Pythonで不動産価格予測解析

今回は、東京都足立区の中古マンションの価格を過去データから学習する予測モデルを作り、未知のデータに対して物件の条件から価格を予測する一連の流れをpythonを使って実装しました。
■データ分析のワークフロー
1. 問題の定義:機械学習の教師あり学習を用い、東京都足立区の中古マンション価格を予測します。
2. 訓練およびテストデータの取得:国土交通省土地総合情報システム
(https://www.land.mlit.go.jp/webland/)から例として、東京都足立区(2010年第1四半期から2020年第3四半期まで)のデータを使用します。
3. データ項目(特徴量)の理解:Pandasを用い、データの特性を把握します。
4. データの整形:読み込めないデータの成型や欠損値、異常値の処理を行います。
5. 分析:回帰の様々なモデルの中から、線形回帰、リッジ回帰、ラッソ回帰、エラスティックネット回帰、ランダムフォレスト、ニューラルネットワークを使って、当てはまりの良いモデルを探して予測させます。
■具体的なコード記述部分
1. 問題の定義
今回はデータクレンジング処理と、回帰予測を行いますので、下記のような一般的な、numpy、pandasなどの処理用と、可視化用にmatplotlib、seaborn、回帰分析用に、LinearRegression、Ridge、Lasso、ElasticNet、RandomForestと全結合のディープラーニングのライブラリを使いました。それぞれの精度を比較して、一番良いモデルで予測する形とします。
必要なライブラリをインポート
import os
import re
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import sklearn
from sklearn.model_selection import train_test_split
#線形回帰分析用 from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.ensemble import RandomForestRegressor
#全結合ディープラーニング用
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation,Dense,Dropout,Input,BatchNormalization2. 訓練およびテストデータの取得
国土交通省のサイトからダウンロードしたデータはエンコードcp932となっていたので下記のように指定しました。
path_data = "13121_20101_20203data.csv"
df_data = pd.read_csv(path_data,encoding="cp932")3. データ項目(特徴量)の理解
Pandasを使って、どんなデータなのか?を特性を把握します。
df_data.columns #特徴量を見る。
df_data.sample(frac=0.01).head(10) #ランダムに1%のデータを抽出し、先頭から10件データを表示。出力結果は示しませんが、データは、下記の項目で構成されており、取引価格(総額)が目的変数となり、その他29項目が説明変数の候補(特徴量)となります。
#df_data.nunique() #Unique数を調べる。
#df_data['改装'].unique() #Uniqueの項目を見る
#df_data['種類'].unique() #Uniqueの項目を見る
#df_data['地域'].unique() #Uniqueの項目を見る
#df_data['取引価格(総額)'].describe() #販売価格の統計量の表示
#sns.distplot(df_data['取引価格(総額)']) #ヒストグラムの表示
#df_data.isnull().sum() #各項目に対し、欠損数を確認
#sns.boxplot(y=df_data['取引価格(総額)']) #外れ値の確認(一次元
#sns.jointplot('面積(㎡)', '取引価格(総額)', data=df_data) #外れ値の確認(二次元)
#df_data['最寄駅:距離(分)'] = df_data['最寄駅:距離(分)'].astype(float)
#df_data['面積(㎡)'] = df_data['面積(㎡)'].astype(float)
#df_data.dtypes
#df_data['取引時点'].unique() #Uniqueの項目を見る(1) No.、(2) 種類(宅地(土地と建物)', '宅地(土地)', '中古マンション等')、(3) 地域('住宅地', '商業地', '工業地', '宅地見込地')、(4) 市区町村コード、(5) 都道府県名、(6) 市区町村名、(7) 地区名、(8) 最寄駅:名称、(9) 最寄駅:距離(分)、(10) 取引価格(総額)、(11) 坪単価 、(12) 間取り、(13) 面積(㎡)、(14) 取引価格(㎡単価)、(15) 土地の形状、(16) 間口、(17) 延床面積(㎡)、(18) 建築年、(19) 建物の構造、(20) 用途、(21) 今後の利用目的、
