
AI 実装検定への道(11)

AI 実装検定 A級合格へ向けて学習を進めています。
というか、前回10回目を公開したのが2/4でしたので、もう1ヶ月以上も放置状態!あれやこれやと手につかず、また再開したいと思います。
さて、その前回投稿は10回目でしたが、引き続きGoogle Colaboratoryを利用してプログラミングの章を引き続き進めて書いていくとします。
前回は短いまとめでしたが、第20講「pandasで欠損値の処理」を終えたので、一区切りとしました。前回に引き続き欠損値について学び、欠損値でのみ列を追加したり、前回同様「dropna」を使って欠損値を削除したり、その方向を行方向、列方向に閾値(threshold)を決めて割愛する「thresh」。その後に、欠損値に任意のデータを置き換える「fillna( )」、それに続いて「method( )」を用いて欠損値の前後の値で補う「ffill」と「bfill」。(私の中では「前に」という意味の「forward」、「後ろ」にという意味の「back」という感じで、「f」と「b」の理解をしました。)2次元のDataFrameではさらに「axis」を使って行方向(1)、列方向(0)を指定するというところまで辿り着きました。
今回は、公式テキスト250ページの第21講「pandasでデータセットの連結と計算」から再開します。
まずは、いつも通りに、「Numpy」と「Pandas」を読み込んでおきます。
(コード記述)
import numpy as np
import pandas as pd
これからデータセットの連結(Concatenation)について、「concact」関数を使うそうです。
(コード記述)
s=pd.Series([8,4,5,0,9])
s2=pd.Series([1,7,3,2,0])
s
(結果)
0 8 1 4 2 5 3 0 4 9 dtype: int64
(コード記述)s2
(結果)
0 1 1 7 2 3 3 2 4 0 dtype: int64
このsとs2の二つのSeriesを「concact」関数を使って連結し、dfとします。
(コード記述)
df=pd.concat([s,s2],axis=1)
df
(結果)

(コード記述)type(s)
(結果)pandas.core.series.Series
公式テキストにあるように、sは「Series」であると返されました。
では、dfの方はどうでしょう?
(コード記述)type(df)
(結果)pandas.core.frame.DataFrame
dfの方は、「DataFrame」であるとのこと。
この時点で、もうだいぶん忘れています・・・・前回の第10回も眺めながら進めます。(https://note.com/maedamasayuki/n/n9fbd49705fa3)
Indexが4、5、6でB、C、Dという値を格納した「Series」であるs5と、Indexが7、8、9でE、F、Gという値を格納した「Series」であるs6を用意して、「concact」関数を使って連結します。ここでは、axisを指定しないで実施してみましょう。
(コード記述)
s5=pd.Series(["B","C","D"],index=[4,5,6])
s6=pd.Series(["E","F","G"],index=[7,8,9])
pd.concat([s5,s6])
(結果)
4 B 5 C 6 D 7 E 8 F 9 G dtype: object
ここまでで、「Series」の連結を見てきたので、次に「DataFrame」の連結を見ていきます。
まず、A列、B列のw列を持っていて、indexが1、2の「DataFrame」としてdf1とdf2を準備します。
(コード記述)
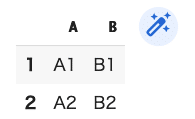
df1=pd.DataFrame([["A1","B1"],["A2","B2"]],index=[1,2],columns=["A","B"])
df1
(結果)
(コード記述)
df2=pd.DataFrame([["A3","B3"],["A4","B4"]],index=[1,2],columns=["A","B"])
df2
(結果)

これらの「DataFrame」df1とdf2を、「concact」関数を使って連結します。axisを指定しない場合には縦方向に連結されます。
(コード記述)pd.concat([df1,df2])
(結果)

