高速なランキング情報取得 API のために

ミリオンのプロデューサーのみなさん、周年イベントおつかれさまです!
matsurihi.me では、Princess においてミリシタのイベントランキングの情報(各順位の pt の経過の情報)を配信しています。
この API は Fantasia で利用しているほか、みなさんが各自で利用できるようになっています。

ランキングの情報は時刻×順位の情報ですので O(nm) で増えていきます。
この大量のデータから高速に特定の情報を返すためにはかなりの工夫が必要でした。
このお話を、特に厳しいアイドル別ランキングに絞って記事にします。
matsurihi.me における状況
ミリシタのアイドル別ランキングは、
52 人の各アイドルについて
1000 位までのランキングが
5 分おきに
13 日間
配信されます。matsurihi.me ではこのすべてのランキング情報を、プロデューサーさんの ID を含めて MariaDB に保存しています。
したがって、1 イベントあたり 52×1000×12×24×13=約 2 億行のレコードが挿入されることになります。
Auto increment の ID が 64bit、イベント ID が 32bit、アイドル ID が 32bit、時刻が 64bit、順位が 32bit、ポイントが 64bit、ユーザ ID が 128bit とすると、1 行 52 バイトになるので、(インデックスを含まない)データ自体だけで 1 イベントあたり 10GB に上ります。

今回のイベントが 6 回目ですので、すべてで 10 億行、50GB を超えるデータが 1 つのテーブルに乗っています。
この 10 億行の中から、特定のイベント・アイドル・順位におけるランキングの推移を返却する必要があります。
特定のイベント・アイドル・順位に絞っても 1 リクエストで 3500 行以上が返るため、単純にレスポンスを返すだけでもかなり苦しいものになります。
これを、個人が借りられる程度のスペックの DB サーバで実現する必要がありました。
matsurihi.me では、特定のアイドル・順位を取得するだけでなく、現在の全アイドルのボーダー情報を一度に取得する機能もあります。
この機能はさらにしんどく、この API の実現も同時に叶える必要があります。
データベース設計
Summary table
matsurihi.me のデータベースでは、ログのテーブルとは別に、サマリー情報のテーブルを持っています。
サマリーのテーブルは、イベント ID、集計時刻、集計時刻の ID、ランキング対象者数の情報が格納されています。
ログのテーブルには集計時刻を直接書かず、集計時刻の ID を書く仕組みになっています。
取得するときには、この 2 つを JOIN して返すことになっています。

