
ControlNetのモデルの種類・使い方14つ / Stable Diffusion

ContorolNetのモデルの種類と各々の使い方についてのメモです。
輪郭抽出(線画)でポーズしたい時 / canny
初心者でも使いやすく、一番忠実にポーズ指定ができる。
人物などの輪郭を保ったまま、プロンプトで一部分を変更したい時にもおすすめ。
プリプロセッサ:canny
モデル:control_canny-fp16
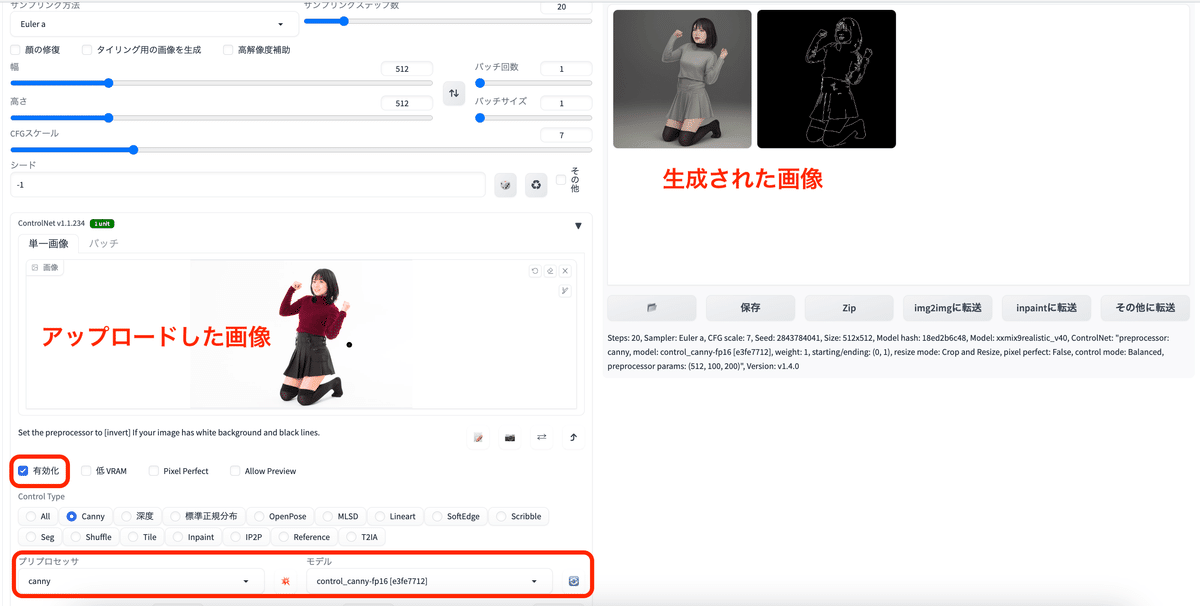
ポーズに加えて、顔や髪型・服装も類似して生成しやすい。
抽出された輪郭画像も同時に出力されるため、保存をして画像を再利用できる。
アップロードした画像

生成された画像(プロンプト無し)