これは、「append」関数を使っても同じ結果となるようです。
(コード記述)pd.append([df1,df2])
(結果)
------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-14-63b6e08e41e6> in <module>
----> 1 pd.append([df1,df2])
/usr/local/lib/python3.9/dist-packages/pandas/init.py in getattr(name)
259 return _SparseArray
260
--> 261 raise AttributeError(f"module 'pandas' has no attribute '{name}'")
262
263
AttributeError: module 'pandas' has no attribute 'append'
ってやればいいと思ってたが、違うんだね・・・「module 'pandas' has no attribute 'append'」・・・「pandas」モジュールには「append」が備わってませんよ〜的なエラーが出てきました。
下記が、正解だそうです〜
(コード記述)df1.append(df2)
(結果)

こんな感じで、確かに同じになりましたね。
この結果に、何か注意書きが出ました。
<ipython-input-15-8ab0723181fb>:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. df1.append(df2)
あんまり意味がわからないけど、「append method」のフレームは時代遅れで推奨しないと。将来のバージョンでは、「pandas」からリムーブされますよ〜みたいな感じでしょうか?
次に、「DataFrame」を横方向に連結してみます。
df3とdf4を下記のように準備します。
(コード記述)
df3=pd.DataFrame([["A0","B0"],["A1","B1"],columns=["A","B"])
df3
(結果)
File "<ipython-input-16-41aa8fc8dea0>", line 1 df3=pd.DataFrame([["A0","B0"],["A1","B1"],columns=["A","B"]) ^ SyntaxError: invalid syntax
おっと、どこか間違えていました。
よく見ると、["A1","B1"]の後ろに、もう一つ「 ] 」を置くのを忘れていたようです。
(コード記述)
df3=pd.DataFrame([["A0","B0"],["A1","B1"]],columns=["A","B"])
df3
(結果)

(コード記述)
df4=pd.DataFrame([["C0","D0"],["C1","D1"]],columns=["C","D"])
df4
(結果)

ここから、df3とdf4を横方向に連結します。横方向なので、axis=1を加えて書いてみます。
(コード記述)pd.concat([df3,df4],axis=1)
(結果)

公式テキストにもあるように、axis=1を無しにしてみると・・・
(コード記述)pd.concat([df3,df4])
(結果)

はい、確かにこのようになりました!
これに、「join="inner"」を加えてやると・・・
(コード記述)pd.concat([df3,df4],join="inner")
(結果)

あれ??
公式テキストでは、上記のようにはならないが・・・あ、昨晩ページを1枚めくってしまっていて、256ページに進んだ気になっていました。
気を取り直して、254ページ下部から読み進めて、255ページに進みます。3列2行の「DataFrame」を2つ用意します。
(コード記述)
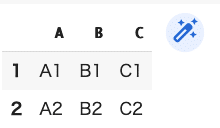
df5= pd.DataFrame([["A1","B1","C1"],["A2","B2","C2"]],
index=[1,2],columns=["A","B","C"])
df5
(結果)
(コード記述)
df6= pd.DataFrame([["B3","C3","D3"],["B4","C4","D4"]],
index=[1,2],columns=["B","C","D"])
df6
(結果)

この2つの「DataFrame」を「concact」関数を使って連結します。
(コード記述)pd.concat([df5,df6])
(結果)

ようやく、少し前に間違えて書いたところに戻れます。これに、「join="inner"」を加えてやると・・・
(コード記述)pd.concat([df5,df6],join="inner")
(結果)

おっと!「NaN」の部分だけが詰まったようになるのかと思いましたが、BC列だけが残って、「NaN」を含むAD列は共に省略されてしまいました。
今日はここまでにします。
今回は、前回から1か月長怠けてしまっていたので、改めてGoogle Colaboratoryの環境に触れ、「Series」「DataFrame」について「concact」関数を使った連結をしたり、「append」関数についても勉強しました。久々の勉強なので、少ししか進みませんでしたが、次回は、公式テキスト256ページの下段から再開します。「merge」を使って横方向の連結を学ぶようです。
この記事が気に入ったらサポートをしてみませんか?