C-5 マルチモーダルRAGの社会実装への技術アプローチ

デブサミでメモしたことをつらつら書いていきます。
MuRAG = マルチモーダルRAG
RAG = 検索拡張生成
LLMでは足りない外部の情報などを取り組みことによってハルシネーションを抑える

マルチモーダル
複数のデータ形式が混在している
ドキュメント
写真、音声、動画・・・

MuRAG
画像が入ることも想定している
構成要素
画像の特徴量
テキストの特徴量
OCR・ドキュメントレイアウトアナリシス・テーブルtoText
テキストの生成

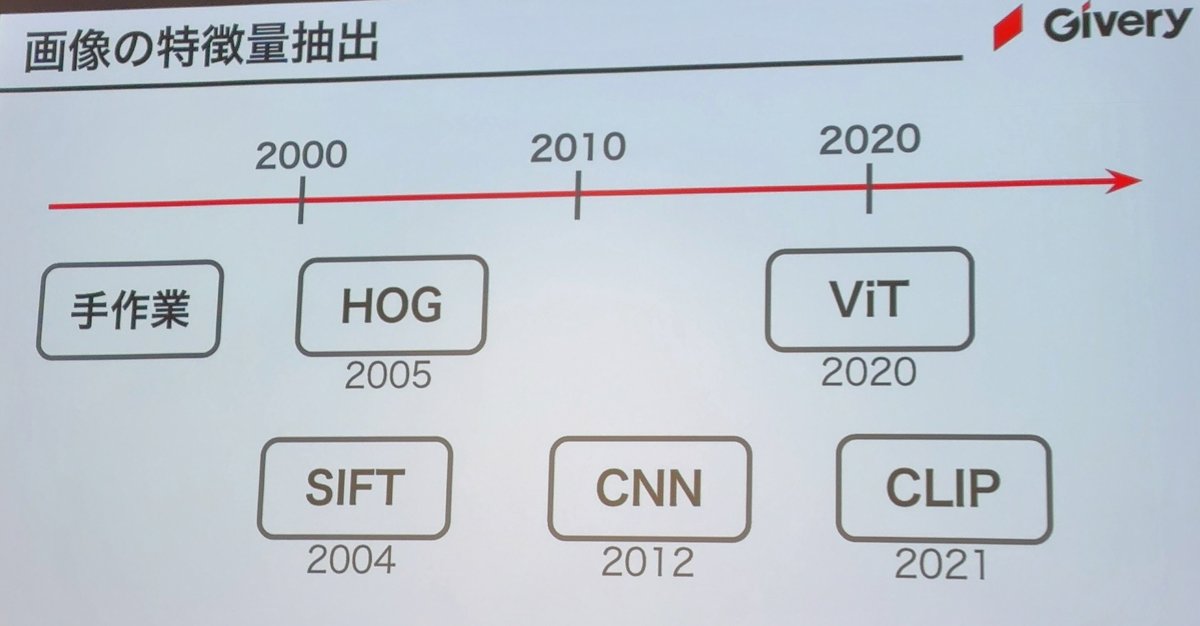
MuRAG到達までの歴史

画像の特徴量抽出
テキストの特徴量抽出

テキストの生成
CLIPが出てきてマルチモーダルができるようになってきた

OpenAIのモデル

今までの研究がつながって今のモデルにつながっている
MuRAG実践
実現方法
LangChain Unstructured GPT4V
インデックス化
PDFの中にいろんな要素があるが、分解させているイメージ
画像だけはそのまま入れるが、それ以外はエンベディングしている
正確には画像もエンベディングしているが、物自体は画像を突っ込んでいる

