
LangChainのv0.0250からv0.0.265までの差分を整理(もくもく会向け)

本日のLangChainもくもく会のための差分まとめです。
この辺気になるよね、というところ
GPT Researcher x LangChain
GPT Researcherとは以下のような動きをするAIエージェント。
・任意のタスクに対する客観的な意見を形成する研究質問のセットを生成。
・各研究質問に対して、関連情報をスクレイプするクローラーエージェントをトリガー。
・スクレイプされたリソースごとに、関連情報に基づいて要約し、そのソースを追跡。
・最終的に、すべての要約されたソースをフィルターして集約し、最終的な研究報告書を生成。
そもそもはgpt-3.5-turboとgpt-4を利用するシステムなのだけど、新しく追加されたOpenAIアダプタを利用することで異なるLLMをGPT Researcherで使うことができようになるのが統合のポイント。
どの程度実用的かは分からないけど、ご家庭用GPUでも動作するLlama2をメインエンジンとして利用することで、AIエージェント活用の悩みの種であるAPI使用料を削減する一助になるかも知れない。
一方で「どの程度実用的かは分からない」と書いたのは、エージェント利用にあたってOSS LLMよりも商用LLM(API based LLM)の方が性能的に優位という論文を過去に読んだから。
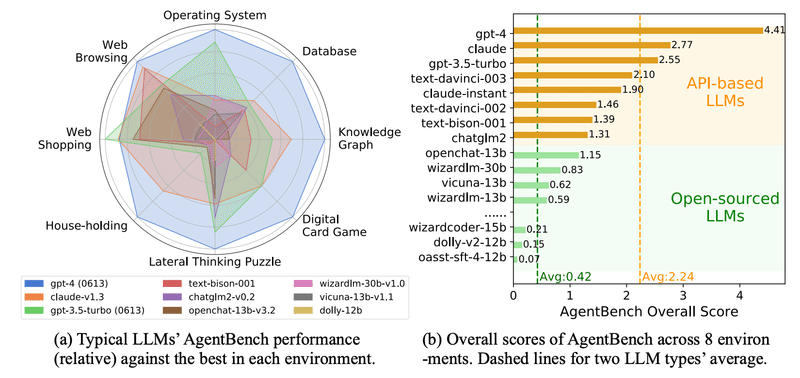
とはいえ、OSS LLMとして挙げられているLLMのパラメータ数は低いものしかないので、70Bぐらいのモデルだと違ってくるかも知れない。
Label Studio x LangChain
ブログ記事の具体例で挙げられているのは、LangChainで作成したQAシステムのコールバック先にLabel Studioを仕込み、蓄積されたデータを人手で評価(注釈付け)し、そのフィードバックをQAシステムに反映することで、QAシステムの品質向上を目指すというもの。
読んでいても具体的な実装についてはあんまりピンと来なかったのだけど、以下にfull exampleが用意されております。
https://github.com/HumanSignal/label-studio-examples/tree/master/question-answering-system
Conversational Retrieval Agents
レトリバー可愛いっすね。
ブログ記事によるとLangChainにおけるConversational Retrieval Agents(会話型探索エージェント)は以下の要素から構成されるとされています。
・OpenAI Functionsエージェント
・文字列を入力としてドキュメントのリストを返すリトリーバー
・人間とAI、AIとツールの相互作用を記憶する新しいタイプのメモリ
なぜ会話型である必要があるか?