集計時刻の ID は、集計時刻を GMT+9 で YYmmddHHMM でフォーマットしたもので、かなり昔にミリシタの内部で用いられていたものです(現在はミリシタでは使われていません)。
サマリーのテーブルの主キーの ID をそのまま参照せずに集計時刻の ID を使っているのはそういった歴史的な背景があるからなのですが、実際振り返ってみるともうちょっとマシな選択肢はあったのではないかと思ってしまいますね……。
集計時刻の ID から集計時刻を復元することは推奨されず、実際には集計時刻自体は JOIN して取ってくる必要があります。
なお、matsurihi.me では全体として集計時刻の ID は時刻に対して単調増加していることを前提としてシステムを組んでいます。そのため、単純に主キーに置き換えることはできず、今もなおこの不思議なスキーマは変えられずにいます。
パーティショニング
Partitioning は、複数のテーブルにデータを分割しつつ、全体をあたかも 1 つのテーブルとして扱えるようにする機能です。
いろいろな RDB にいろいろな形で実装されています。
matsurihi.me では、1 周年イベントが終了した時点でもはや耐えられず、その当時から partitioning を使っていました。
Partitioning は、「このイベント、このアイドルはこのパーティションにする」といった手動で分割する方法と、「これをキーにして適当に分けてください」といったハッシュ値で分割する方法があります。
前者のほうが確実に分割できますが、いちいちマイグレーションする必要がありかなり運用が面倒です。
そのため、matsurihi.me では後者の方法を選び、テーブル数をかなり増やして対応しています。
MySQL 系の partitioning は、分割するときのキーには primary key しか使えないという大変凶悪な制約があります(凶悪といっても理にはかなっているのですが)。
仕方がないので、auto increment の ID、イベント ID、アイドル ID を複合主キーにするという大変厳しい運用をとっています。
PostgreSQL ではもう少し柔軟なことができるのですが、やむを得ません。
Partitioning は、所詮定数倍の改善しか得られませんしデメリットも少なくないので、実際の運用ではかなり注意して検討する必要があります。
インデックス
ここまで記事をお読みになった聡明な方は「インデックスを上手に張ればよいのでは?」という発想になるでしょう。
データ上では、イベント ID → アイドル ID → 順位 → 時刻 ID の複合ユニークインデックスが張ってあります。
こうすることで、なるべくパフォーマンスが高くランキング情報を取得することができるはずです。
しかし、パーティション分割をしてインデックスを張って解決するのであれば、この記事はここで終わるはずなのです。
余談ですが、ミリシタには複数の順位に同じプロデューサーさんが表示されるというバグが昔から変わらずずっとあります。
ユーザ ID を含めた複合ユニークインデックスもあるのですが、このバグと衝突してしまうため、挿入前に全データをチェックしてバグが起きたらユーザ ID を NULL にするという大変厳しい対策を取る必要があります。
対策 1: MariaDB のチューニング
まずはメモリを増やしましょう。
InnoDB というデータベースエンジンでは、buffer pool というメモリ上の領域にテーブルをコピーして乗せるという機能が備わっていて、基本的にデータベースを読むアクセスはこれを利用しています。
これによって、いちいち HDD や SSD にアクセスせずとも高速にデータを取得できます。
アイドル別ランキングでは、インデックスを含めると 1 イベントあたり約 20GB 消費することが経験的にわかっています。
したがって、buffer pool に 20GB 確保すれば(希望的観測で)全アイドルのテーブルが buffer pool に乗ってくれることになります。
Buffer pool のサイズはメモリ上限まで使えるわけではないので、余裕を見積って 32GB 以上のメモリがあるマシンを利用することにしています。
今回のイベントでは 48GB RAM のマシンを借りました。大変ですね。
なお buffer pool の大きさは実メモリの 2/3〜3/4 くらいに設定するとちょうどいいようです。
対策 2: インデックスヒント
インデックスをいくら適切に設定したとしても、それが使われるとは限りません。
MySQL 系では、クエリを叩くと、まずテーブルの大きさなどを見積って実行計画を立て、その計画に従って実行します。
インデックスを使わないほうが速いと思った場合にはインデックスを使いません。
そして、この状況で pt 推移を取得するとインデックスが使われないのです。
インデックスを使ったほうが速いはずなのに。
実は MySQL 系の RDB にはインデックスヒントとよばれる機能が備わっていて、強制的にインデックスを使わせることができます。
これによって、やっとインデックスを使わせることができるようになり、インデックスを使うなりの速度で取得できるようになりました。

実行計画をいじらないと解決しないのはかなり腑に落ちませんが、こういう機能が備わっている意味を考えれば、仕方のない実装かなと思います。
対策 3: データを間引く
matsurihi.me では、 アイドル別ランキングのデータは 30 分ごとに間引いて返すことにしていました。
そうすればデータ自体は 1/6 になるわけですからかなりラクになります。
Princess は 2 回大規模アップデートしており、現在 version 3 です。
Version 2 までは間引いたデータのみ取得できるようになっていました。これは、とてもではないがすべてのデータを返す能力がなかったためです。
実際、現在も Fantasia では間引いたデータを使っています。
様々な闘いを経て間引かないデータも返せるようになったため、version 3 では間引かずに返す API も実装しています。
余談ですが、イベント終了間際は 5 分ごとのデータがないと話にならないため、Fantasia 上では終了間際のみすべてのデータが含まれるようになっています。
対策 4: キャッシュ(Web サーバ編)
そろそろ泥臭い話題が始まります。
単純にすべてのリクエストに対して逐一データベースにアクセスしていると、matsurihi.me のアクセス数をさばくことができません。
そのため、Redis 上にログをキャッシュしておき、これを利用してレスポンスを返す機能が付いています。
これをどう実装するか? という話になります。
バックエンドからキャッシュを操作するというのも 1 つの手です。
ただ、Web サーバから見られる DB はリードレプリカの可能性があるため、ランキング情報更新と DB の内容の更新は一致しない可能性があり、キャッシュの purge を一緒に行うというのは難しいです。
どのランキング情報が必要になるかもわからないため、キャッシュをランキング取得完了時に更新するというのも非現実的です。
バックエンドとフロントエンドの両者がアクセスする部分を増やすのも、なかなか好ましくありません。
したがって、この方法ではちょっと厳しいでしょう。
ナイーブな実装(Princess version 2)
Redis に、ログそのものをドっと格納しておき、それをそのまま返すという方法が有り得ます。
ナイーブで実装も簡単です。
キャッシュの purge は、本来あるはずのデータがないときにすればよいわけです。
Princess version 2 では、たとえば 17:03 になっても 17:00 のデータがないならキャッシュを purge する、という仕組みになっていました。