(22) 前面道路:方位、(23) 前面道路:種類、(24) 前面道路:幅員(m)、(25) 都市計画、(26) 建ぺい率(%)、(27) 容積率(%)、(28) 取引時点、
(29) 改装、(30) 取引の事情等(私道を含む取引/nan/調停・競売等/調停・競売等、私道を含む取引/隣地の購入/その他事情有り/関係者間取引/隣地の購入、私道を含む取引/関係者間取引、私道を含む取引/隣地の購入、関係者間取引/古屋付き・取壊し前提/瑕疵有りの可能性/他の権利・負担付き)
4. データの整形
・上手く認識されない和歴を西暦に直す。
#nanとnone、空白の違いに注意。正規表現で探せなくなる。
#print(df_data['建築年'])
df=df_data['建築年'].fillna('')
kenchikunen_list=df.tolist()
for i in range(len(kenchikunen_list)):
if re.match('昭和元年', kenchikunen_list[i]):
kenchikunen_list[i] = 1926
elif re.match('昭和',kenchikunen_list[i]):
kenchikunen_list[i] = 1925 + int(re.sub(r'\D','',kenchikunen_list[i]))
elif re.match('平成元年', kenchikunen_list[i]):
kenchikunen_list[i] = 1989
elif re.match('平成',kenchikunen_list[i]):
kenchikunen_list[i] = 1988 + int(re.sub(r'\D','',kenchikunen_list[i]))
elif re.match('令和元年',kenchikunen_list[i]):
kenchikunen_list[i] = 2019
elif re.match('令和',kenchikunen_list[i]):
kenchikunen_list[i] = 2018 + int(re.sub(r'\D','',kenchikunen_list[i]))
elif re.match('戦前',kenchikunen_list[i]):
kenchikunen_list[i] = 1945
else:
continue
df_temp = pd.DataFrame({'建築年(西暦)':kenchikunen_list})
df_data2 = pd.concat([df_data,df_temp],axis=1)
df_data2['建築年(西暦)'].replace('', np.nan, inplace=True)
df_data2['建築年(西暦)'] = df_data2['建築年(西暦)'].astype(float)
df_data2.info()・6千万円以下の物件に限定。
df_data_normal = df_data2.loc[df_data['取引価格(総額)'] < 60000000]
#sns.boxplot(y=df_data_normal['取引価格(総額)']) #外れ値の確認(一次元)
#sns.jointplot('面積(㎡)', '取引価格(総額)', data=df_data_normal) #外れ値の確認(二次元)億円以下の物件で探す。⇒60000000以下の物件を整理「最寄駅:距離(分)」⇒30分?60分、2H?、1H?1H30という文字列が入っているのでfloatで30へ。「面積(㎡)」⇒2000㎡以上という文字列が入っているので、floatで2000へ。
・外れ値の可視化(seaborn)を用て切るデータを決める。
sns.boxplot(y=df_data_normal['取引価格(総額)']) #外れ値の確認(一次元)
sns.jointplot('面積(㎡)', '取引価格(総額)', data=df_data_normal) #外れ値の確認(二次元)二次元のジョイントプロット
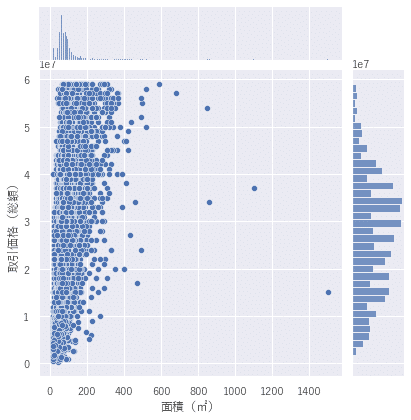
sns.set(font='Yu Gothic')
cols = ['取引価格(総額)', '面積(㎡)', '最寄駅:距離(分)','建築年(西暦)']
sns.pairplot(df_data_normal[cols], height = 2.5)
図を見ながら、外れ値を除外するようにデータの成型を行いました。
中古マンション等の項目を残し、6000万円以下、建築年を1950年以降とし、面積120m^2以内、最寄り駅からの距離(時間)30分以内としました。