生成された輪郭画像

骨格検出でポーズ指定したい時 / openpose
元画像から棒人間を抽出し、ポーズ指定できる。
洋服や背景は全く別のものが生成されるため、ポーズだけ反映させたい時に使用する。
プリプロセッサ:openpose_full
モデル:control_openpose-fp16
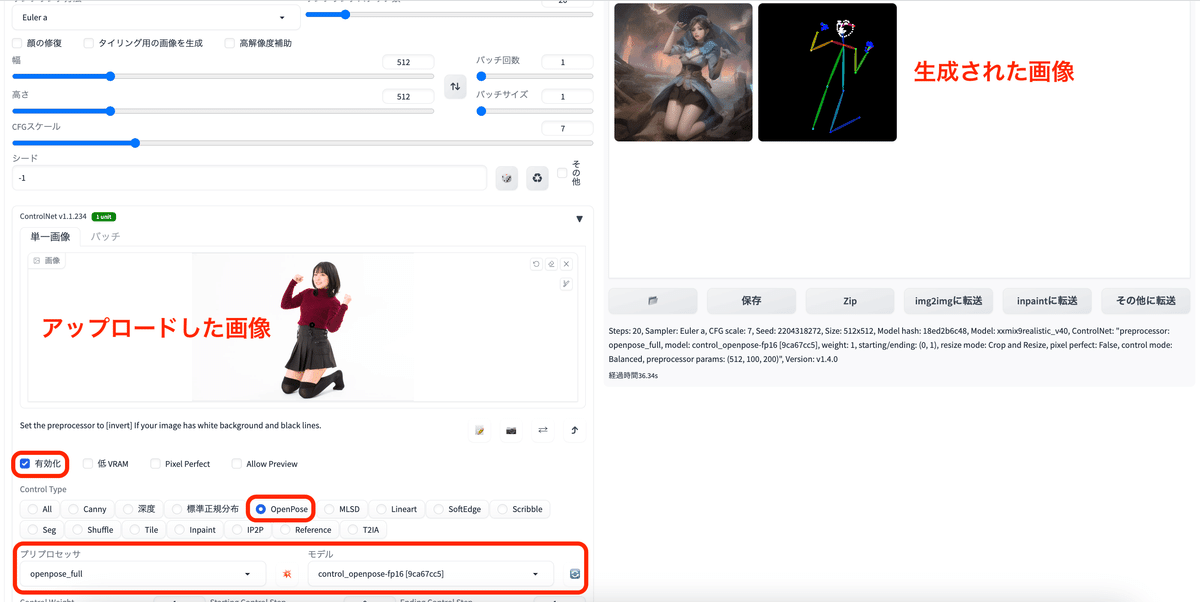
骨格の抽出画像も生成されるため、保存をして画像の再利用ができる。
アップロードした画像