・必要に応じてドキュメントを検索するため、効率的
・複数の検索ステップを実行できるため、柔軟
・以前の検索結果を記憶するため、再検索の必要がない場合がある
・会話に関するメタ質問(「私は何回質問しましたか?」など)に対応可能
使いすぎるとコンテキストウィンドウが埋まっちゃうので注意な、と書いてあるけど、一定過去のやりとりはセルフリフレクションで要約したものを持たせておくみたいな仕組みが必要でして、高度な記憶システムはやっぱり自前で実装した方が良いということになりそうです。
もくもく会でも話題になっていましたけど、記憶システムのベンチマークを取れるような仕組みが欲しいですねー。そのうち論文で出てきそうな案件。
NeumAI x LangChain
データソースとAIアプリケーションを直接接続すると問題になるのはデータの質の劣化。AIアプリケーションの品質はデータの質によって担保されるので、データソースの品質をいかにして高めるのかがポイントになる。
というわけで、NeumAIのアプローチはデータソースと検索用に用意したベクトルストアを同期させて、AIアプリケーションから直接アクセスするベクトルストア側のデータ品質を高めることによってAIアプリケーションの品質も担保しようというもの。
単にベクトルストアに突っ込むだけで品質がどうこうという訳でもないので品質トラッキングの仕組みも必要だと思うわけですが、NeumAIではそのあたりどう扱っているのかな、という意味で気になる。
v0.0.250 (2023.08.02)
新しい機能の追加
・Runnablesの新しい実行タイプを追加
・Huawei OBSからのドキュメント読み込み対応を追加
・Amazon SageMaker Experimentsのためのコールバックハンドラを追加
・StreamlitChatMessageHistoryを追加
・FirestoreChatMessageHistoryへのfirestore_clientパラメータの追加(既存のものがある場合、またはGCPプロジェクトを指定する等)
・normailzed openai embeddings embed_queryを追加
・Fireworksの統合を追加
・オーディオモデルのローカルサポートを追加
既存機能の変更
・スペルの一貫性を修正
・新しいllm_utilクエリを使用するように更新
・メジャリングトークンの長さを文字列にキャスト更新
・AOSSの初期化を修正
・http_auth内のサービスバリデーションを修正
バグ修正
・feature/issue-7804-chroma-client_settingsバグを修正
・Harrison/loaderバグを修正
v0.0.251 (2023.08.03)
新しい機能の追加
・メッセージの__add__機能を再追加
・airtableでのエンタープライズサポートフォーム
・Qdrantインテグレーションのリファクタリング
・`MLflow`の例を追加
・要約のユースケースを追加
・エンタープライズサポートフォームの文言を追加
・Newspaperを追加
・会話型リトリーバルエージェントを追加
バグ修正
・ドキュメントの文法を修正
・enumエラーメッセージを修正
・チェインの直接呼び出しを使用
・日時の代わりに塩を使用
・RemoteLangChainRetrieverの_get_relevant_documentsテストを追加
・軽微なタイポを修正
v0.0.252 (2023.08.05)
新しい機能の追加
・chain mapper内でのnone key許可を追加
・Google Cloud Enterprise Search connectorにSpell Correction Specを追加
・Deterministic Fake Embedding Modelを追加
・ModelScopeEmbeddingsにmodel_revisonパラメータを追加
・RSS Feed / OPMLのローダーを追加
・AzureChatOpenAIへのAzure Active Directoryトークンベースの認証アクセスを有効化
・character text splitterにおけるセパレータ制御のregexを追加
・AmazonKendraRetrieverにおけるDocument page_content formatterへのアクセスを提供
・ユーザーの入力をリフレーズするRetrieverを追加
・faissの_score thresholdパラメータを削除
・TFIDFRetrieverのためのtfidfベクトル化器の保存と読み込み、そしてドキュメンテーションを追加
・sklearnベクトルストア関数にフィルタを追加
・vectorstoreにおけるScaNNサポートを追加
・jsonシリアル化をスキップする`load()`デシリアライザ関数を追加
・llamacppに任意のkwargsサポートを追加
・Chatbotsユースケースを追加
既存機能の変更
・chain mapperの更新
・Google Cloud Enterprise Search connectorの更新
・interface jupyter notebookの説明を更新
・ModelScopeEmbeddingsの更新
・yamlのdepsを緩和
・SDKの最小予期バージョンをエラー説明に追加
・RetrievalQA chainのcallbackをLLMChainとStuffDocumentsChainを通して伝播
・load_summarize_chainを通したcallbackの伝播
・Vectaraのドキュメンテーションの更新
・短期オブジェクトの生成の削減
・リポジトリユーザネームをlangchain-aiに更新
バグ修正
・Async Retry Eventのハンドリングの修正
・RecursiveUrlLoaderの修正
・load map reduce documents chainの修正
・クエリ結果のサイズのバグ修正、他のバグ:vector_fieldパラメータのパス
・painless scriptスコアリングの改善,params.query_value.バグ修正
・モデルレビジョンの不一致を修正
・Add ScaNN support in vectorstoreに関連する修正
・リポジトリユーザネームの修正
v0.0.253 (2023.08.06)
新しい機能の追加