全体像

Assistants API
インデックス化

全体象
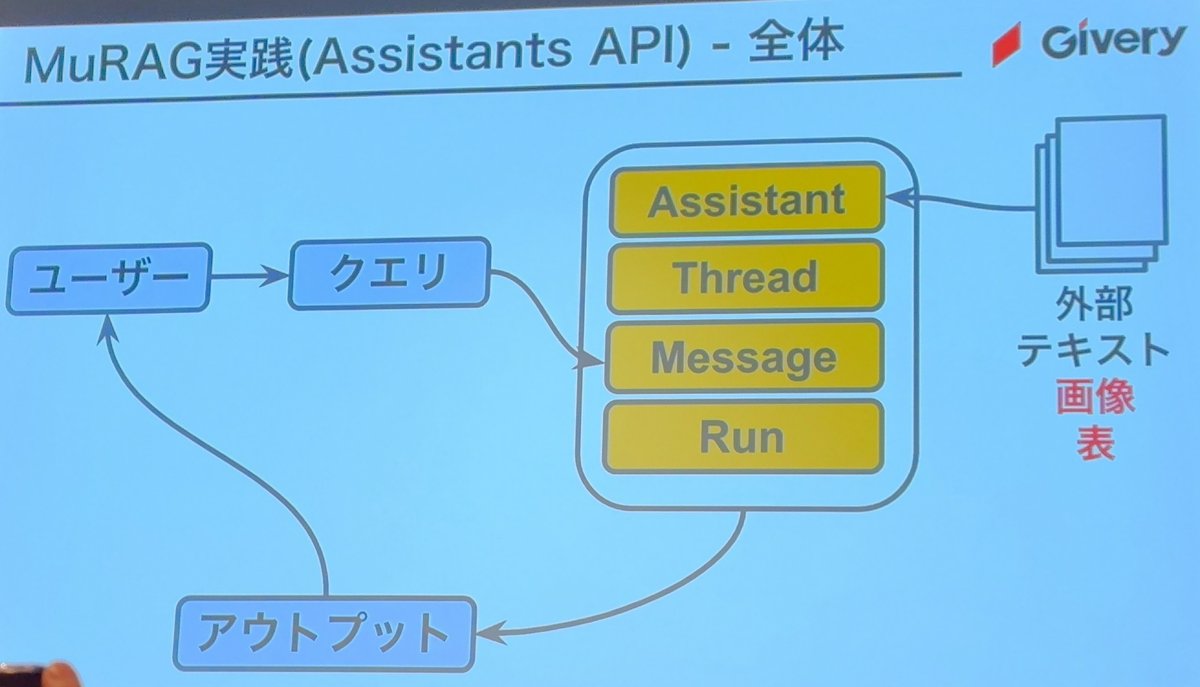
Assistants APIに投げちゃいばマルチモーダルRAGのインデックス化ができてしまう
短絡的にこれでいいじゃんと考えてしまうが・・・
確かに試す場合はいいと思うが、いくつか課題はある
プロダクトにするには壁がある・・・
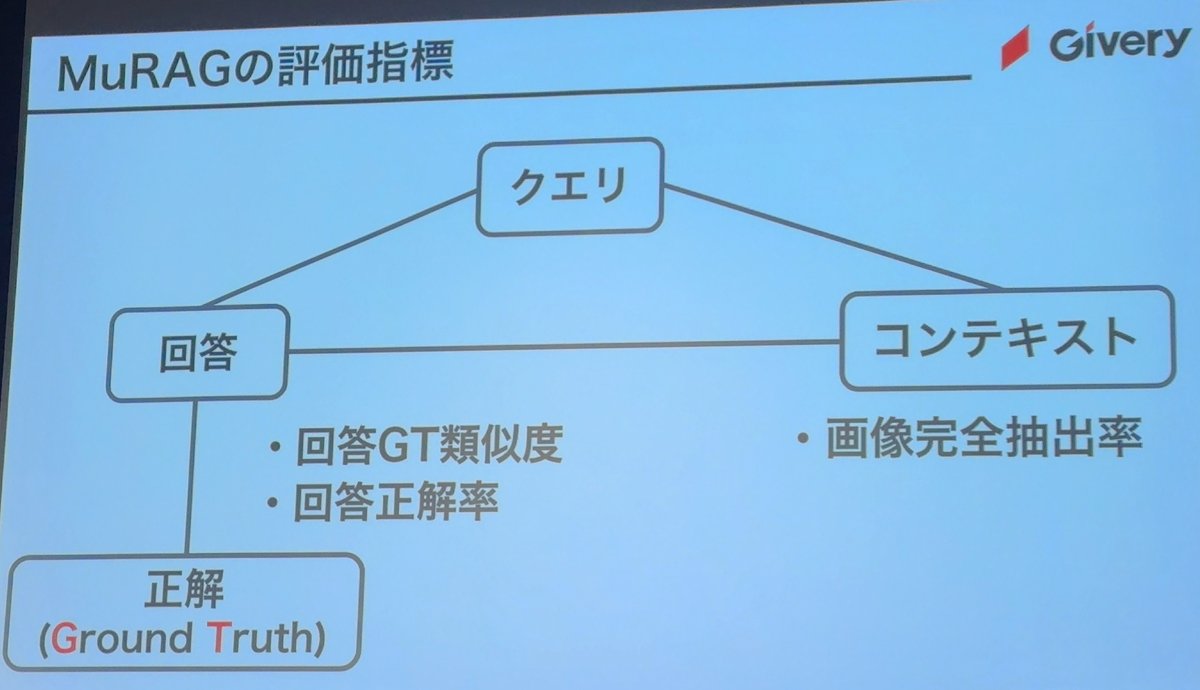
MuRAGの評価指標
画像完全抽出率
正確に図や表を抜き出せているか
回答GT類似度
