
エンジニアが生成AIでガチ漫画を描いてみた話。

結論
まず結論から申し上げると、生成AIでのマンガ制作はめちゃくちゃ楽しかったです。そして、生成AI×漫画に非常に可能性を感じました。
生成AIがスキルや脳内イメージを超えたアウトプットを出すためか、作り手でありながら、読み手の感動も味わえるところが制作体験を底上げしていました。
生成AIでの漫画制作の強みは3つ。制作時間の半減と高品質な作画、それと作風が人に依存しない点です。3つ目の属人性がない強みは今まで不可能なレベルでのタスクの細分化と人海戦術を可能にするので非常に画期的だと考えています。
制作した漫画
全編生成AI作画のカラー漫画完成しました!!
— 比留間 大地 Daichi Hiruma✒️AI漫画 (@maruhi_dd) January 2, 2024
死んだ人がアップロードされる天国クラウドサービスで、人生を取り戻そうと奮闘する少年少女の甘酸っぱい物語です。
(1/5)#漫画が読めるハッシュタグ pic.twitter.com/jnBqspwccQ
https://rookie.shonenjump.com/series/EmTZ65sYoHs/EmTZ65sYoH4
制作フロー
一般的な漫画制作フローと同じものを採用しました。
アイデア出し ☚ 生成AI
プロット
ネーム
作画(コマ割り・セリフ)
作画(人物・背景)☚ 生成AI
今回生成AIを活用したのはアイデア出しと一番ウェイトが大きい「作画(人物・背景)」です。それ以外の工程は人力で作業しました。
環境
GPU:GeForce RTX4090
CPU:Intel Core i7
OS:Windows11
アイデア出し
アイデア出しはchatgpt4を使用して、SFで斬新なものを出力してもらいました。出てきたアイデアのうち好みなものを肉付けして採用しました。
天国クラウドサービス
作画(人物・背景)
細かいテクニカルな話は後述しますが、使用したソフトやライブラリは以下の通りです。画像生成や漫画制作では一般的に使われるものを使用しています。画像生成はcontrolnetが使えないと論外ですね。
Stable diffusion (Web UI)
最も自由度が高い画像生成AI。
メインの生成 / 修正に使用。
ChatGPT4 DALL-E3
ポーズや構図の生成に使用。
話し言葉で生成できて一番精度高い。
Clip Studio PAINT EX
漫画制作で最もよく使われるペイントソフト
e.t.c.
midjourney v6
comfyUI
krita(リアルタイムお絵描き生成plugin)
理想は、kritaのリアルタイムお絵描き生成で完結したかったのですが、自由度低くて挫折しました。機能が画像生成でも漫画制作でも中途半端だったのと、言うほどリアルタイム性に価値がなかったです。リアルタイムに60点のクオリティ出されても使えないんですよね、、
リアルタイム60点 << 1分かけて90点
制作時間
17pの漫画で80時間ほどかかりました。半分くらいの時間で創る予定でしたが、思ったより画像生成に時間がかかってしまいました。こだわり始めると1コマで4時間溶けます(笑)
プロット 4h
アイデア出し 1h
ネーム 4h
作画(コマ割り・セリフ) 3h
作画(人物・背景) 70h
1p平均 4h
1コマ平均 1h
最終確認 / 出力 1h
1pあたりネームから作画までで5時間くらいかかっています。
一人での人力作業の場合、デジタルでも通常10hくらいかかると言われているので、半分の時間でより高いクオリティを出せていますね。
生成ベストプラクティス
マンガは一枚絵と違ってコンテクスト(文脈)が強いので、狙った構図やポーズ、キャラ、表情を出力するコントロール技術が特に重要です。試行錯誤を重ねてたどり着いたベストプラクティスをここでは紹介します。なおstable diffusionやcontrolnetなどを使用しますが、その辺りの技術は経験がある前提で進めます。
全体の流れ
構図やポーズの制御「Controlnet Openpose」
領域ごとのプロンプト指定「Latent couple」
サイズ拡張と調整「Poor man's outpainting」
修正「Controlnet Inpaint」
出るまでガチャ
他にも色々と使いますが、メインは上記4つの機能です。
それぞれブレイクダウンしていきます。
1.構図やポーズの制御「Controlnet Openpose」
構図やポーズの制御はcannyやscribbleもありますが、結論一番使い勝手が良くて、成功率高いのはopenposeです。
https://huggingface.co/lllyasviel/sd-controlnet-openpose

