やーぐまやー AIとの出会い2021

はじめに
私は沖縄のmo1976ともうします。おじさんです。
無駄に時間ばかり浪費して来た我が人生です。
が、今まで苦手としていた、やった事がない事や未経験な事を
思い切って始めてみたいなとおぼろげながらに考えています。
考える事はお金もかからないのでいいですね。
本記事の概要
私は2021年2月8日から
アイデミー プレミアムプラン データ分析コース(3ヶ月)を受講しています。
もうすぐ開始から3カ月が経過しようとしています。
今日は5月5日で受講終了期限はもうすぐ。早く修了認定してもらわないと。
そこで、3カ月足らずの受講内容の振り返りを投稿してみたいと思います。
▼ 対象読者 : AI学習初心者を優しい眼差しで見つめてくれる方
▼ 記事内容 : 約3ヶ月間のアイデミー受講で苦労した事と最終課題の途中経過
最終課題 : プレミアリーグ選手データで教師あり学習(分類)
▼ 対象範囲外 : 最終課題の結果
アイデミーでの学習振り返り
1ヶ月目 : 2021年2月8日 - 3月9日
● まずは、Slackを学習用PCと携帯電話にインストールして、アイデミー用ワークスペースを設定しました。
● 続いて、学習環境の整備方法やカウンセリングの受け方など、このコースの受け方についての講習を受けました。
● さらに、転職支援(キャリア形成支援サービス)も受けました。
● アイデミーのAI教育コースはほぼすべてがブラウザベースのオンライン研修サービス群で構成されています。そのうちの1つ、AidemyBusinessのログイン情報をメールで受け取り、サクサクとAI教育コースを開始しました。
● 最初のコース(単元)は、Python入門です。データ分析で必要になるプログラミング言語Pythonの文法や実際の使用方法などを学習します。初めてでも安心な、分かりやすい内容になっています。
2ヶ月目 : 2021年3月8日 - 4月9日
● 教師あり学習(分類)
● 教師なし学習
● 時系列データ分析
● 深層学習、ニューラルネットワーク
3ヶ月目 : 2021年4月8日 - 5月9日
● Kaggleでのタイタニック号コンペ
● ブログを書き始める。
● 4月から始めたフリーランス業務で忙しくアイデミーとは疎遠になる。
作成したもの
最終課題で取り上げる題材はイングランドプレミアリーグ(以下、EPL)のデータ分析にしてみました。
個人的に好きで観戦しているので、データ内容を推測しやすいかと思い取り上げてみました。
まずは情報収集ということで、下記サイトをネット検索してみました。
▼ MatplotlibとPandasで2019 – 20年の英国プレミアリーグシーズンを視覚化
▽ @naveenv_92 さんのICHI.PROブログです。こちらを参考にさせて頂きたいと思います。
▼ English Premier League stats 2019-2020
▽ idoyo92 さんのKaggleプロジェクト
▼ プレミアリーグ公式 成績データ解説
▽ プレミアリーグの公式サイト 成績データについて解説されています。
つぎに入力データの準備です。
・ idoyo92さんのKaggleプロジェクトからCSVファイルをダウンロード
・上記のCSVファイルをローカルに別名保存
◦ epl2020.csv -> epl_games_2019_2020.csv (以下、試合情報CSV)
◦ players_1920_fin.csv -> epl_players_2019_2020.csv (以下、選手情報CSV)
EPLは夏に始まり春に終わります。
1920とか19-20、19/20と表記されていた場合は
2019年の夏(8月中旬ごろ)から2020年春(5月下旬ごろ)にかけての1シーズンの事を表します。
EPLの試合の情報をgames、選手の情報をplayersとして保管しておけば、
データのイメージがつきやすくなるかと思います。
そして入力データをGoogleDrive(以下GDrive)にアップロードします。
blogフォルダを作成して、そこにアップロードしました。
さらにGoogleColaboratory(以下Colab)ノートブックを作成します。
同じくblogフォルダに作成しました。
ノートブックファイル名は epl_2020_2021.ipynb としておきます。

ColabにGDriveのマイドライブをマウントします。

これで、準備が出来ました。
後はPythonコーディングして実行です。
[Python実行環境]
Google Colabratory
Python 3.7.10 ※2021/05/05時点
Colabで作成したコードは こちらのGitHubリポジトリで公開しています。
今回は時間の都合上、試合情報CSVは使用しませんでした。
選手情報CSVのみを入力用データの元として使用しています。
オリジナルの選手情報CSVベースにして、選手をWorldクラスとNationalクラスの2群に分類した epl_players_2019_2020_classified.csv を作成して読み込んでいます。分類は私個人の独断によります。
また、単純化のためチーム数を下記の2チームに絞り込んでいます。
[対象チーム]
- マンチェスター・シティ
- リヴァプール
この2チームに属する、下記の4選手をWorldクラスとしてピックアップしました。全員攻撃的な選手です。
(異論反論があるかとは思いますがご容赦ください。Nationalという表現もいかがなものかとは思います。)
[Worldクラス]
1. ケヴィン・デ・ブライネ
2. セルヒオ・アグエロ
3. サディオ・マネ
4. モハメド・サラー
これら4選手とそれ以外のNationalクラスの選手とで、
ゴール数・アシスト数・失点数などの特徴量に何らかの相関が見られるか?
