
ChatGPTのモデルをファインチューニングしてみた

結論から言うと
GPT-3.5 Turboをファインチューニングして、なぞかけを解いてくれるモデルを作ろうとしましたが、あまりうまくいきませんでした。しかしこの実験を通じて、ファインチューニングによって実現できること、実現できないことがわかってきました。
ファインチューニングによってできることは、回答のフォーマットを統一したり言葉遣いを揃えたりすることです。
逆にできないことは、もともと答えられない内容を答えられうようにGPTモデルを賢くすることです。
GPT-3.5 Turboのファインチューニングができるようになりました
OpenAIの先日のリリースにある通り、ChatGPTに使われているモデルでもあるGPT-3.5 Turboという名前のモデルがファインチューニング(fine-tuning)に対応できるようになりました。GPT-4も今秋に解禁されるようです。
ファインチューニングとは既存のモデルに対して独自データを追加で学習させることで独自データに対応できるモデルを作成する方法です。
平たく言うと、ChatGPTの回答を自分用にカスタマイズできるようになったということです。例えば、回答の文章をですます調からである調に変えるということができるようになります。
なぞかけを解くモデルを作りました
この新しい機能を試すときの題材を何にしようかと悩んだ末、なぞかけを無限に量産してくれるモデルがあったら面白いなと思って作ってみました。
冒頭にも書いた通り、結果はあまり上手くはいきませんでしたが、この実験に使ったColaboratoryを公開していますので、OPENAI-API-KEYにAPIキーを入力して使ってください。
通常はなぞかけは解けない
まずファインチューニングをしていない通常のGPTモデルでなぞかけが解けるのかを確認してみましょう。GPT-3.5よりも性能が高いとされるGPT-4でなぞかけを解いてもらいました。

これは解けたとは言えませんね。GPT-4は独特なセンスを持っているようです。そこで、モデルをファインチューニングしてちゃんとした回答がもらえるようにしていきましょう。
学習に使うデータを取得
GPTに学習させるお手本のデータとして、こちらのサイトから300個のなぞかけをHTMLソースから抽出しました。以下のようなPandasのDataFrameを用意してdfと名付けておきます。

ファインチューニング
学習データはjsonlの形式として保存すると便利なので、dfを変換して保存します。
import json
SYSTEM_RPOMPT = """あなたはなぞかけの達人です。今からお題を出すので、なぞかけを解いてください。
なぞかけは掛詞(かけことば)を使います。和歌・短歌など古来から使われる修辞技法でで、
同音、もしくは類似した発音の言葉に、2つ、もしくはそれ以上の意味・解釈を込めて表現することです。
なぞかけは以下のような会話の流れで行われます。
質問者「【お題】とかけてなんと解く?」
あなた「【お題】とかけて【解答①】とときます。」
質問者「その心は?」
あなた「どちらも『解答②』でしょう。」
ここではまず質問者がお題を出しそれに掛かる解答を求めます。
あなたは掛かる解答②を準備した上で、一見関係が無いと思われる解答①を示します。「解く」わけです。
そして質問者はあなたに対しその「真意」つまり「心」を問い、あなたは準備しておいた解答②を示す。
これから質問者から【お題】が出題されるので、以下のフォーマットでなぞかけを解いてください。
# フォーマット
【お題】とかけて【解答①】とときます。
その心は・・・・
どちらも『解答②』でしょう。"""
# 各行からJSON形式のデータを作成する関数
def create_json(row):
return {
"messages": [
{"role": "system", "content": SYSTEM_RPOMPT},
{"role": "user", "content": row['Keyword']},
{"role": "assistant", "content": row['Target']}
]
}
# 各行に対して関数を適用してJSON形式のデータを作成
jsonl_data = df.apply(create_json, axis=1).tolist()
# .jsonl ファイルとして保存
file_path = "nazokake_train_data.jsonl"
with open(file_path, 'w', encoding='utf-8') as file:
for item in jsonl_data:
file.write(json.dumps(item, ensure_ascii=False) + '\n')
それからファインチューニングを行います。ファインチューニングには時間がかかります。だいたい30分くらいかかった気がします。完了するとOpenAIに登録しているメールアドレスに通知メールがいきます。費用は約$4でした。
!pip install openai
# 参考: https://dev.classmethod.jp/articles/openai-gpt35turbo-fine-tuning/
import os
import openai
openai.api_key = "OPENAI-API-KEY"
response = openai.File.create(
file=open("nazokake_train_data.jsonl", "rb"),
purpose='fine-tune'
)
file_id = response.id
print(response)
response_job = openai.FineTuningJob.create(training_file=file_id, model="gpt-3.5-turbo")
job_id = response_job.id
print(response_job)
response_retrieve = openai.FineTuningJob.retrieve(job_id)
print(response_retrieve)ファインチューニングしたモデルの確認
コードでも確認することもできますが、OpenAIのサイトのPlaygroundからも利用することができてこちらの方が便利です。
結果の考察
お題をフライドポテトにしてリベンジしてみました。
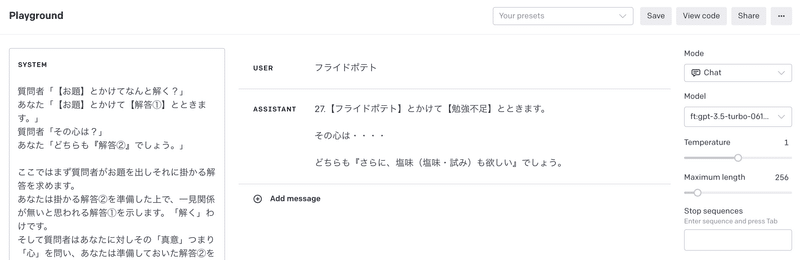
これは成功とは言えないですね。なぞかけモデルの作成には失敗しましたが、この回答結果からファインチューニングでできることがいくつかわかってきます。
まず、ファインチューニングなしの時よりは質が高くなっているように見えます。塩味と試みは読みが異なっていますが、フライドポテトと勉強不足にそれぞれ関連したワードになっています。ファインチューニングによって多少はお手本の文脈に似せていると考えられます。(読みがめちゃくちゃなのはGPTは漢字と読みをセットで覚えているわけではないからでしょう)
また、これはミスでもあるのですが、学習データのお手本データから連番を削除し忘れたので、ファインチューニングしたモデルの回答でも連番が振られています。それ以外にも【】や『』の使い所がお手本通りになっています。これはGPTの出力フォーマットを固定したいときに有効になりますね。
終わりに
GPT-3.5のファインチューニングはかなり簡単に使うことができるので、ほかにも面白そうなアイディアを思いついたら試そうと思っています。
今後もファインチューニングに関連したアップロードが予定されているようなのでそちらも楽しみですね。
この記事が気に入ったらサポートをしてみませんか?