生成された画像

生成された骨格画像
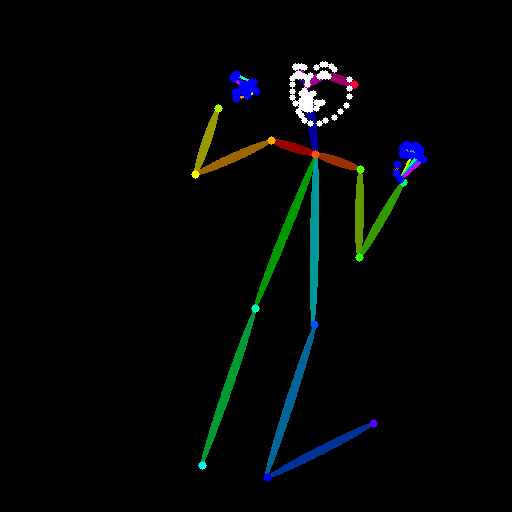
棒人間でポーズ指定したい時
先ほど生成した棒人間の画像を使って画像を生成するには、プリプロセッサはnoneにして、モデルはopenposeを使用する。
プリプロセッサ:none
モデル:control_openpose-fp16
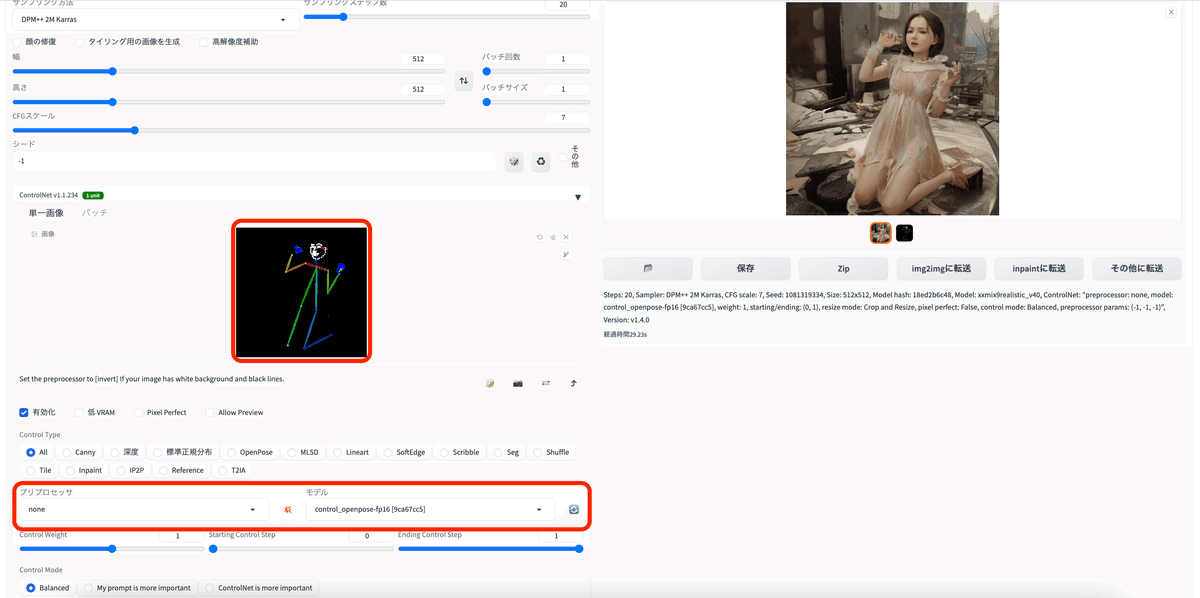
アップロードした画像
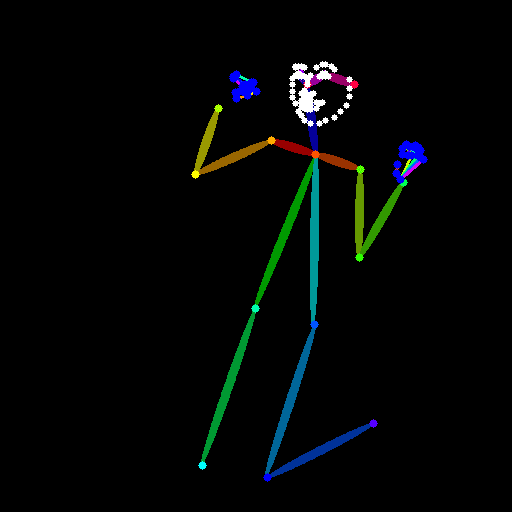
生成された画像 (プロンプト無し)

一部分だけ編集したい時 / inpaint
一部分だけ編集したい時に使用する。編集したい箇所をwebページ上の黒色のペンで塗りつぶす。
プリプロセッサ:inpaint_only
モデル:control_v11p_sd15_inpaint
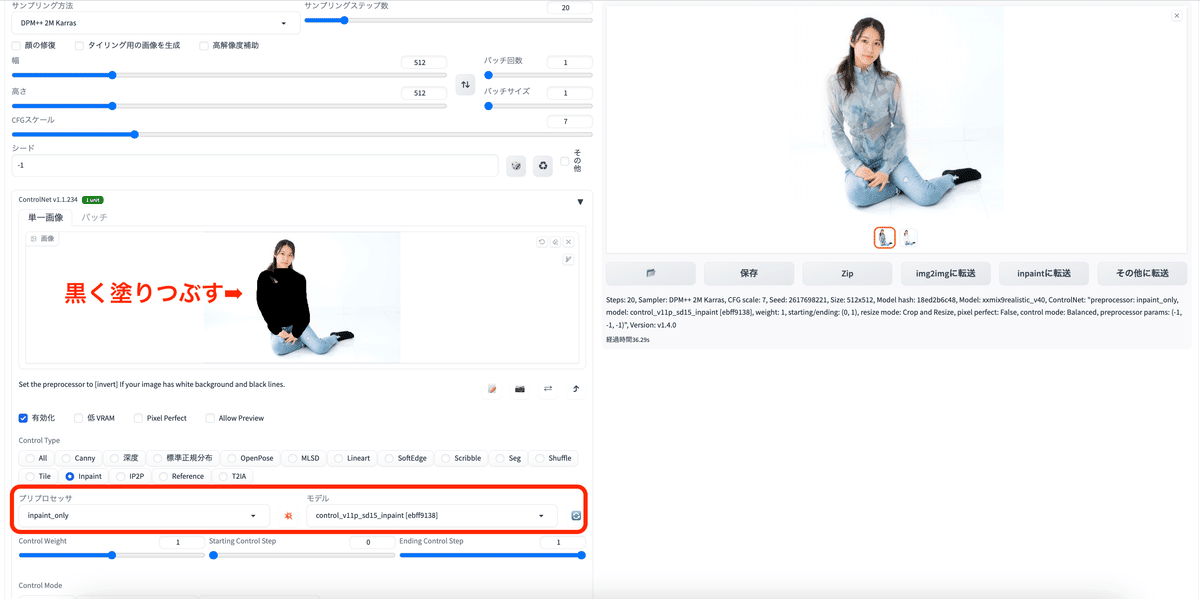
アップロードした画像

