードに検索エンジンIDをコピーします。「GOOGLE_CSE_ID」に設定する情報となります。コピーしたIDはメモ帳などに保管しておきます。

Cloud Vision APIの設定
画像認識に必要な機能を設定します。
画面上部の検索ボックスに「cloud vison api」を入力し「Cloud Vision API」を選択します。

「有効にする」を押します。
Cloud Text-to-Speechの設定
音声出力に必要な機能を設定します。
音声出力はコード上で機能をオフにできますし初期設定でオフなので利用しない場合は手順を飛ばしてください。
Google Cloud Platformの上の検索ボックスに「text to speech」と入力して「Cloud Text-to-Speech API」を選択します。
(間違って「Cloud Speech-to-Text API」を選択しないでください)

「有効にする」を押します。

Cloud Strageの設定
音声出力したファイルをLINEにアクセスさせるためのストレージを設定します。
音声出力はコード上で機能をオフにできますし初期設定でオフなので利用しない場合は手順を飛ばしてください。
音声出力機能はCloud Storage機能を使う事が必須となりますがCloud Storageには無料枠が無いのでお金をなるべくかけたくない方は設定しないでください。
Google Cloud Platformの上の検索ボックスに「cloud storage」と入力して「Cloud Storage」を選択します。
画面上部の「作成」を押します。

バケットに任意の名前を入れ「続行」を押します。他の人とバケット名が被っていると作成できません。
データのロケーションで一番料金の安い「Region」を選択し「asia-northeast1(東京)」を選択し「続行」を押します。
「続行」を押します。

「このバケットに対する公開アクセス禁止を運用する」のチェックを外して「作成」を押してください。

左上のメニューから「バケット」を選択します。

バケット一覧の一番右側の点3つのアイコンを選択し「アクセス権の編集」を選択します。

「プリンシパルを追加」を押します。
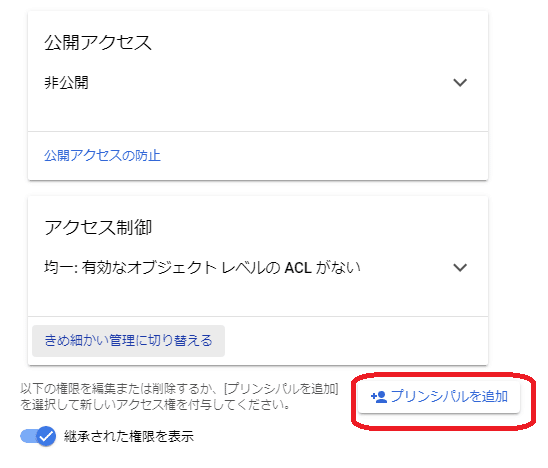
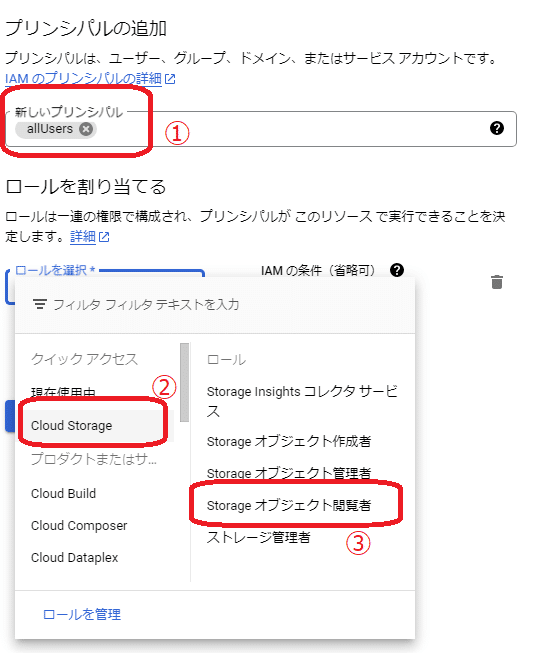
新しいプリンシパルに「allUsers(大文字小文字に注意)」を入力しロールを「Storageオブジェクト閲覧者」を選択します。
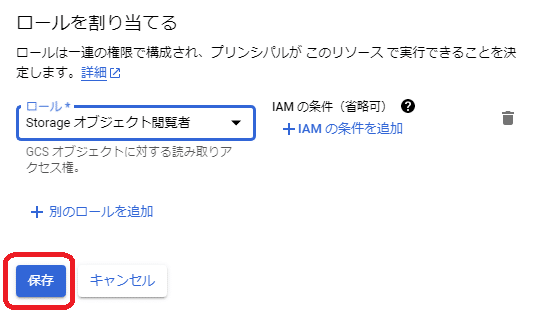
「保存」を押します。
「一般アクセスを許可」を選択します。

Lineの設定
LINE Businessが利用できる前提で説明します。
🔗LINE Developersのトップページ右上より「コンソールにログイン」を押します。