openposeを使用した一番効率的だったワークフローを紹介します。
Controlnet Openposeに入力できる画像の用意。ポーズ以外いらないので人物や服装、背景は何でもよい。
ブラウザ検索
なければ、ChatGPT DALL-E3で画像生成
「PoseMyArt」でポーズを作成するのもあり
複雑すぎて無理なら自分で描いて「Controlnet scribble」で制御(そもそもそんなカット採用するべきじゃないけど)
人外や特殊なオブジェクトの場合はDALL-E3 + canny制御が良い
キャラを中心に画像の整形
可能な限り正方形に近づけて、キャラを大きく映してください。形が正方形から離れていたり、キャラが小さいとポーズの制御がうまくできません。縦横比やサイズはあとで調整可能です。
画像を入力してPreviewでOpenposeのposeデータを取得
必要に応じて、「sd-openpose-editor」などで編集する。
次のステップへ
ロングショット(遠景)を作りたい場合でも、
キャラが全身に収まるような切り方で生成をしてから、outpaintingでサイズを拡張した方が生成時間は短くなります。




k2.領域ごとのプロンプト指定「Latent couple」
1キャラの場合は使わなくても良いですが、2キャラ以上になると必須の工程です。領域ごとにプロンプトを入力可能になり、キャラの特徴が融合することが少なくなります。
https://github.com/miZyind/sd-webui-latent-couple
領域ごとに違う色でペイントして分割します。指定する領域はキャラが囲えれば問題ないです。
ペイントの場合は日本語の解説記事がないので簡単に解説します。
1)「Create blank canvas」で白い背景を作成。
2)領域ごとに、色を分けてペイント。
3)「I'v finished my sketch」で領域ごとにプロンプトを入力可能にする。
4)プロンプトとalphaなどを調整して「Prompt Info Update」でプロンプトに入力される。
経験上、4分割以上はうまくいかないので3分割までに抑えるべきです。
ここまで出来たら一旦生成します。キャラのポーズと構図、光源や雰囲気が合っていれば、細かいキャラの特徴や背景などは修正できるので妥協して次に進みましょう。
生成サイズは512 x 512にhires.fixで2倍にして、1024 x 1024がおすすめ。



3.サイズ拡張と調整「Poor man's outpainting」
inpaint修正前にサイズは修正した方が手戻りが少なく済みます。outpaintingでサイズの拡張をします。詳しい使い方は以下の記事がおすすめ。
拡張された背景が微妙でも、inpaintで修正できるので色や雰囲気が合っていたら妥協して次のステップに進みましょう。
何とかなる例 ↓