この方法の問題点としては、以下のようなものがあります。
ランキング更新時にはすべてのデータを再度取得しなければならない
定刻(図中でたとえば 16:30)からデータが追加されるまでの間はキャッシュが使えない
ランキング更新予想時刻をハードコーディングする必要がある
どの問題についてもかなり深刻です。工夫すれば少し解消しますが、完全な解決とはいきません。
Sorted set による実装(Princess version 3)
Version 3 では、Redis の sorted set を使ってキャッシュを実装しています。
Sorted set は、データにスコアを紐付けて、このスコア順にデータを格納できるというものです。
内部的には単なる二分木かと思いきやスキップリストになっているらしく、とりあえずスコアを指定すれば O(log N) くらいで取得できます。
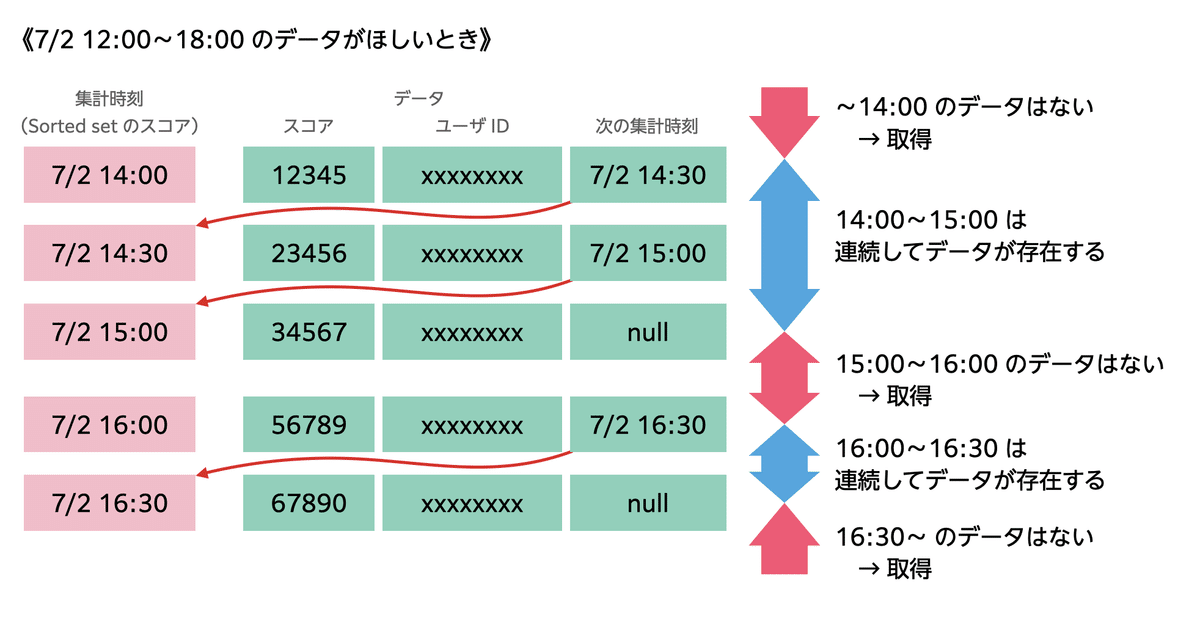
matsurihi.me では、このスコアに集計時刻の ID を利用し、データにランキング情報を格納するという方法でキャッシュをしています。
部分的なキャッシュを実現するため、次の集計時刻 ID を各データに保存しておき、それを利用して連結リスト的にデータが連続しているかを判定できるようになっています。