#中古マンション等のみ抽出
df_data_normal = df_data_normal[df_data_normal['種類'] == '中古マンション等']
#面積(㎡)⇒120以内を使う, 最寄駅:距離(分)⇒30以内を使う,建築年(西暦) ⇒1950年以上を使う
df_data_normal = df_data_normal.loc[df_data_normal['面積(㎡)'] <=120]
df_data_normal = df_data_normal.loc[df_data_normal['最寄駅:距離(分)'] <=30]
df_data_normal = df_data_normal.loc[df_data_normal['建築年(西暦)'] >= 1950]散布図で確認
sns.set(font='Yu Gothic')
cols = ['取引価格(総額)', '面積(㎡)', '最寄駅:距離(分)','建築年(西暦)']
sns.pairplot(df_data_normal[cols], height = 2.5)
ヒートマップで確認
k = 12
cols = corrmat.nlargest(k, '取引価格(総額)')['取引価格(総額)'].index
cm = np.corrcoef(df_data_normal[cols].values.T) # .T(転置行列)を行う理由は、corrcoefで相関を算出する際に、各カラムの値を行毎にまとめなければならない為
sns.set(font_scale=1.0) # ヒートマップのフォントサイズを指定
sns.set(font='Yu Gothic')
# 算出した相関データをヒートマップで表示
sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)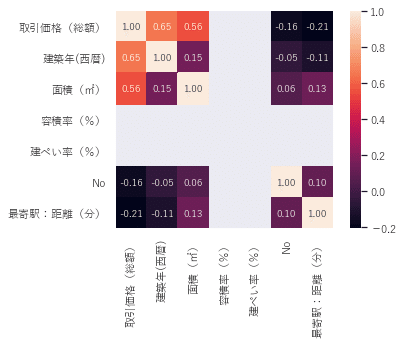
ここまでで、分析する準備が整いました。
5. 分析
単回帰分析
各特徴量で取引価格(総額)の相関線を引いて行き、イメージと合う傾きとなることを確認しました。(実際は、Xの項目を各特長量で置き換えました。)
X = df_data_normal[["最寄駅:距離(分)"]].values
y = df_data_normal["取引価格(総額)"].values
model = LinearRegression() # 線形回帰
model.fit(X,y) # 学習
# 回帰係数を出力
print('傾き:{0}'.format(model.coef_[0]))
# y切片(直線とy軸との交点)を出力
print('y切片: {0}'.format(model.intercept_))
plt.scatter(X,y)
plt.plot(X,model.predict(X),color='red')作図
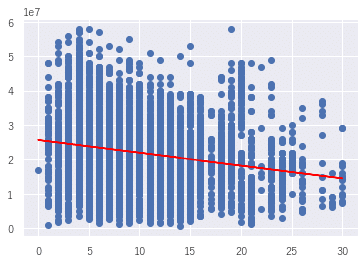
横軸が最寄り駅までの時間(分)、縦軸が取引価格(総額)。駅まで近い方が価格が高くなることを確認しました。その他、面積は広い方、築年数は新しい方が価格が高くなっており、イメージと合います。
重回帰分析
取引価格(総額)と相関の高い面積(㎡)と最寄駅:距離(分)、建築年(西暦)を説明変数に使用しました。比較したモデルは、線形回帰、リッジ回帰、ラッソ回帰、エラスティックネット回帰、ランダムフォレスト、ディープニューラルネットワークを使って、二乗平均平方根誤差を比較し、値が小さくなるモデルを良いモデルとしました。
# 取引価格(総額)と相関の高い面積(㎡)と最寄駅:距離(分)、建築年(西暦)を説明変数に使用
X = df_data_normal[["面積(㎡)", "最寄駅:距離(分)","建築年(西暦)"]].values
y = df_data_normal["取引価格(総額)"].values
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2 , random_state=42)
best_model = ""
pred_model = []
# 線形回帰
model = LinearRegression() # 線形回帰モデル
model.fit(train_X,train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("線形RMSE : %.2f" % (mse** 0.5))
min_mse = mse
best_model = "線形"
pred_model = pred_model.append(model)
# リッジ回帰
model = Ridge() # リッジ回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("リッジRMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "リッジ"