・Amazon Textractを用いたドキュメントローダーを追加
・テンプレート追加
・ランナブルと任意の関数の評価サポートを追加
・同一プロジェクトでの評価ランを追加
既存機能の変更
・rssドキュメントを更新
・fireworksを更新
・シリアライザー機能のドキュメントを追加
・get_started.mdxを更新
・ルータープロンプトの出力をJSONマークダウンコードブロックにネストするリマインダーを追加
・promptのドキュメントを更新
・StreamlitChatMessageHistoryドキュメントを例示付きで拡張
・ドキュメントの抽出のためのリファクタリング作業を行った
バグ修正
・makefile helpのバグを修正
・sklearnリンクの除去
・bilibiliの字幕取得の修正を行った
v0.0.254 (2023.08.07)
新しい機能の追加
・embeddings部分を追加
・Kendra結果アイテムIDとドキュメントIDをドキュメントのメタデータとして公開
既存機能の変更
・QA Use Case docsのリンクを更新
・利用可能なツールを一覧表示する無効なツールのテキストを改善
v0.0.255 (2023.08.07)
新しい機能の追加
・Dist Metrics for String Distance Evaluationを追加
・Mendable Searchの改善を追加
・faiss delete機能を追加
・Async Recursive URL loaderを追加
・MultiOn client toolkitを更新(2.0)
既存機能の変更
・例のメモリと返却されたドキュメントを追加
・ChatOpenAIのランタイムでのストリームを上書き修正
バグ修正
・例外の不一致を修正
・Rocksetのドキュメントを修正
・#8786 Callback handler disconnectの問題を修正
・long_context_reorder.ipynbのタイポを修正
・Harrison/as retrieverのドキュメント弦を修正
・無効なエスケープシーケンスの警告を修正
v0.0.256 (2023.08.08)
新しい機能の追加
・vLLMサポートを追加
・Codeyモデルのチャット履歴を追加
・モデレーションの例を追加
・Xataのベクトルストアとしてのサポートを追加
v0.0.257 (2023.08.08)
新しい機能の追加
・Run_on_datasetへの並行処理対応を追加
・BGE埋め込みのサポートを追加
・Flush=Trueをstream examplesに追加
・Nebula LLMをLangChainに導入
・forced_decoder_idsという新パラメータをOpenAIWhisperParserLocalに追加
・ChatAnyscaleを作成
・OutputFixingParser, RetryOutputParser, RetryWithErrorOutputParserを非同期に進化
・カスタムローダーをGcsFileLoaderに指定できるように改善
・USearch Vector Storeを追加
・OllamaをLLMとして追加
既存機能の変更
・メタファー検索例のデフォルトをプロンプトオプティマイザに更新
・Metaphorドキュメントを更新
バグ修正
・抽象メッセージ追加に関するバグを修正
・評価解析テストのバグを修正
・Mutation in placeというバグを修正
・Colabリンクの抽出ntbkの修正
・JsonOutputFunctionParserで改行を含むMarkdownコードでバグを修正
・Fetch中にエラーが発生した場合、web_base.pyで""を返すよう修正
・Metaphorのインストールコマンドガイドの修正
・新しい行がMarkdownコードブロック内でJson出力パーサを処理する修正
v0.0.258 (2023.08.09)
新しい機能の追加
・AmazonKendraRetrieverにuser_contextを追加
・ドキュメントの外観を自動的にシステムデフォルトに設定
・'ストアとチャット履歴の参照'のドキュメントに追記
・VectorStoreIndexWrapperクエリにフィルターのキーワード引数を追加
・Vectaraの呼び出しに一貫したタイムアウトを追加
・PubMedのドキュメントローダを追加
・tensoflow_datasetsのドキュメントローダを追加
・内部コード非推奨APIを追加
既存機能の変更
・GCSからアップロードされたドキュメントのソースを修正
・integrations:providers:bedrockのドキュメントにおける不正確なインポートを修正
・awslambdaのドキュメントのインポートを修正
・Nebula LLM統合の修正
・Vectaraのドキュメントのタイポを修正
・ModulesページからEvaluationを削除
・BGEエンベディングのクエリプロンプトを改善
・Evalのバリデーション設定を緩和
バグ修正
・Google Cloud Enterprise Search Retrieverの`AttributeError`を解消
v0.0.259 (2023.08.09)
新しい機能の追加
・Harrison/imageを追加
・基本ストレージインターフェース、2つの実装、ユーティリティエンコーダを追加
・Airbyteベースのローダーを追加
・予定されたテストGHAを追加
・エラートレーサーのIDを追加
・Rocksetをチャット履歴ストアとして統合
既存機能の変更
・Weaviateの認証例を追加とReadME内のスペル修正
・lcelのフォールバック文書化
v0.0.260 (2023.08.10)
新しい機能の追加
・非同期の出力パーサーを追加
・Runnablesに対する変換支援を追加
・軌跡評価チェインへのテストを追加
・Azure OpenAIモデルマッピングの修正機能を追加
・OpenAI関数のためのルーターを実装
既存機能の変更
・Key Checkを更新
バグ修正
・スケジュールされたghaの修正
・Airbyteローダーの修正
v0.0.261 (2023.08.10)
新しい機能の追加
・airbyte loadersのインポートを追加
・サンプリングパラメータにlogprobsを追加