教師あり学習(分類)で学習した事を参考に課題に取り組みました。
[選手情報CSVの特徴量]
# 選手データ - 特徴量の出力
print(player_data.columns.values)
['Unnamed: 0' 'assists' 'bonus' 'bps' 'clean_sheets' 'creativity'
'element' 'fixture' 'goals_conceded' 'goals_scored' 'ict_index'
'influence' 'kickoff_time' 'minutes' 'opponent_team' 'own_goals'
'penalties_missed' 'penalties_saved' 'red_cards' 'round' 'saves'
'selected' 'team_a_score' 'team_h_score' 'threat' 'total_points'
'transfers_balance' 'transfers_in' 'transfers_out' 'value' 'was_home'
'yellow_cards' 'full' 'team' 'ppm' 'class']結構、特徴量が多いですね。使用するものは下記です。
assists : アシスト数
goals_conceded : 得点数
goals_scored : 失点数
threat : 脅威
下のグラフは、得点数+アシスト数(横軸。攻撃力指標)と失点数(縦軸。守備力指標)の上位20選手をプロットしたものになります。
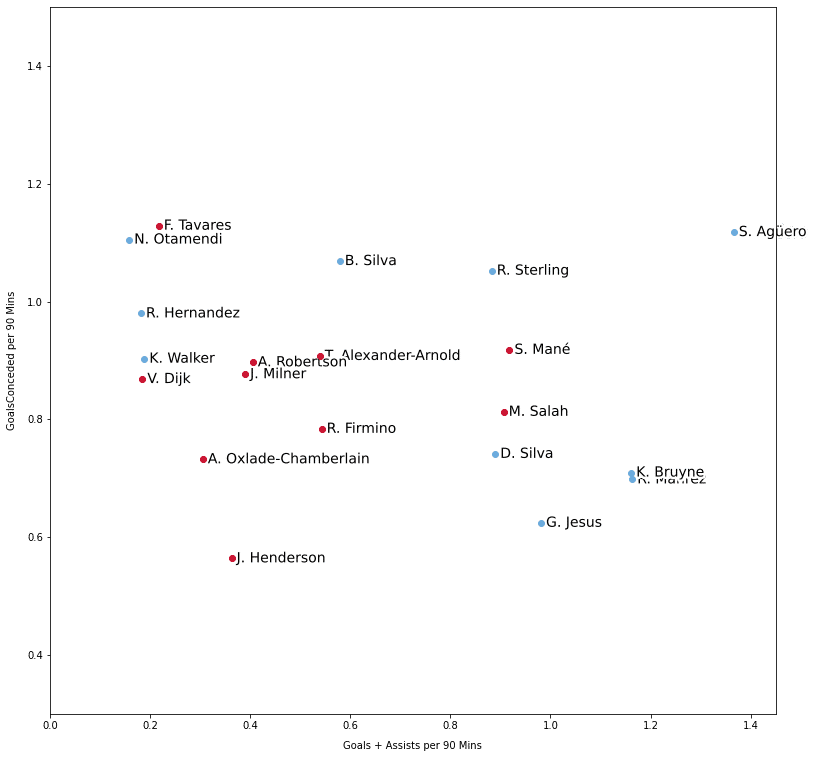
以下、コードの抜粋です。
# Lord English Premier League Statistics of 2020/2021 season.
target_directory = './drive/MyDrive/Colab Notebooks/blog/'
player_data_file = target_directory + 'epl_players_2019_2020_classified.csv'
# 選手データ(選手のゲーム別成績)
player_data = pd.read_csv(player_data_file)
# チームの絞り込み LiverpoolとManchesterCityの2チームに限定
player_data = player_data[player_data.team.isin(['Liverpool', 'Man City'])]
# 90分あたりのゴール数+アシスト数(攻撃的特徴量)
player_goals_and_assists = {}
# 90分あたりの失点数(守備的特徴量)
player_goals_conceded = {}
for player in players:
mins = player_data[player_data['full'] == player].minutes.sum() / 90.
if mins >= 10:
player_goals_and_assists[player] = (player_data[player_data['full'] == player].goals_scored.sum() / mins) + (player_data[player_data['full'] == player].assists.sum() / mins)