画面左上のメニューに表示されている自身のアカウント名を選択します
「新規チャンネル作成」を選択します。

「Messaging API」を選択します。

項目を自分の情報に合わせて設定します。以下の画像は設定例です

全て設定終わったら契約に同意し「作成」を押します。

「OK」を押します。

同意書を読んで「同意する」を押します。

もう一度同意書を読んで「同意する」を押します。

「チャネル基本設定」が選ばれていることを確認し、画面を下にスクロールします。

図の部分をクリックするとクリップボードにチャネルシークレットの文字列が張り付きます。この文字列はボット設定の際に利用します。


WebHook設定の「編集」を選択します。
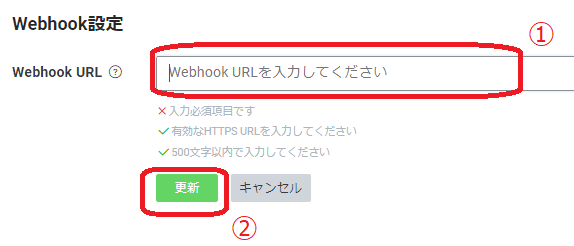
Webhook URLにCloud Runの設定時にメモしておいたURLを入力します。そのあと更新を押します。
「Webhookの利用」をオンにします。

チャネルアクセストークンの「発行」を押し、図の部分をクリックするとクリップボードにトークンの文字列が張り付きます。この文字列はボット設定の際に利用します。

LINE公式アカウント機能/グループトーク・複数人トークへの参加を許可するの「編集」を選択します。

トークへの参加を「グループ・複数人トークへの参加を許可する」に設定します。

ページを戻ってLINE公式アカウント機能/応答メッセージの「編集」を選択します。

「応答メッセージ」をオフにします。

自分のLINEへの登録
自分のLINEアプリにボットのチャンネルを登録します。
先ほど開いた「Messaging API設定」にQRコードがあるのでこれをスマートフォンのLINEアプリでスキャンすることでボットのチャンネルが登録されます。

環境変数の設定
🔗Cloud Runの管理画面から対象のサービスを選択します。

上部から「新しいリビジョンの編集とデプロイ」を選択します。

「変数とシークレット」を押します。

環境変数の「変数を追加」を押して「OPENAI_APIKEY」「LINE_ACCESS_TOKEN」「SECRET_KEY」「ADMIN_PASSWORD」「GOOGLE_API_KEY」「GOOGLE_CSE_ID」「DATABASE_NAME」の6項目を追加します。

OPENAI_APIKEY: OpenAIのAPIキーを入力してください。
LINE_ACCESS_TOKEN:LINEで発行したチャネルアクセストークンを設定してください。
SECRET_KEY:内部的にデータを暗号化するときに使う文字列です。適当に文字を入れてください。複雑な文字列ほどよいです。
ADMIN_PASSWORD:WEBの管理画面のログインに使用する管理者パスワードです。このシステムはインターネットから誰でも触れるので、必ず複雑なパスワードを設定してください。
GOOGLE_API_KEY:Google Cloud Pratformに発行したAPIキーを入力してください。
GOOGLE_CSE_ID:Google Cloud PratformのCustom Search設定時に発行した検索エンジンIDを設定してください。
DATABASE_NAME:FireStoreで作成したデータベース名、つまり「linebotforgpt」を入れてください。

一番下の「デプロイ」を押します。

アイコンがすべて緑になるまで待ちます。

ボットの設置は以上で完了です。
運用上の操作
本スクリプト利用にあたってのいくつか必要な操作を説明しておきます。
Botの設定変更
ブラウザのURL欄にメモしたURLの後に「/login」を追加して入力します。以下の画面が表示されるので環境変数に入れた管理者パスワードを入力して「submit」を押します。

以下は設定画面にある主な設定項目です。
BOT_NAME
ボットの名前を設定します。グループチャットの呼びかけの際に使用しますので呼びかけやすい名前にしてください。「,」区切りで複数名設定できます。
SYSTEM_PROMPT
ボットのキャラクター性を定義します。1000文字までを目安としてください。
PREVIOUS_DUMMY_[USER/ASSISTANT]_MESSAGE[1-4]
会話開始時に会話がおかしくなることがあるため、会話開始前のダミー会話を設定します。「USER」は利用者視点、「ASSISTANT」はボット視点の会話を設定します。キャラクターの口調に合わせてください。
MAX_DAILY_USAGE
利用者一人当たりの最大使用回数を設定します。
GROUP_MAX_DAILY_USAGE
グループチャット1ルーム毎の最大使用回数を設定します。
VOICE_ON
値を「True」にすると文字と音声を併用した出力機能が利用できるようになります。ただしこの機能を200回以上使うと想定されるならLINEの有料コースに入る必要があります。
値を「Reply」にするとボットの返信に音声だけが出力されるようになります。このモードはLINEの無料利用の範囲内で利用できます。通常の会話は音声で返りますがクイックリプライ発動時や各機能の実行時は文字で返信されます。
VOICE_GENDER
音声を「male」(男性)または「female」(女性)で指定できます。
BACKET_NAME
音声出力機能を利用する方は「VOICE_ON」の設定と合わせてこの項目を設定する必要があります。Cloud Strageで設定したバケット名を設定してください。
FILE_AGE
音声出力機能を利用している場合Cloud Strageに音声ファイルが保存されます。その保存日数を指定します。1日とかにしてしまうと翌日には音声ファイルが消えてしまいユーザーから再生されなくなります。
GPT_MODEL(β)
API版のGPT4が利用できる方はこの項目を「gpt-4」に変更することでGPT4での運用が可能になります。料金はgpt-3.5-turboに比べて2倍になり応答速度も遅くなり、通信のタイムアウトが増える恐れがありますので通常の運用では設定しないでください。
設定がすんだら一番下までスクロールして「Save」を押します。

