
Stable-Diffusionで落書きを清書させるやり方

概要
自分が2~3分で描いた落書きをStable DiffusionというAIに清書してもらいました。
そのやり方をまとめた記事です
まず、こちらが自分が2~3分で描いた落書きです。
この絵からもご察しの通り、筆者は絵は上手くない方です。

これをAIに清書したのがこれです

元の構図を維持しつつ、それらしい色を塗ったり、サボってた細かい部分いい感じに補完してくれてますね!
画像単体で金を稼げるクォリティではないですけど、SNSアイコンで利用するとか、同人ゲーム内の素材として使うのなら十分使えそうなレベルな気がします。
導入
落書きから清書を描いてもらうまでに使った方法を説明していきます。
概要
Google Colaboratory というサービス上で Stable Diffusion で動かし、お絵描きしてもらいます。
用意するもの
月額1000円課金する覚悟
Google Colaboratoryのサービス利用料です
ゲーミングPC並のGPUが月額1000円で使えると考えると安いです
清書したい落書き
512×512推奨です
8の倍数でないとエラーが出るみたいです
Googleアカウント
お絵かきソフト
レイヤー機能に対応していれば何でも
筆者はClipStudio(有料)やpaint.net(無料)を使用
あるといいもの(無くてもOK)
パソコン
あったほうが便利だけどスマホやタブレットでもOK!
画力
あったほうが有利だけど無くてもなんとかなったよ!
プログラミング知識
あったほうが理解が早いけど、無くてもなんとかなるよ!
英語力
あったほうが良いみたいだけど、無くてもなんとかなったよ!
準備
Google Colaboratory上で Stable-Diffusionを動かす方法はいくつかありますが、今回はわたしが公開している↓のノートブックを使います
これを使うといい点は主に以下の点です
GoogleDriveとの連携や、Stable Diffusionのインストールが全自動
大量の画像作成に対応
画像の一部修正などの機能にも対応
使い方はノートブックに描いてあるので、まずは、こちらを読んでサンプルが動くところまでやってみましょう。
また、下記のリンクからGoogle Colaboratoryへの課金もしておきましょう。
お試しで動かすなら無課金でもOKですが、無課金だと時間制限があるので、今回試す方法だと最後まで清書できないかもしれないです。
月額1000円の課金と5000円の課金がありますが、今回の記事の絵は1000円で描けました
実践
方針
Stable Diffusionでは、以下の3つの事ができます
テキストから画像を作成する
画像から画像を作成する
画像の一部を修正する
今回は、2と3を使って、落書きをブラッシュアップしていきます。
画像から画像を作成の方法
画像から画像を作る際、3つのことを指示することが出来ます
元の画像
今回使う落書きです
テキスト
画像を描く指針となるテキスト。英語が望ましい
文字列優先度(画像とテキストのバランス)
0~1で指定し、1だとテキスト優先、0だと元画像優先です
元の画像
元画像は512x512で用意し、Google Driveの diffusion/user-data に設置しましょう。
元画像の色や線の太さは仕上がりに影響するので、意識しておくといいかもです。
テキストの決め方
基本は「描きたい内容」+「その画像のスタイル」となります。
今回の記事では以下のテキストをベースにしてます。
Short ponytail girl face with brown hair. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k.「Short ponytail girl face with brown hair」
ここは DeepL翻訳 を使って作りました。
「By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k.」
ここは、Midjourny で良さそうな呪文を探しながら適当に作りました。
他にも色々とコツはあるみたいですが、自分も詳しくはないので気になった人は、「Midjourny 呪文」とか「Stable Diffusion」とかで検索すると良いと思います。
文字列優先度の決め方
これについては、元の絵やテキストによって最適な値が異なるので、色々と試すのが良いです。
私が公開してるノートブックで↓のコマンドを打つと、文字列優先度を0.1刻みで3枚ずつ作成してくれます。
0.1刻みで出した結果を元にどの値が良さそうか見ていきましょう
# 例:strengthを色々試す場合
for strength in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]:
dc.img2img("lisa_face/" + str(strength), 3, strength, 512, 512, "lisa.png", "Short ponytail girl face with brown hair. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k.)例えば、今回の元の絵を文字列優先度0.2~0.9で変化させると↓のようになります。
今回の場合は、0.6~0.8だと、元の構図を保ちつつキレイにまとめてくれるので良さそうということが見えてきます。

そうしたら、次はコマンドを少し変えて、0.6~0.8を0.05刻みで画像を10枚ずつ作るようにしましょう。
数字の部分を変えて実行ボタンを押すだけなので、プログラミングの知識がない人でも、雰囲気でわかると思います。
# 例:0.6~0.8で0.0.5刻みに画像を10枚作成
for strength in [0.6, 0.65, 0.7, 0.75, 0.8]:
dc.img2img("lisa_face/" + str(strength), 10, strength, 512, 512, "lisa.png", "Short ponytail girl face with brown hair. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k.)30分~60分ぐらい待つと50枚ぐらい画像が生成されるので、その中から一番イイ!と思った画像を選びましょう。
今回は↓を選びました。