pred_model = model
# ラッソ回帰
model = Lasso() # ラッソ回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("ラッソRMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "ラッソ"
pred_model = model
# ElasticNet回帰
model = ElasticNet(l1_ratio=0.5) # エラスティックネット回帰モデル
model.fit(train_X, train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("エラスティックネットRMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "エラスティックネット"
pred_model = model
# RandomForest回帰
model = RandomForestRegressor(100) # ランダムフォレスト回帰モデル
model.fit(train_X,train_y) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("ランダムフォレストRMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "ランダムフォレスト回帰"
pred_model = model
# DNN回帰
model = Sequential()
model.add(Dense(32, input_dim=3, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
history = model.fit(train_X, train_y, epochs=40, batch_size=16, verbose=1, validation_data=(test_X, test_y) ) # 学習
pred_y = model.predict(test_X) # 予測
mse= mean_squared_error(test_y, pred_y)# 評価
print("ディープニューラルネットRMSE : %.2f" % (mse** 0.5))
if min_mse > mse:
min_mse = mse
best_model = "ディープニューラルネット回帰"
pred_model = model
print("ベストモデル:{}".format(best_model)) 出力結果
線形RMSE : 5821435.70
リッジRMSE : 5821435.63
ラッソRMSE : 5821435.70
エラスティックネットRMSE : 5821423.31
ランダムフォレストRMSE : 5494685.99 ディープニューラルネットRMSE : 9962509.90
ベストモデル:RandomForest回帰
一番精度の良いモデルがランダムフォレストということが分かりました。
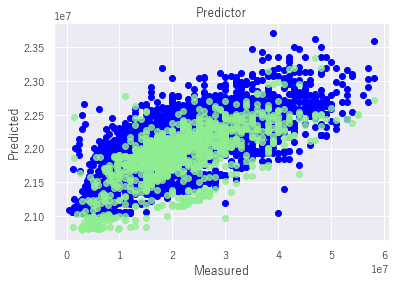
作図
plt.figure()
plt.scatter(train_y,model.predict(train_X),label='Train',c='blue')
plt.scatter(test_y,a_pred_y,c='lightgreen',label='Test',alpha=0.8)
plt.title('Predictor')
plt.xlabel('Measured')
plt.ylabel('Predicted')
plt.show()青が教師データ、緑がテストデータを表しています。X軸が観測値、Y軸が予測値を表しています。教師データ、テストデータ共にある程度良い相関を持っていることが分かります。
6.結論
いろいろな回帰モデルを比較して中古マンションの価格を予測するモデルを作成しました。今回、線形回帰、リッジ回帰、ラッソ回帰、エラスティックネット回帰、ランダムフォレスト、ニューラルネットワークを二乗平均平方誤差(RMSE)を比較した結果、ランダムフォレストが最も当てはまりの良いモデルになりました。パラメータ設定については、あまり深堀りせず、一連の流れを通すことに注力しました。ニューラルネットワークで、回帰の精度があまり上がらないというのは、他の方の記事等でもあるようです。今後、他のデータにも今回の手法を適用しながら、精度を上げていきたいと思います。XGBoost、LightGBMなどの手法を加えて、特徴量エンジニアリングやディープラーニング、パラメータチューニングなどの知見を深めて行きたい。
この記事が気に入ったらサポートをしてみませんか?