
OpenAIのEvalsを利用してLLMの性能をテストする方法

OpenAIのGPT-4 APIのウェイティングリストに申し込むと、メールで以下のような内容が送られてきます。
While we ramp up, invites will be prioritized to developers who have previously build with the OpenAI API. You can also gain priority access if you contribute model evaluations to OpenAI Evals that get merged, as this will help us improve the models for everyone.
OpenAI APIで開発したことがある開発者に優先的に招待します。また、OpenAI Evalsにモデル評価を投稿し、それがマージされた場合にも、優先的にアクセスできるようになります。
なかなか招待が来ない(私のところにも来ない)GPT-4 APIの利用権限ですが、OpenAIのEvalsでLLMをテストするためのデータセットを送って採択されるといった貢献をすることで利用権限をもらうことができるようです。
これを見ると一刻も早くGPT-4 APIを使いたい我々に残された道は、もはやOpenAIのEvalsで採択されることしかないような気がしますね・・・!
一方で、Evalsのドキュメントはしっかり整備されているものの、一読しても使い方がいまいち分かりにくいと感じます。そこで、今回は簡単なデータセットを作成してテストする方法についてガイドを書いてみようと思います。
Evalsの仕組み
Evalsは以下の条件を与えたときに、指定したLLMがどれだけの精度でタスクをこなすかを検証するための仕組みです。
メトリクス(accuracyなどの評価指標)
データセット(プロンプトと期待する答えをペアにしたjsonlファイル)
判定方法(MatchやIncludeといった判定方法を選択)
これらの情報をYAMLファイルで定義すると、検証プログラムがその定義に従って動きます。実行すると以下のようなログが出てきて、どのぐらいの精度でタスクをこなせたかが表示されます。
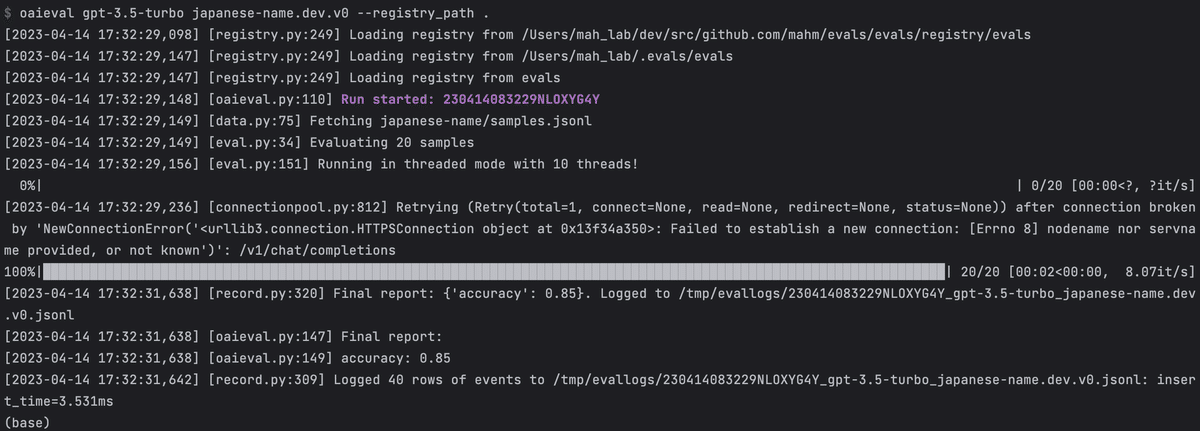
というわけで、早速データセットとYAMLファイルを用意してみましょう。
実際に利用してみる
データ準備
まずevalsライブラリをpip installします。
$ pip install evals次にデータセットとしてどんなものを用意するかを考えなければいけません。ここではEvalsにプルリクしようとしてボツネタにした「日本語の文章中から日本人の名前を抜き出すタスク」を例にしようと思います。
データセットとして以下の20件のデータを用意しました。フルネームだったり「くん付け」だったりと、バリエーションをつけています。
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "この公園で、田中太郎と一緒にピクニックを楽しんだ。"}], "ideal": "田中太郎"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "鈴木先生の手作りクッキーを食べてみんな笑顔になった。"}], "ideal": "鈴木先生"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "佐藤講師から、素晴らしい写真展に誘われて行った。"}], "ideal": "佐藤講師"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "ランチに山本美咲と彼女のおすすめのラーメン屋に行った。"}], "ideal": "山本美咲"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "渡辺さんが教えてくれたお寺で、静かな時間を過ごした。"}], "ideal": "渡辺さん"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "伊藤明子と一緒に、地元の動物保護施設を訪れた。"}], "ideal": "伊藤明子"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "山田くんがオーガナイズしたハイキングイベントに参加した。"}], "ideal": "山田くん"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "中村良太が作った素敵な絵画をギャラリーで見つけた。"}], "ideal": "中村良太"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "小林友美が紹介してくれたバンドのライブに行って楽しんだ。"}], "ideal": "小林友美"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "高橋先生と共に慈善バザーでボランティア活動をした。"}], "ideal": "高橋先生"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "今日のランニングは田中太郎のアドバイスでペースを上げた。"}], "ideal": "田中太郎"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "花子が作ってくれた可愛い手編みのマフラーを受け取った。"}], "ideal": "花子"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "一郎くんの推薦で、面白い本を読んで知識が広がった。"}], "ideal": "一郎くん"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "美咲ちゃんと一緒に新しいダンスクラスに挑戦してみた。"}], "ideal": "美咲ちゃん"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "健一の案内で、美味しい居酒屋を見つけた。"}], "ideal": "健一"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "伊藤明子がデザインしたTシャツが、イベントで大評判だった。"}], "ideal": "伊藤明子"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "山田勇太が率いるチームと対戦して、熱いバスケットボールゲームを楽しんだ。"}], "ideal": "山田勇太"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "中村良太が薦める映画を観て、心が温まった。"}], "ideal": "中村良太"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "友美が歌う歌を聴いて、元気をもらった。"}], "ideal": "友美"}
{"input": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "高橋さんのおかげで、スムーズに英語でコミュニケーションができた。"}], "ideal": "高橋さん"}上記のデータにsamples.jsonlという名前をつけて保存します。YAMLを含めたファイル構成は以下のような形になります。
.
