Azure Cognitive Search第2弾~RAGにおけるAzure Cognitive Searchを用いた文章ベクトル化の方法~

初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はRAGにおけるAzure Cognitive Searchを用いたベクトル化の方法について解説
RAGにおけるAzure Cognitive Searchの占める箇所
RAGにおけるAzure Cognitive Searchとは質問文と社内文章等をベクトル化して類似度検索を可能とする基盤を作ることでした。(下図参考↓)
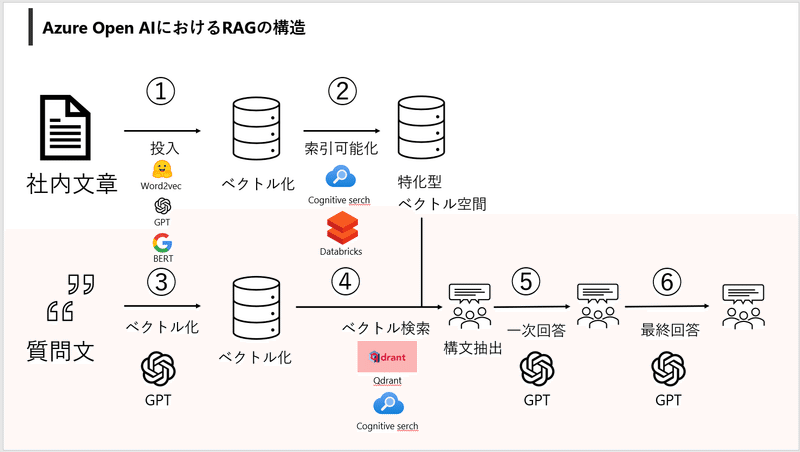
詳しくはAzure Open AIを使用したRAGの仕組みをご覧いただければと思います。
今回は具体的にAzure Cognitive Searchを用いたインデックス空間の作成までを詳しくお話ししようと思います。

Azure Cognitive Searchの仕組み
Cognitive Serachの仕組みは以下の手順となります。
データの用意:
ベクトル空間を構築するためのテキストデータを用意します。これは、Azure Cognitive Searchが検索対象とするデータセットです。
Azure Cognitive Searchの作成:
Azure Portalを使用して、Azure Cognitive Searchサービスを作成します。
サービスが作成されたら、データセットを管理するための「Index」を作成します。このIndexは、ベクトル空間の検索の基盤となります。
データのインデックス化:
作成したIndexにデータをインデックス化します。これにより、Azure Cognitive Searchがデータを検索可能な形式に変換されます。
インデックス化されたデータは、テキストフィールドや他の属性に分かれて格納されます。
ベクトル化:
テキストデータをベクトル空間にマッピングするための手法を選択します。これは、例えばWord2Vec、BERT、FastTextなどのアルゴリズムを使用して行われることがあります。
選択した手法に基づいて、各テキストデータをベクトルに変換します。
ベクトルの格納:
ベクトル化されたデータを元のデータと対応付け、Azure Cognitive SearchのIndexに格納します。
ベクトルは、検索時に使用され、類似度検索が行えるようになります。
検索クエリの発行:
Azure Cognitive Searchを使用して、検索クエリを発行します。検索クエリは、類似したベクトルを持つデータを検索するためのものです。
検索結果の取得:
発行した検索クエリに基づいて、類似したベクトルを持つデータの検索結果を取得します。これが、ベクトル空間上での検索結果となります。
1.データの用意
データを用意しましょう。ここでは参考に以下のファイルを読み込ませてみます。
2.Azure Cognitive Searchの作成
Azure Portalにサインイン:
Azure Portalにアクセスして、Azureアカウントにサインインします。
Azure Cognitive Searchサービスの作成:
ポータルの左上にある「リソースの作成」をクリックし、「Cognitive Search」を検索して、新しいAzure Cognitive Searchサービスを作成します。
3.データのインデックス化
新しいインデックスの作成:
サービスが作成されたら、そのサービスに移動し、「検索インデックス」を選択します。
「+ インデックスの追加」をクリックして新しいインデックスを作成します。
インデックスの設計には、テキストデータやフィールドのマッピング、検索可能な属性などを定義します。
データの投入:
インデックスが作成されたら、データ(検索対象として組み込みたい情報)をそのインデックスに投入します。これにより、検索可能なデータが用意されます。
データの前処理:
データをクリーニングし、必要に応じてトークン化や正規化を行います。これにより、検索の精度が向上します。
インデックスの設計:
インデックスの構造を設計します。これは、どのフィールドや属性を含めるか、どのデータ型を使用するかなどを決定するプロセスです。
ベクトルデータの投入:
ベクトルデータや検索対象のデータをデータベースや検索エンジンに投入します。
索引の作成:
データベースや検索エンジンは、指定されたフィールドや属性に対して索引を作成します。これにより、特定の検索対象が高速に見つかりやすくなります。
検索クエリの最適化:
検索クエリを最適化し、効率的にデータにアクセスできるように調整します。これには、適切なクエリの構造や検索条件の最適化が含まれます。
パフォーマンスのモニタリングと調整:
インデックス化されたデータの検索性能をモニタリングし、必要に応じて調整や最適化を行います。
4.ベクトル化
べクトル化の事前処理:
Azure Cognitive Searchに投入する前に、テキストデータをベクトル化するためのアルゴリズム(例: Word2Vec、BERT、FastTextなど)を使用してベクトル化を行います。