ちなみに、この第一世代を元画像に指定として指定し、更に画像を作成させることで、画像のブラッシュアップをすることも可能です。
今回は、この画像をさらにブラッシュアップし、第2世代の↓の画像を生成しました。

画像の一部を修正する方法
次に、画像の一部を修正する方法を説明します。
例えば、今回の画像ではメガネを後から付け足したのですが、これは画像の一部を修正する方法を使って実現しました。
画像の一部を修正する場合、以下の4つを指定します
元の画像
テキスト
文字列優先度(画像とテキストのバランス)
マスク画像
一部修正の場合のテキスト
基本的な話は、画像から画像作成の場合と同じですが、修正に関係ない箇所の情報は省いても問題ない場合があります。
例えばメガネ追加する場合、ポニーテールという情報は必要か微妙なラインな情報です。
今回の場合は前髪がメガネにかかっているので、髪の情報は必要でしたが、髪型によっては入れないほうが良い結果になる場合もあります。
別の例として、服装を変更する場合ですと、ポニーテールの情報は無くても問題ないです。
マスク画像
マスク画像とは、変更したい部分を指定するための画像です。
変更したい部分を白く塗って、他を黒く塗ります。
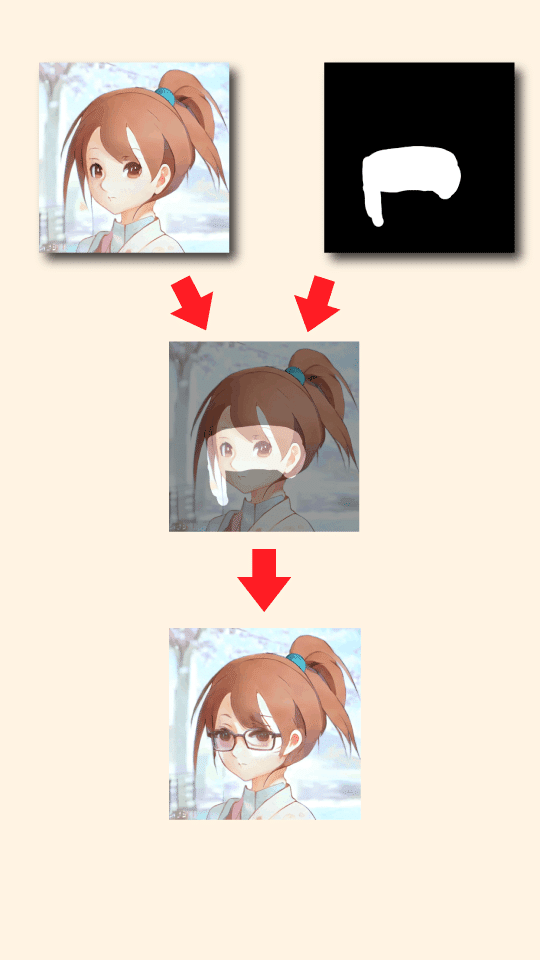
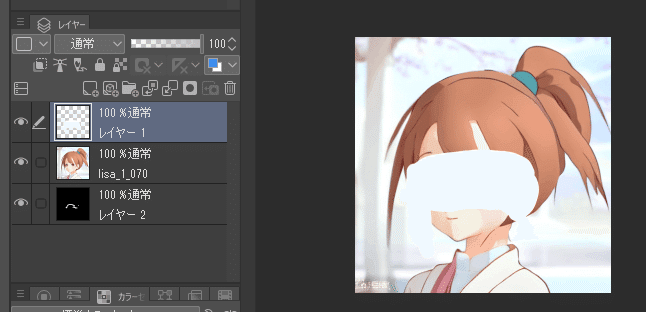
マスク画像の作り方は、お絵かきソフトにて↓のようにサンドイッチする感じでレイヤーを配置し、元画像を非表示にして画像書き出しすれば簡単に作れます。
そして、実際に画像の一部修正を行ったコマンドが↓のコマンドです。
for strength in [0.60, 0.65, 0.70, 0.75]:
dc.inpainting("lisa_face_22_glass_2/" + str(strength), 10, strength, 512, 512, "lisa_2_070.png", "lisa_1_070_mask2.png", "Short ponytail girl face with brown hair wearing red glasses. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k")画像の一部修正も、一発で思い通りの内容を変更してくれるわけではないので数を生成するのが良さそうです。
ちなみに、これはあとから気づいたことなのですが、画像の一部修正は、無から画像を補填するのではなく、元々書かれた内容を元に、新規作成を行うようです。
なので、新しい要素を追加したい場合には、その要素を大雑把にでも描いておくと、結果が良くなる可能性がありそうです。
メガネの場合でいうと、下手でも良いのでメガネを書き加えてから一部修正を実行したほうが、よりメガネを描いてくれる可能性が高くなった気がします。
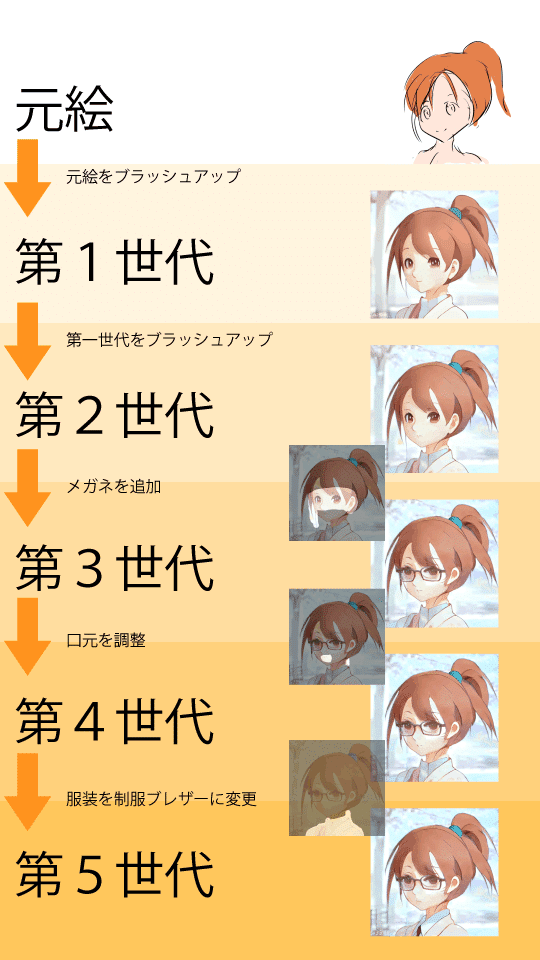
実際に使った画像まとめ
実際に完成までに使った画像の一覧が以下のとおりです。
各世代ごとに50~数百枚画像を作成した感じです。
実際に使ったコマンドまとめ
参考までに、最終的に世代ごとに使ったコマンドを並べておきます。
実際には、テキストやマスク画像はいくつかパターン作って試行錯誤していたので、この数倍のコマンドを打っていたと思います。
# 下書き→第1世代
for strength in [0.6, 0.65, 0.7, 0.75, 0.8]:
dc.img2img("lisa_face/" + str(strength), 10, strength, 512, 512, "lisa.png", "Short ponytail girl face with brown hair. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k.)
# 第1世代→第2世代
for strength in [0.6, 0.65, 0.7, 0.75, 0.8]:
dc.img2img("lisa_face/" + str(strength), 5, strength, 512, 512, "lisa_1_070.png", "Short ponytail girl face with brown hair. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k")
# 第2世代→第3世代(メガネ装着)
for strength in [0.60, 0.65, 0.70, 0.75]:
dc.inpainting("lisa_face_22_glass_2/" + str(strength), 10, strength, 512, 512, "lisa_2_070.png", "lisa_1_070_mask2.png", "Short ponytail girl face with brown hair wearing red glasses. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k")
# 第3世代→第4世代(口元補正)
for strength in [0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80]:
dc.inpainting("lisa_face_3/all3/", 10, strength, 512, 512, "lisa_3_65.png", "lisa_3_65_mask3.png", str(strength) + ": Short ponytail girl is smiling. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k")
# 第4世代→第5世代(服装変更)
for strength in [0.55, 0.575 , 0.60, 0.625, 0.65]:
dc.inpainting("lisa_face_3/mask4/" + str(strength), 20, strength, 512, 512, "lisa_3_65.png", "lisa_3_65_mask4.png", "Japanese high school girl in blazer uniform. By kawaii anime girl, Makoto Shinkai, playstasion5, genshin,4k, 8k")今回のやり方で出来そうなこと・難しそうなこと
出来そうなこと
線画は多少かけるけど、色塗るのが苦手な人は着色ツールとしてStable Diffusionを活用するのはアリな気がしてます
また描きたい構図が決まっているなら、自分で下絵を描いて清書させるのはありかと思います。
例えば、RPGツクールでゲームを作る場合、顔アイコンや背景が必要になりますが、そういうのは頑張れば作れそうな気がします
難しそうなこと
ツールを使う人が想像もしていないような構図・配色の絵というのは、今回の方法では作るのが難しいと思います。
本当に絵が上手い人は、そういうところも美味かったりするので、AIでこれを乗り越えようとするのはまだ難しい気がします。
複雑な構図や言葉にし難いものなど、指示を文字に変換することが難しいものは画像の出力精度が下がる傾向があります。
例えば、特定のポーズを取らせたいとかそういうのは出来なくはなさそうですが、単に顔だけと比べると難易度が跳ね上がる感じです。
まとめ
以上、Stable Diffusionを使った落書き清書のやり方まとめでした!
わたし自身、この方法をまだ1回通してみただけなので、わかんないことも多いですし、もっと改善できる点があると思います。
ぜひ、みなさんもStable Diffusionの良い使い方見つけたら、note書くなりTwitterでつぶやくなりして、くれると嬉しいです!
あと、誰かwiki作ってナレッジまとめて欲しいです!
この記事が気に入ったらサポートをしてみませんか?