player_goals_conceded[player] = player_data[player_data['full'] == player].goals_conceded.sum() / mins
# Refer to https://premium.aidemy.jp/courses/5020/exercises/rkEPkJ3Qm
# 教師あり学習(分類) 1.1.5 データを用意する方法(2)
# playersの1列目(assists), 8列目(goals_conceded), 9列目(goals_scored)を格納
X = player_data.iloc[:, [1, 8, 9]]
# top_players_goals_concededのクラスラベルを格納
y = player_data['class']
# テストデータとトレーニングデータの分割
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42)
# ロジスティック回帰 線形分離可能な分類か調査
# モデル構築
model = LogisticRegression()
# 学習
model.fit(train_X, train_y)
# 予測
model.predict(test_X)
# 正解率の評価
model.score(test_X, test_y)4つの特徴量と、教師あり学習(分類)で学習した機械学習モデルを組み合わせて、2値(2群)分類の予測スコアが最も高い組み合わせを割り出しました。時間の都合上、全ての組み合わせパターンは網羅していません。

結果として、今回のような攻撃的でワールドクラスとされる選手の分類には、脅威(threat)の特徴量で分類可能である事が分かりました。
モデルごとの予測値性能差はほとんど見受けられませんでした。
ロジスティック回帰の単純な線形分類で十分分類可能でした。
チーム数を絞り、データ量が限定されていたため、モデルごとの性能差が発揮されにくかったのかも知れません。
守備的なワールドクラスもピックアップして、失点数との相関があるか調べてみるのも面白そうです。
今後の活用
フットボールの世界は無数のデータで溢れています。
また、データ分析も日常的に利用されています。
今回のような単純な分類だけではなく、当然ながら各種データから回帰しての勝敗予測やスコア予測・選手評価・スカウティング活動など、データは欠かせません。
私も少しずつでもデータ分析の世界に触れていき、自分の応援するチームをデータ面で分析して、より深くフットボールを好きになっていきたいです。
おわりに
長文にお付き合い頂きましてありがとうございました。
私にとっては、何だかあっという間の3ヶ月間でした。
この間私は何をやっていたのだろう。
そんな風に悲しく過去を振り返っているG.W. 最終日の夕暮れです。
何にせよ、学習した事を頭と体に染み込ませるためには、復習(と栄養補給と睡眠)が大事ですね。
「エビングハウスの忘却曲線」という単語の断片だけでも思い出しながら(忘却曲線の忘の字だけでも・・・)、適切なタイミングで振り返り復習する事が、記憶の定着には必要ですね。
あとは、独自の整理方法とかも良さそうです。
語呂で覚えるとか。人や事物に例えてみるとか。
今回の記事のように、拙いやり方でも良いのでとりあえずアウトプットしてみる事も、学習や記憶の定着には必要な事なのかも知れません。
ブログは以上となります。
やーぐまやー : 家に籠っている人
この記事が気に入ったらサポートをしてみませんか?