忘れてコマンド
本スクリプトではGoogleアカウント単位で会話がデータベースに保存されたままになります。次回アクセス時にも継続して会話が可能です。
会話中に「忘れて」あるいは「わすれて」を入力するとクイックリプライが表示されます。クイックリプライを押すと使用者の以前の会話データが削除されます。

音声出力機能の有効化
管理画面の「VOICE_ON」を「True」に変更し、「BACKET_NAME」をCloud Strageに作成したバケット名に指定することで音声出力機能が利用可能になります。「FILE_AGE」はCloud Strageに音声データが保管される日数です。早く消した方が利用料金は安くなりますが、音声データを早く削除してしまうとユーザーが過去の会話から音声を再生できなくなってしまうので、利用用途に合わせて日数を調整してください。
ユーザーの全データ削除
管理画面の一番下にある「Reset All User Logs」を押すことで全ユーザーのデータが削除されます。「All user logs reset successfully」が表示されれば削除成功です。

最新版へアップデート
ソースコードは不具合が出たタイミングで見直しています。
Twitterやこのページで告知します。更新する際は以下のページを参考に更新をお願いします。
Githubへマージを行うと自動でGoogle Cloud Platformのデプロイが実行されます。デプロイをグローバルリージョンに変更していても自動実行されます。実行状態はCloud Buildの履歴画面から確認してください。
バージョンアップ後に管理画面からSAVEを忘れないでください。それでも動かない場合は設定値をいったんデフォルトに戻してください。
チェックシート
設定後に動かない際はここを確認してください。
デプロイが「generic::failed_precondition:due to quota restrictions, cannot run builds in this region」エラーで終了する。
Cloud Runのデプロイでリージョンキャパシティのエラーが出続ける場合、選択を東京リージョンに限定せず、他のリージョンを探してみてください。
レポジトリの紐づけが問題と表示されたらCloud Buildでのレポジトリ登録の手順を見直してください。
デプロイが「レポジトリのマッピングが存在しない」エラーで終了する。
レポジトリ登録はリージョン毎に必要です。リージョンを変更する際には、Cloud Runの設定前にレポジトリの登録を忘れずに行ってください。
デプロイがその他のエラーで終了する。
Cloud Buildのトリガーはリージョン毎に存在し、意識しなくてもビルド時に自動的に作成されます。リージョンを変更する際には、Cloud Buildのトリガーが残っていないか確認し、発見次第削除してください。
リージョンの選択基準がよくわからない。
日本に住んでいるなら東京一択だと思いますが、デプロイできない場合は他のリージョンの選択肢もやむなしです。
運用の複雑性を排除するため、Cloud Run、Cloud Build、Firestore、Cloud Storageのリージョンは、可能な限り統一して設定してください。
統一しなくても動作はします。
ティア2よりティア1の方が安いですがデプロイできない場合はティア2もやむなしです。
複雑になってもよいのであればCloud runを東京に設置しておいて別のリージョンでデプロイする方法もあります。
管理者画面にログインできない。
環境変数に設定しているパスワードを再度確認してください。
また、管理者パスワードは5回間違えると10分間ロックされます。
LINEの応答についてのトラブルシューティング
LINEからの応答がない場合は、以下の3つを確認してみてください。
環境変数の項目名と値を再確認する。環境変数名の前後に空白文字が入っていないか確認する。
LINE Developerで設定したWebhookのURL
管理画面での保存状況(SAVEが完了しているかどうか)
Cloud Runのログに怪しいログ(例えばERRORとかの文字列)が出力されていないか確認。
まとめ
ここまでたどり着いた人、長い道のりを本当にお疲れさまでした。ここまで来れた方はGoogle Cloud Platformについて十分に学習できたかと思います。
LINEボットの機能は作りこみの総まとめとなる内容にしました。
記事というよりは導入マニュアルという感じになりましたが一部の人には楽しめたかと思います。
以下は有償記事になりますが、興味がある人は高機能版もお試しください。
この記事が気に入ったらサポートをしてみませんか?