├── japanese-name.yaml
└── samples.jsonl次にYAMLファイルを作成します。期待する答えとの一致を確認したいので、Matchを採用することにしましょう。以下の内容を「japanese-name.yaml」という名前で保存して下さい。
japanese-name:
id: japanese-name.dev.v0
metrics: [accuracy]
japanese-name.dev.v0:
class: evals.elsuite.basic.match:Match
args:
samples_jsonl: samples.jsonl「japanese-name」というのは今回任意につけた名前です。
japanese-name:
id: japanese-name.dev.v0
metrics: [accuracy]この内容は、コマンド実行時に「japanese-name」と呼び出したときに実際に実行される内容は「japanese-name.dev.0」で、メトリクスとして「accuracy」を採用していることを意味します。
japanese-name.dev.v0:
class: evals.elsuite.basic.match:Match
args:
samples_jsonl: samples.jsonl次にこの内容は、LLMが出力した結果と比較するためのクラスは「evals.elsuite.basic.match:Match(一致で確認)」で、データは「samples.jsonl」という名前で提供されていることを意味します。
比較クラスには他にも以下のクラスが用意されています。
evals.elsuite.translate:Translate
翻訳の比較
evals.elsuite.basic.match:Match
一致比較
evals.elsuite.basic.includes:Includes
包含比較
evals.elsuite.basic.fuzzy_match:FuzzyMatch
一致比較でF1スコアも返す
実行
ここまで準備ができたら、あとは実行です。環境変数にOPENAI_API_KEYが設定されていないと動かないので、設定していない方は以下のコマンドで設定しておいてください。
$ export OPENAI_API_KEY=[YOUR KEY]「japanese-name.yaml」ファイルや「samples.jsonl」ファイルが配置されているディレクトリで以下のコマンドを実行します。
$ oaieval gpt-3.5-turbo japanese-name --registry_path . すると以下のような結果が出力されます。accuracyは0.85ということで、そこそこの結果ですね。

ログファイルを見ると、具体的にどんな判定がされているかを確認することができます。
{"run_id": "230414084347XXUO7QFU", "event_id": 38, "sample_id": "japanese-name.dev.1", "type": "sampling", "data": {"prompt": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "鈴木先生の手作りクッキーを食べてみんな笑顔になった。"}], "sampled": ["鈴木先生 (Suzuki-sensei)"]}, "created_by": "", "created_at": "2023-04-14 08:43:50.667873+00:00"}
{"run_id": "230414084347XXUO7QFU", "event_id": 39, "sample_id": "japanese-name.dev.1", "type": "match", "data": {"correct": true, "expected": "鈴木先生", "picked": "鈴木先生", "sampled": "鈴木先生 (Suzuki-sensei)", "options": ["鈴木先生"]}, , "created_at": "2023-04-14 08:43:50.667923+00:00"}「鈴木先生の手作りクッキーを食べてみんな笑顔になった。」という文章では、LLMが「鈴木先生 (Suzuki-sensei)」という答えを出し、正答しています。
一方で、
{"run_id": "230414084347XXUO7QFU", "event_id": 36, "sample_id": "japanese-name.dev.2", "type": "sampling", "data": {"prompt": [{"role": "system", "content": "Extract the name of a Japanese person from the given text."}, {"role": "user", "content": "佐藤講師から、素晴らしい写真展に誘われて行った。"}], "sampled": ["There is no specific name of a Japanese person mentioned in the given text."]}, "created_by": "", "created_at": "2023-04-14 08:43:50.553730+00:00"}
{"run_id": "230414084347XXUO7QFU", "event_id": 37, "sample_id": "japanese-name.dev.2", "type": "match", "data": {"correct": false, "expected": "佐藤講師", "picked": null, "sampled": "There is no specific name of a Japanese person mentioned ie given text.", "options": ["佐藤講師"]}, "created_by": "", "created_at": "2023-04-14 08:43:50.553775+00:00"}「佐藤講師から、素晴らしい写真展に誘われて行った。」という文章では「There is no specific name of a Japanese person mentioned in the given text.」という出力になってしまい、正答することができませんでした。「佐藤講師」という呼び名がLLMにとって特殊であり、人の名前だと判別できなかったことが分かります。
EvalsはLLMの性能評価という表向きですが、プロンプトのテストデータとしても有効に使うことができるかも知れません。LLMをコードに組み込む場合、プロンプトの変更によってどの程度のインパクトが発生するかを正確に把握することは難しいため、このような評価プログラムを挟んでおくことは有用だと思われます。
ただ、テストの実行にもAPI利用料が発生するので、データセットは最小限にするか20件ぐらいにサンプリングするなどして実行するのが良さそうです。
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?