データを取得するときには、所望の区間の集計時刻(=スコア)のデータを取ってくればよいだけです。
各データを見ていって、もし次の集計時刻 ID が入っていなければ、あるいはその ID のデータがなければ、間のデータが抜けているということになります。そのときには、その部分だけデータベースにアクセスして取得すればよいのです。
API のリクエスト時には、次の手順でデータを返しています。
サマリーのテーブルから集計時刻の一覧を取得する
集計時刻の最小値と最大値を得る
最小値と最大値の間のキャッシュ上のデータを取得する
キャッシュのデータで不連続な部分の一覧を生成する
その一覧から MySQL の WHERE 文を生成する
データベースから不足している分を取得する
取得した分からキャッシュを追加し、「次の集計時刻」のデータを必要に応じて更新する
整形して返却する
matsurihi.me では複数の順位の情報を一度に取れる仕様になっているのですが、このときには複数の順位にわたってキャッシュを取得して順位ごとに MySQL の条件文を生成したのち OR で結合したりなどして 1 つのクエリにまとめています。
複数のアイドルのデータを一気に取得する際も、同様に強引に 1 クエリにまとめて取得しています。
データベースへのアクセスは少なければ少ないほど、またクエリは簡単であればあるほどよいものです。
手順 5 では、一度に必要なデータをすべて取得できるよう、OR と AND と IN を駆使しなるべく最適化したクエリを生成しています。
この方法によって、version 2 のキャッシュでの問題点は解決できました。
特定の時刻以降のデータを取得したり、最新のデータのみ取得したりなどの柔軟な操作も軽快に簡単に可能になりました。
欠点としては、次の集計時刻分のデータが増えてしまう点、キャッシュが複雑で扱いにくい点がありますが、これらのデメリットはないに等しいほど強力な方法です。
対策 5: キャッシュ(CDN 編)
Web サーバの通信において、意外とネックになるのは通信そのものにかかる時間です。
イベントのランキング情報は、同じようなクエリを様々な人が叩いたり、同じ人が最新の情報を取得しようと何度も同じクエリを叩いたりなど、同じものが叩かれるケースがほとんどです。
そうした際に、いちいちデータを返さず、いい感じに CDN にキャッシュさせることで通信量の削減と通信時間の短縮を図ろうと考えました。
こうすれば、サーバ側の負担が減るだけでなくユーザとしても通信量が削減できるため、両者ともに幸せです。
実装としては簡単で、次のようになっています。
サマリーのテーブルを確認して、対象となる集計時刻の一覧を取得する
クエリのパラメータと集計時刻の一覧から ETag を生成する
ETag と If-None-Match を照らし合わせて一致したら 304 Not Modified を返す
そうでなければ普通に処理して ETag 付きで返す
これによって、CDN でクエリの結果をキャッシュできるようになりました。
この実装は、Princess v3 の API v2 のみに実装されています。
まとめ
高速なアイドル別ランキングのランキング情報取得 API の実現のため、matsurihi.me の工夫を紹介しました。
かつては Fantasia でアイドル別のランキングを表示しようとすると 10 秒くらいかかっていたのですが、キャッシュがあれば 250 ミリ秒、キャッシュがなくても 1 秒以内にデータを返せるようになりました。
実はまだサマリーのテーブルに必ずアクセスするという状況になっていて、これがボトルネックになっています。これ以上のまともな最適化は今のところ思いつかないのですが、これからもわんだほー! なサービスを提供できるように勉強していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?