・ChatAnthropicにモデルキーワード引数をオプション化してオーバーライドを許可
・redis storageを追加
・API use case を追加
既存機能の変更
・コサイン類似度に対するゼロ除算の警告を抑制
・空のGoogleスプレッドシートをスキップ
・DirectoryLoaderのスライシング
・サンプルノートブックのポートとSSL使用を更新
・UTF-8エンコーディングでファイルを開く
・runnablesのトレーサーとデバッグ出力の小さな改善
・runnable dirを作成
・grobidドキュメントを改善
バグ修正
・壊れたコードブロックの表示を修正
v0.0.262 (2023.08.11)
新しい機能の追加
・実装.transform()をRunnablePassthroughに追加
・Takeoffの統合を追加
・Agent vector storeツールドキュメントを追加
・FileSystemBlobLoaderに除外を追加
・claude-instant-1モデルを試験からサポートに移動
・掲載embeddingsの非同期メソッドを追加
・pineconeでembeddingsを使用
・structured_chatエージェントの出力パーサーの正規表現の強化
・Recursive urlローダー w/テストを追加
・ConversationBufferMemoryとConversationBに利便性メソッドを追加
・python replに非同期処理を追加
・openaiアダプターを追加
・BagelDB (bageldb.ai)、VectorStoreの統合を追加
・id列タイプを関数と一致するuuidに変更
・文字列例マッパーを追加
・ConversationTokenBufferMemoryのバッファメソッドが文字列としてメッセージを返すことができるように
・Bagatur/pineconeをベクトル化
・Fireworksのモデル名を更新
既存機能の変更
・ArgillaCallbackHandlerを最新のargillaリリースに更新
・pr tempを更新
・api ref examplesを更新
・ChatPromptTemplateの廃止提案
・RedisStoreの初期設定とドキュメンテーションの更新
・コミュニティページのドキュメントを追加
・pydantic format instruction promptを更新
・filter metadataを更新
バグ修正
・Metaphor Search ToolがAPIレスポンスでキーが欠落しているとエラーをスローする問題を修正
・sched ciバグを修正
・Bagatur/fix schedバグを修正
・sched ci (更に)を修正
・(Mendable Search) Tabbing out問題がスタックするのを修正
・ドキュメンテーションの間違ったコードブロックを修正
・prep_promptsでinput_listが空の場合にIndexErrorを修正
・json toolを修正
v0.0.263 (2023.08.13)
新しい機能の追加
・LabelStudioの統合を追加
・Replicateのシリアライザブル対応を追加
・Redisクラスタサーバーの基本的な対応を追加
・ウェブスクレイピング、Chromiumローダー、BS4トランスフォーマーの新しいユースケースドキュメントを追加
・ChatPromptTemplateの数個のリスト操作をサポート
・ArcGISLoaderおよび例示ノートブックの作成
・リアルタイムの暗号交換価格のLangChainユーティリティを追加
・Azure OpenAIのために必要な提供デプロイメントに設定されているdeployment_idを確認
・SmartGPTワークフローを追加(問題#4463)
・HuggingFaceEmbeddingsのマルチGPU推論をサポート
既存機能の変更
・ArgillaCallbackHandlerを適切にデフォルト値のapi_urlおよびapi_keyを使用するように修正
・ドキュメントローダーの一貫性を修正
・プライベートモジュールはドキュメンテーション化しないようにAPIリファレンスを修正
・チェインのキーを更新
バグ修正
・ウェブリサーチリトリーバーの未知のリンクに対する修正
・SVMリトリーバーがドキュメントメタデータを破棄する問題を修正
・対話型ウォークスルーリンクを修正して404エラーを解消
v0.0.264 (2023.08.15)
新しい機能の追加
・並行して複数のデータを取得する機能を追加
・sphinxディレクティブを使用してドキュメンテーションを変更する強化機能を追加
・DeepSparseをLLMとしての機能を追加
・vLLMのOpenAI互換サーバーをサポートする機能を追加
・ChatLiteLLMモデルを追加
既存機能の変更
・pydantic v1の名前空間を作成し、pydantic v2に対して部分的な互換性を追加
・2つのpydanticのインポートを更新
・LlamaCppの入力引数のドキュメントを更新
バグ修正
・BaseOpenAIのタイピング問題を修正
v0.0.265 (2023.08.15)
新しい機能の追加
・RedisCacheにttlを追加
・非同期メソッドを追加
・ロックセット用のlangchain使用状況追跡を追加
・protobufsのシリアライズ対応をWandbTracerに追加
・Ernie チャットのサポートを追加
既存機能の変更
・ロギングの修正
・pydantic v1を条件付きで追加
・OpenAPI機能をpydantic v2互換の条件でラップ
・Ollamaのドキュメントを更新
・ドキュメントの一貫性を確保
・リトライ時のデフォルト動作を変更
・クライアントツールキットのプロンプトを改善
・リダイレクトを一元化
・LlamaCppのmax_tokens引数を更新
・Dingoのドキュメントを更新
バグ修正
・#9197に関連するjinachatの修正
・Ernie チャットの修正
・max_marginal_relevance_searchの修正
個人的なお気持ちとしては全然LangSmithを触れていないので、もくもく会の時間でLangSmith触ってみたいっす。
そんなわけで今日もよろしくお願いします!
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?