4.修正「Controlnet Inpaint」
みんな大好きinpaint(修正)の時間がやってまいりました。品質保証の大トリです。妥協のツケが回ってきたとも言えます(笑)
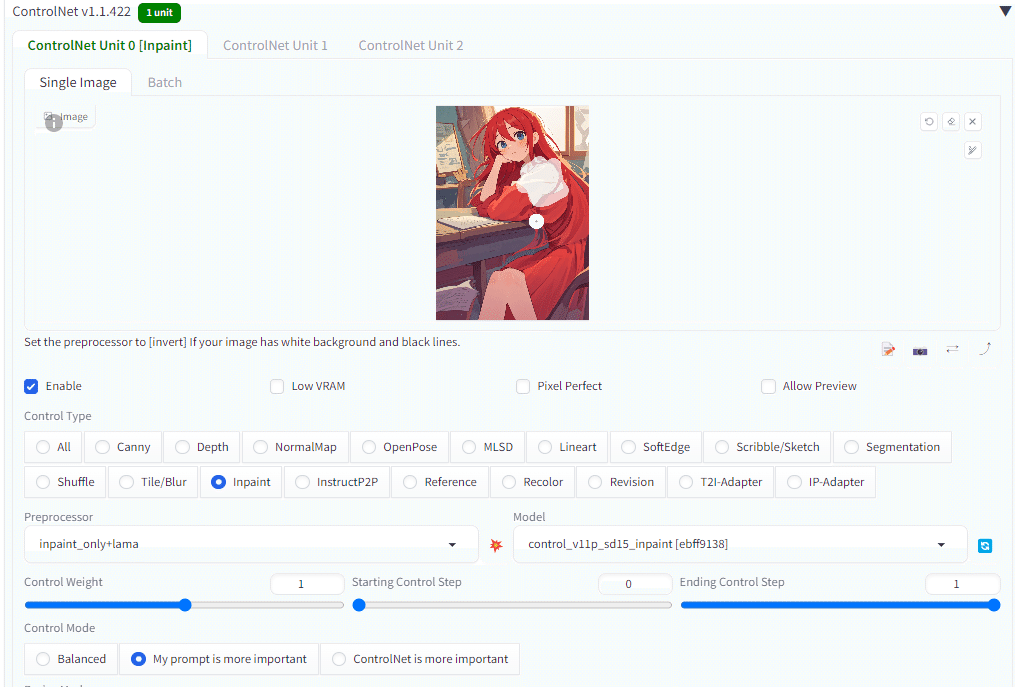
img2imgにもinpaintがありますが、controlnetのinpaintの方が精度が高いのでおすすめです。(mask blurや選択範囲の反転など細かいことしたい場合は、仕方なく、img2imgのinpaintを使用します。)
inpaint only+lama
基本これだけ使っていればよい
inpaint only
破壊的な変更をしたいときに使うと良かったりする。
inpaint global harmonious
全体をリペイントしてしまうので使うことはない。
control modeは「my prompt is more important」の方がうまく修正できます。
修正箇所が小さい場合は元々のプロンプトは全削除で修正後のプロンプトを入れると良いです。修正箇所が大きい場合は、元のプロンプトを残しつつ、修正キーワードを強調すると成功率が上がります。また、大きい修正箇所は小さく分けた方が結果的に生成時間は短くなります。
inpaint後、周囲が崩れることが多いので、そういうときはcontrolnet tile/blur+cannyで全体を馴染ませると綺麗に仕上がります。img2imgのdenoise strengthを0.4にして、canny強さ0.6で制御しても上手くいきます。
修正例1)人を生やす
真後ろのキャラを出すのが難しく、2キャラ+背景同時だと成功率が低すぎたので先に真後ろポーズのキャラ+背景を生成して後からほかのキャラを生やしました。



教室の狭さはコマで隠せるのでそのまま使う。
修正例2)背景をごっそり変える。
拡張してダメになった背景を修正。



修正例3)LoRAで表情を変える。
泣き表情Loraを使用すると、画風が変わってしまう問題点があったので、LoRAなしで生成して、inpaintでLoRAによる表情付けすることで画風の変化を限定的にしました。


修正例4)大人数を修正する。
5人家族の生成で、latent coupleの領域選択だと4領域以上になりガチャ地獄になりそうだったのでまずは全員同じキャラで出力してあとからinpaintで修正しました。


修正例5)画像を合成して馴染ませる
線香花火という特殊なオブジェクトがなかなか出ずに困っていたので、クリスタで合成して、全体を馴染ませました。




細かい破綻は妥協(笑)
5.出るまでガチャ
妥協は必要です。構図を変えたり、コマを分割したり、セリフやコマの外で隠したりして対応することで本当に重要なシーンや要素にだけ時間を使うことができるようになります。漫画は前後のコマや話の流れというコンテクストが強い分、細かい絵の破綻は気にならないことが多いのである意味生成AIと相性が良いとも言えます。

