
ChatGPTに共通テスト(旧センター試験)を解かせてみた

最近流行りのChatGPT。
「色々な作業を自動化した」
「国家試験に合格した」
ニュースで目にする機会も最近は多いと思います。
では、ChatGPTは現段階でどのくらい賢いのでしょうか?
「海外の司法試験で人間を超えた」などの情報をよく耳にしますが、実感が湧きませんよね。
今回は日本人に馴染みの深い大学入学共通テスト(旧センター試験)を題材に、その実力を検証してみました。
実験方法
今回は、令和4年度の国語・英語(リーディング)・公民(倫理 / 政治・経済)の3科目について実験を行いました。
※ 数学・理科等の科目については図表を読み取る問題が多く、正確に試験できないため今回は除外しました。
ポイント①: テキストになおす
大学入試センターで公表されている試験問題がPDFのため、ChatGPTに読めるテキスト形式にする必要があります。
今回はGoogle Docsの機能を活用して文字起こししました。改行ずれなどが発生するので、手動で修正作業を行いました。
ポイント②: 傍線部を読み取らせる
共通テストは本文+問題の形式が多く、本文中の箇所を傍線①など指定されます。
文字起こしした問題からは傍線の情報が抜け落ちるので一工夫が必要です。今回はマークダウン記法の太字表記「**」を活用してみました。
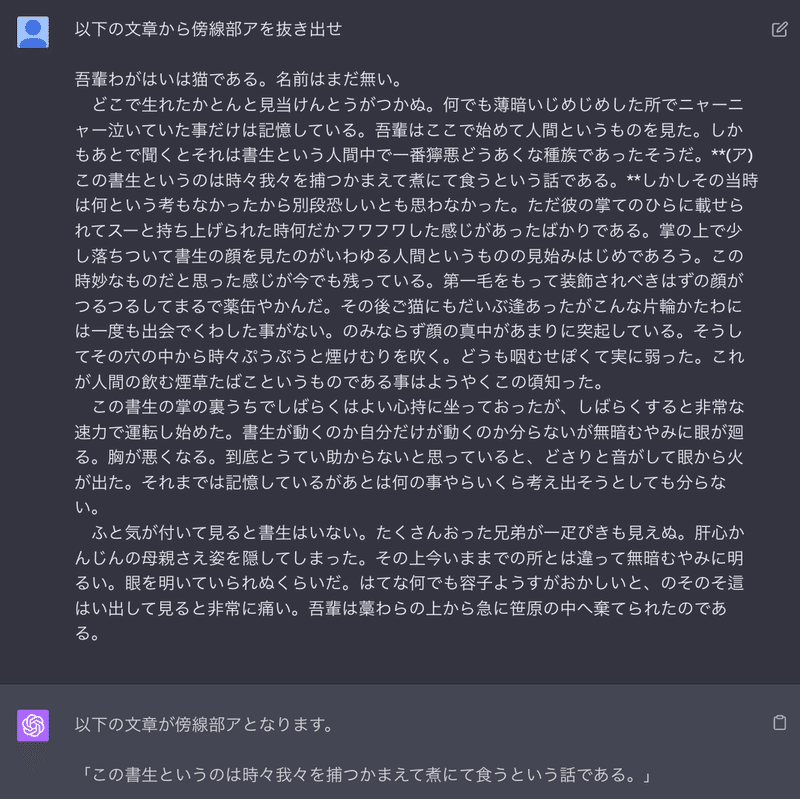
ちゃんと伝わっていますね!
準備が整ったので、実際にやっていきましょう!

さぁ、気になるテストの結果は…?
結果:GPT-4がヤバすぎる
試験の結果がこちらです。
なんと、GPT4が英語・倫理政経において8割越えの得点率を叩き出し、合計でも受験者の平均よりも若干高いという結果になりました。得点率8割と言うと難関大学合格が見えてくるラインですね。