元々用意しておいたコンテキストと回答が類似しているか
回答正解率
クイズ形式でちゃんとあっているか
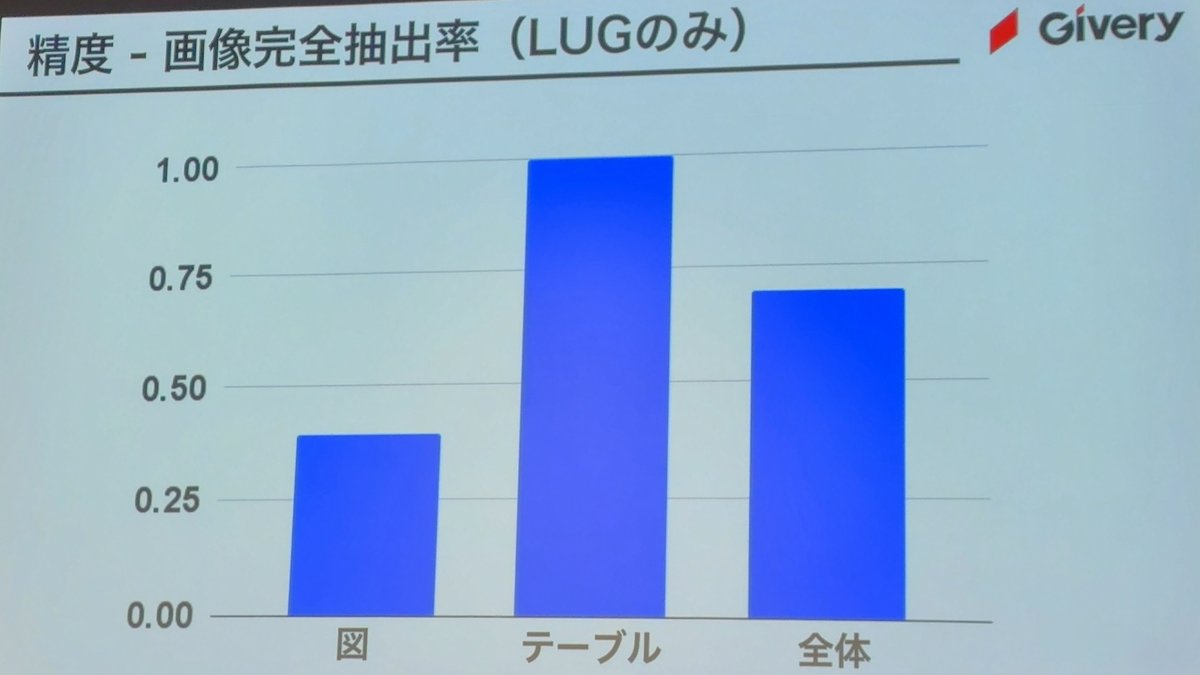
画像完全抽出度
表2を抜き出せという問いに対して見切れてるから不正解とした

LUGの評価
精度 参照なし/有りについて
上が参照なし
下が参照あり

回答GT類似度の精度比較

回答正解率の精度

実践まとめ
サービスやプロダクトとして提供するときに、パフォーマンスやRate Limitが最大の課題になっている

この記事が気に入ったらサポートをしてみませんか?