構図と生成時間
同じサイズの生成でもコマの内容によって生成する時間や難易度は大きく変わります。例えば、1キャラ顔アップは10分で出ますが、遠景2キャラは2時間かかるというように、出力したい内容で相当分散が大きいです。
生成時間表
1キャラ 顔アップ 10m
表情が重要なシーンだと 1h
背景のみ 10m
1キャラ 全身 背景あり 20m
1キャラ 遠景 30m
2キャラ 肩ショット 1h
2キャラ 遠景 1h30-3h
構図や背景重視(=誰がどこにいるか?) 1h30m
キャラのポージング重視(=誰がどこで何をしているか?) 2h30m
絡みがあるとさらに難化 3h
3キャラ 遠景 3h~
また生成したい主体の種類によっても難易度は変わります。
モブ人物(特徴どうでもよい)の場合は簡単になる。
オブジェクト(例:ケーキ、ボール)の場合は、あまり変わらない。
人外(例:ロボット)の場合、結構難しくなる。
ほかにも初回の生成は制約少ないから早いけど、同じものを次も出そうとすると生成により時間がかかるというのもあります。
キャラデザはできる限りわかりやすくシンプルな方が良いですね。人外キャラも出来るだけ避けるべきです。
生成AI×マンガの展望
筆者自身は本職はエンジニアで、漫画は趣味で何度か描いたことがあるレベル感ではありますが、生成AIを使用して漫画制作に取り組んだ中で感じた生成AIの強みを3つ紹介いたします。
1.半分以下の制作時間
一般的には1pあたり10時間程度かかる作画が半分の5時間以内に収まる効率性は特筆すべき強みです。また今回の制作時間は初めての生成AIでの漫画制作ということもあり、かなり試行錯誤をしてノウハウを構築しました。その分を差っ引けば今後は4分の1以下での制作も可能ではないかと推察します。
2.高品質なアウトプット
生成AIの指数的な進化っぷりを見ればわかるように、人力だと本来一部の上位層しか出せないような高品質なアウトプットが素人にも出せます。これは全体的なボトムアップなので、プロデュース力の強い本職の方が利用すればまさに鬼に金棒となるでしょう(筆者の本職のエンジニア業は今そのフェーズ)。作風をプライベートでAIに学習させることも可能なので、2024年内にプロも作風を変えることなくスムーズに移行できるようになると考えています。
3.作風の人依存がない
作風がAIモデルに内包されて、誰でも同じ絵を作ることができる点が筆者が最も重要視している強みです。つまり、今まで不可能だった人数での人海戦術が可能になるのです。シーン単位もっと言えばコマ単位でのタスクの分割が可能なので、キャラ担当の漫画家が進捗のボトムネックになることもなくなります。自分の作風を学習させたAIモデルをAPIで提供するサービスが今後できれば、極論見ず知らずの人に1コマだけ外注することも可能になるのです。また漫画の習得期間が数年単位なのに比べると、生成AIの学習は1週間程度と恐ろしく学習コストが低い点も大きな強みです。デメリットはGPUのコストが高いことですね(笑)
さらなる効率化を求めて
script2manga(脚本 → 漫画)を目指す。
制作フローがある程度確立されたので次はどこまで効率化できるか?効率化のために何が必要かという観点で理想の制作フローを考えていきます。
コマ割り状態からの理想的な制作フロー
「コマを指定してポチポチ選択したら完成」が理想です。さらに、修正も欠かせないのでそれも込みでフローを考えてみました。
ポーズ・構図指定工程
構図用poseデータ編集・入力
方法1)ポーズ・構図用画像から抽出
方法1)テキストやスケッチからの画像生成(chatgpt4)
方法2)画像アップロード
方法2)構図用poseデータリスト(おすすめ・履歴など)から選択
最終的に脚本を元におすすめ出るようにしたい
整形poseデータ編集・入力
構図用poseデータをキャラに合わせて正方形に自動整形
確認・編集
latent coupleの領域編集・入力
方法1)整形poseからの自動生成
方法2)手動ペイント
構図用poseデータと整形poseデータ、領域データが揃えば完了
メイン要素生成工程
各領域にプロンプト・LoRA指定
方法1)手動+登録リストからの選択式
(LoRAが指定された場合)
LoRAなしで生成後、その領域に対してLoRA + inpaintで自動修正
メインのガチャ
サイズ修正工程
コマに比べて小さい場合
サイズを自動拡張
inpaintで自動修正
ガチャ
コマに比べて大きい場合
自動切り取り+手動編集
最終修正工程
修正
方法1)inpaint
方法2)inpaint sketch
馴染ませ
方法1)tile+canny
方法2)denoise0.4のimg2img
完成
こだわらなければ、ポーズ選択と領域ごとのキャラ選択だけで自動作成されるような制作フローです。
上記はコマ割りがある前提ですがさらに進めて、脚本からコマ割りとセリフの生成まで自動化できるようになると、それこそscript2mangaが実現できそうですね。
おわりに
最後に制作した漫画の掲載でもって締めさせていただきます。
ご精読ありがとうございました。

















この記事が気に入ったらサポートをしてみませんか?