まさか、AIが全国の受験生の大半よりも賢い…?!
一方で、GPT3.5の得点率は伸び悩みました。GPT4とGPT3.5でこんなにも差があるとは驚きです。表を見てみると次のような傾向があることに気づきます。
英語はGPT3.5も4も受験者平均を大きく上回っている
国語と倫理政経はGPT3.5と4の間で大きな開きがある
GPT4も国語は得点率が高くない
次節ではこれらのポイントについて掘り下げていきます。また、全設問の正誤一覧はこの記事の最後に付録として置いてありますので気になる方は是非ご覧ください。
深掘りタイム
どうしてこのような結果になったのか、少し詳しくみていきましょう。
1. 英語はGPT3.5も4も受験者平均を大きく上回っている
こちらの原因については以下が有力でしょう。
英語はネイティブスピーカー目線だと問題がそれほど難しくない
ChatGPT自体が英語での性能が高い
前提として共通試験は、日本語を母語とする方向けの試験であり、英語の試験は非ネイティブ向けに作られています。
全て日本語訳された状態で問題を見てみるとわかりますが、問題のレベルはそれほど高くありません。
また、ChatGPTが学習しているネット上の文献は50%以上が英語で書かれており、原理的にChatGPTは英語能力に長けています。
間違えた問題は長文から読み取って数値計算をするものや時間的順序を把握するもので、これらはChatGPTの性質的に苦手と言われているものでした。
2. 国語と倫理政経はGPT3.5と4の間で大きな開きがある
GPT4で正解したのに3.5で間違えた問題を比較してみると、国語は読解全般、倫理政経は会話文の補充が目立ちました。
いずれも登場人物の立場や文脈を考慮して論理を整理するような処理が必要となり高度な知能が要求されます。

引用:大学入試共通テスト令和四年度本試験 倫理,政治・経済
また倫理政経については知識問題の間違いも目立ちました。以下の問題は年号を正しく把握していれば正解できる問題で、GPT4は正解していましたが3.5では誤答をしていました。

まとめると、今回見えてきたGPT3.5と4の差分は以下になります。
読解系の問題は3.5だとかなり精度が低い
事実の正確性もGPT4の方が高い
3. GPT4でも国語は得点率が高くない
国語の問題は現代文・古文・漢文に分かれますが、それぞれの得点がこちらです。

評論文以外は壊滅的でした。代表的な間違いを見てみましょう。
評論
かなり正答率の高かった評論ですが、驚いたことに、間違えた問題は語彙問題でした。

「ジョウチョウ→上等」や「ジョウカ→除去」「カンショウ→勧誘」など、ChatGPTは言い回しとして正しそうなものを予測して出力するモデルなので、読み方を固定するような制約はかけにくいものと思われます。
文脈が不足しているのではないかと考え、実験してみましたが違うみたいでした。

それ以外はGPT4はほぼパーフェクトだったので、やはり情報整理能力は高いと言っていいでしょう。
小説
36%と正答率が低かった小説ですが、こちらは評論と異なり勝手な解釈が多く見られました。
センター試験は原則として本文中に根拠となる箇所が存在し、誤りの選択肢には明らかな間違いがあります。ところがChatGPTの回答を見ていると、特に心情把握において傍線部の言葉から勝手に解釈を広げてしまっていました。
部分的にはそう解釈できなくもないが、前後をきちんと読むと間違っている、というような広げ方をしており、たまたま正解した問題もありましたが、正しく理解できているとは言えないでしょう。
ChatGPTは文章を理解しているわけではなく、文章としてつながりの良い言葉をうまく選んできているという仕組みです。
そのため、文学的に表現された心情を正しく把握するのはまだ難しいのかもしれません。
古典(古文漢文)
3〜4割程度とという低い得点率となった古典ですが、その原因としては文献が少なく、精度が下がってしまっていることが挙げられるでしょう。
例えば、漢文における「書き下し文」は漢字のみで書かれた文章を古文として読める形式に直された文章のこと。
ですがこの部分について切り出して実験してみると残念ながら現代語訳してしまいました。

また、古文については逐語訳(一言一句正しく訳すこと)が求められる問題も多いですが、翻訳の精度が低く、誤答をしてしまう問題が見受けられました。
下の例だと「せちに」や「已然形 + ば」などが現代語訳に反映されていません。