ベクトル化のアルゴリズムやモデルは通常、機械学習フレームワークやライブラリを使用して事前に学習されます。
ベクトルデータのAzure Cognitive Searchへの投入:
ベクトル化されたデータ(ベクトルデータ)をAzure Cognitive Searchに投入します。
投入されるデータは、テキストデータとそれに対応するベクトルデータを含む形式にします。
検索クエリの発行:
ベクトルデータがAzure Cognitive Searchに投入され、事前に設定されたインデックスを組み合わせて、検索クエリを発行してベクトルデータを検索します。
参考:ベクトル化を行うためのツール
Word2Vec:
Gensim: Pythonのライブラリで、Word2Vecアルゴリズムを実装しています。単語を密なベクトルに変換することができます。
spaCy: Pythonの自然言語処理ライブラリで、単語のベクトル表現を提供します。
BERT (Bidirectional Encoder Representations from Transformers):
Transformers ライブラリ: Hugging Faceが提供しているTransformersライブラリは、BERTなどのトランスフォーマーモデルを利用できます。これらは文全体をベクトルに変換するために使用されます。
FastText:
FastTextライブラリ: Facebookが提供しているFastTextは、単語や文章をベクトルに変換することができます。特に大規模なデータセットに対して効果的です。
これらのツールは、Pythonなどのプログラミング言語で使用できます。選択するツールは、データの性質やベクトル化の目的によって異なります。
5.ベクトルの格納
ベクトル化されたデータを元のデータと対応付け、Azure Cognitive SearchのIndexに格納します。
ベクトルは、検索時に使用され、類似度検索が行えるようになります。
6.検索クエリの発行
クエリの構築:
ユーザーまたはシステムが検索したい情報に基づいて検索クエリを構築します。クエリは検索対象や条件を指定するための文(テキスト)やパラメータの形式を取ります。
クエリの発行:
構築された検索クエリがデータベースや検索エンジンに送信されます。これは通常、HTTPリクエストを使用して行われます。
検索エンジンの処理:
データベースや検索エンジンは受け取った検索クエリを解析し、対応するデータを検索します。この際、索引やインデックスが効率的に利用され、検索速度が向上します。
検索結果の返却:
検索エンジンは検索結果を生成し、ユーザーまたはシステムに対して返却します。通常、検索結果はランキング付けされ、最も適合するものが先頭に表示されます。
結果の表示または利用:
ユーザーインターフェースやシステムが、検索結果を適切に表示または利用します。これによって、ユーザーは求めていた情報を取得できます。
具体的な検索クエリの構築方法や発行手順は、使用しているデータベースや検索エンジンの仕様により異なります。Azure Cognitive Searchなどのサービスでは、REST APIを介してクエリを発行し、JSON形式で検索結果を取得することが一般的です。
7.検索結果の取得
検索エンジンからのレスポンス取得:
クエリを発行した後、検索エンジンは検索結果として一連のドキュメントやレコードを含むレスポンスを生成します。これは通常、HTTPリクエストの応答として提供されます。
レスポンスの解析:
取得したレスポンスを解析して、検索結果の内容を理解します。結果は通常、JSON形式や他のデータフォーマットで提供され、それをプログラムで解釈することが一般的です。
検索結果の抽出:
解析したレスポンスから必要な情報や属性を抽出します。これによって、ユーザーが求める情報を特定することが可能です。
結果の表示または利用:
抽出した検索結果は、ユーザーインターフェースやアプリケーション内で表示されるか、特定の操作に利用されます。例えば、検索結果がウェブページとして表示されたり、プログラム内で処理されたりします。
最後に
いかがでしたでしょうか。
最後にもう一度まとめますと
Azure portalよりCognitive Searchの作成
社内文章等の事前に読み込ませたいファイルを用意
ファイルをword2vec,GPT,BERT等のモデルによりベクトル化
ベクトル化したデータをCognitive Searchへ格納
Cognitive Searchによる社内文章等のinputファイルのベクトル空間化
質問文をGPTによりベクトル化
Cognitive Search、Qdrantによる類似度検索による社内文章の抽出
GPTによる抽出文を元にした一次回答生成
GPTによる一次回答に基づく最終回答の生成
でした。
次回は1~3の社内文章を用意してベクトル化し、ベクトル空間とは実際のどんなものなのかを体感していただければと思います。
最後まで読んでいただきましてありがとうございました!
この記事が気に入ったらサポートをしてみませんか?