このようなことの積み重ねで古典は全体的に文意を正しく理解できず、正答率が低い結果となったようです。
以上をまとめると国語の点数がGPT4でも低かった原因は
カタカナを漢字に直せない
登場人物の気持ちを把握して整理するのは苦手
古典の学習量が少ない
といったところになると考えられます。
重要な注意点
ChatGPTの思考回路を出力させることで気づいたのですが、実はGPTくん、すごく堂々と間違えてしまっています。いくら便利だからといって人生がかかっていると言っても過言ではない受験勉強には使わないほうがいいでしょう。
(もちろん、一般的な現象や日々の疑問などについてはわかりやすく答えるので、好奇心を探究するときには便利です)
以下は憲法関連の判例について堂々と嘘をついてしまっている例です。

まとめ
今回は、今話題のChatGPTに大学入学共通テストを受験させ、性能を確かめてみました。その結果、各問題でGPTの得意不得意が如実に現れる様子が確認できました。
このような実験を通して改めてAIのおもしろさをおわかりいただけたのではないでしょうか。
個人的所感としては、共通テストはセンター試験と比べても思考力を試される問題が増えていて、ChatGPTにとって難易度が高かったのかなと思っています。もしかしたら過去の大学入試センター試験の問題ならもっと得点が伸びたかもしれません。
最後までご覧いただきありがとうございました。もしよろしければスキやシェアをお願いいたします!
また、メディア関係者の方で本noteをテーマに記事を作りたい!という方がいれば是非連絡くださいませ。喜んで取材に応じさせていただきます。
P.S
毎日Twitterで国内外のAIを触って感想を呟いています。是非感想教えてください。
https://twitter.com/usutaku_com
付録
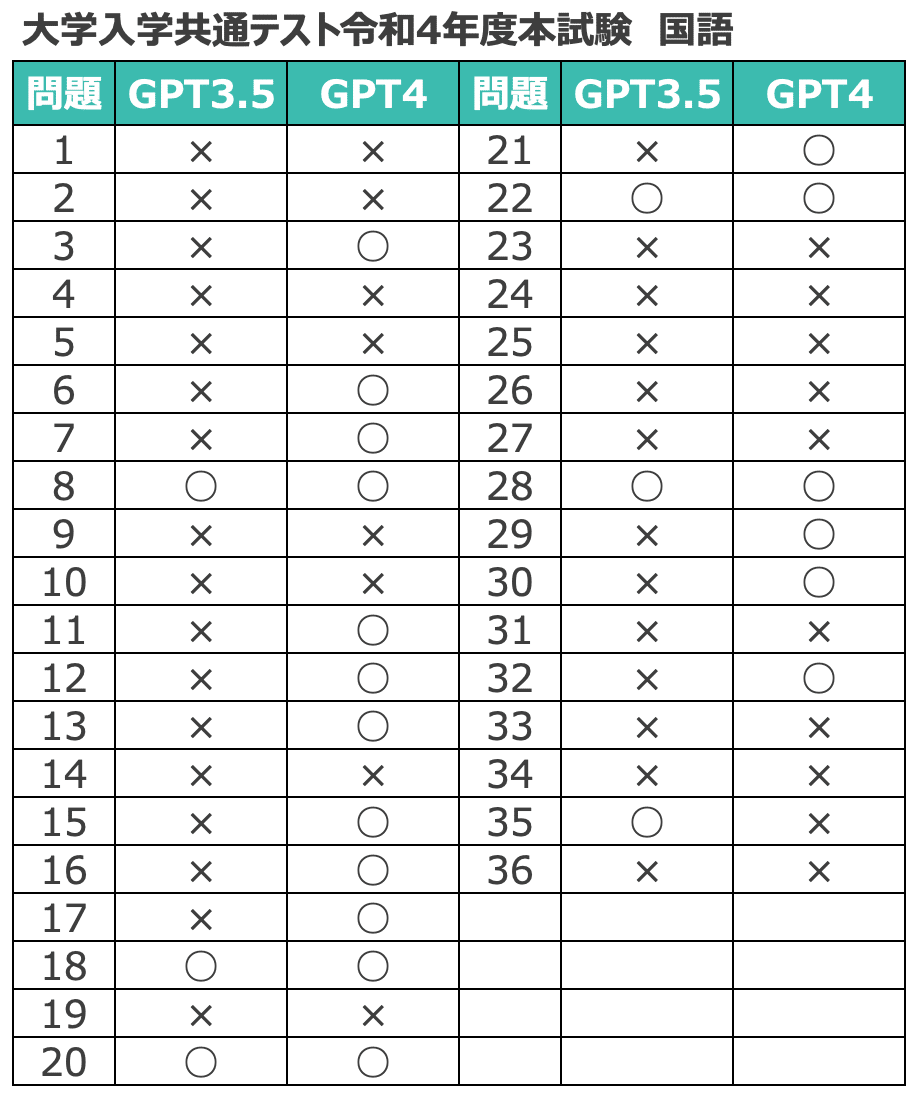
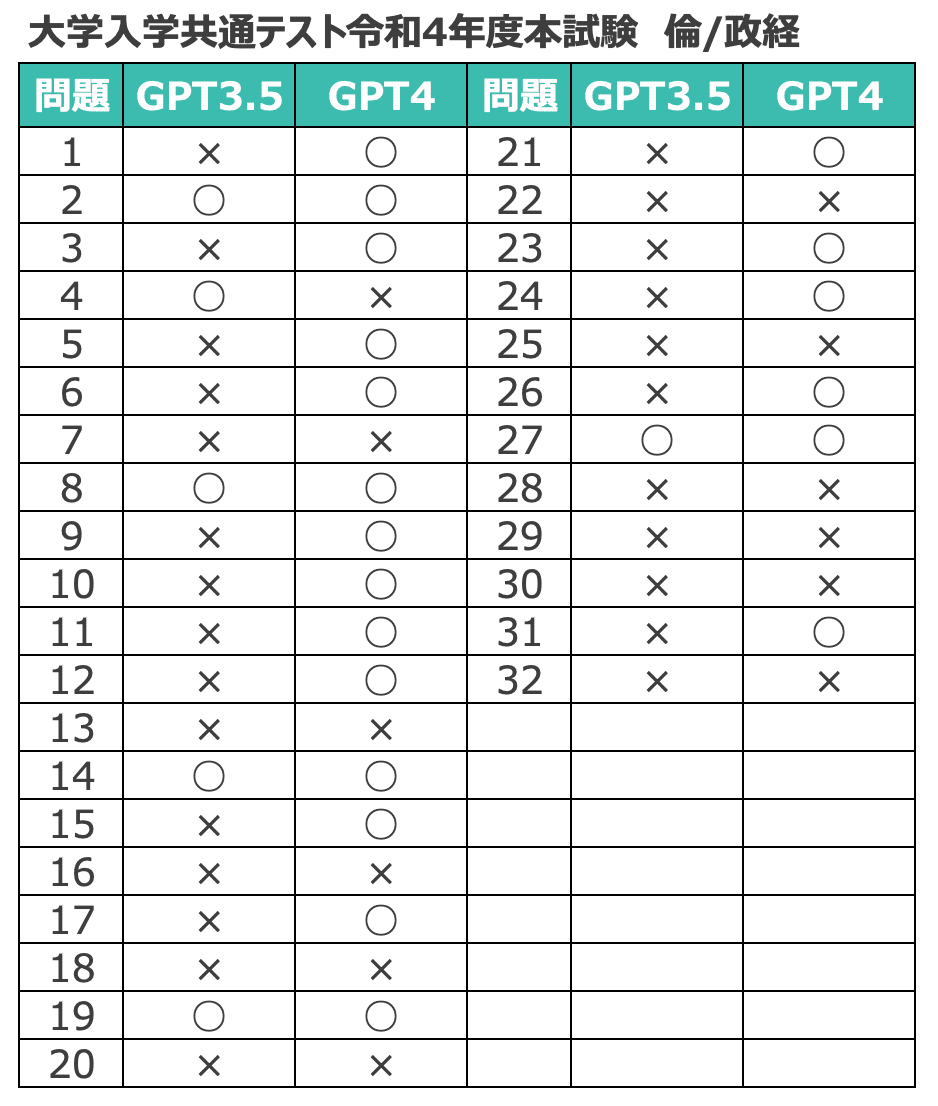
各教科の、問題ごとの正誤を貼っておきます。
興味のある方は、どの問題をGPT3.5、4がそれぞれ間違えたのか確認してみてください。

最後までご覧いただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?