黒く塗りつぶした画像

生成された画像

高画質化したい時 / tile
画像を拡大して高画質化してくれる。拡張機能の『Tile Diffusion』と合わせて使うのがおすすめ。
プリプロセッサ:tile_resample
モデル:control_v11p_sd15_tile
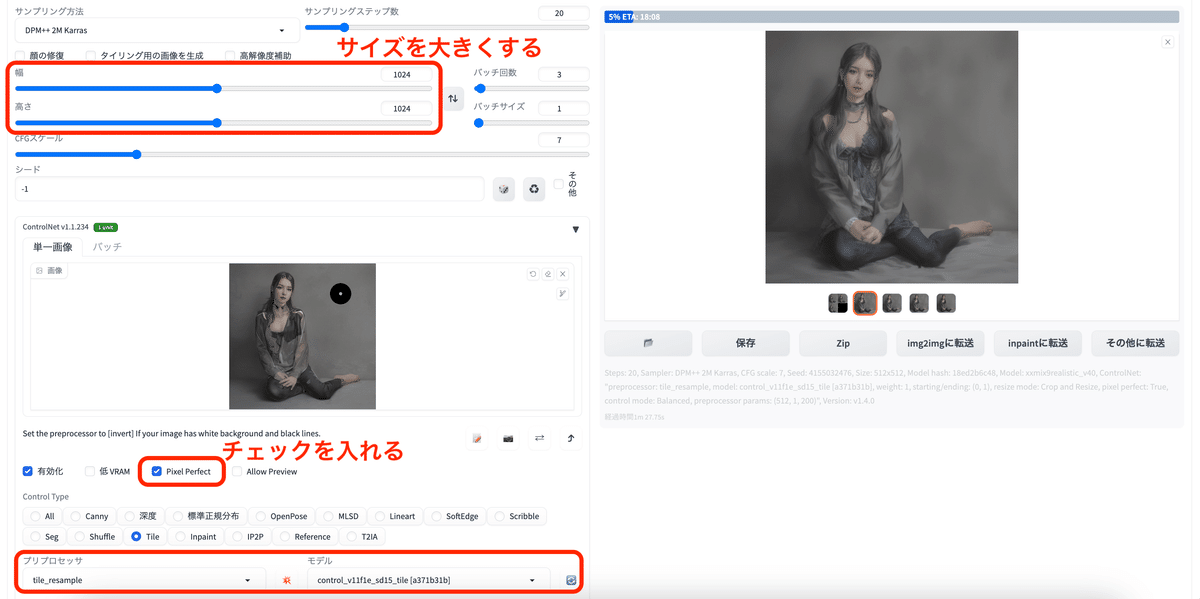
tileで512px✖️512pxで生成した画像

tileで1024px✖️1024pxで生成した画像

同じ顔を引き継いで生成したい時 / reference
アップロードした画像の顔を引き継いで色々な画像を生成できる。
プリプロセッサ:reference_onty
モデル:なし
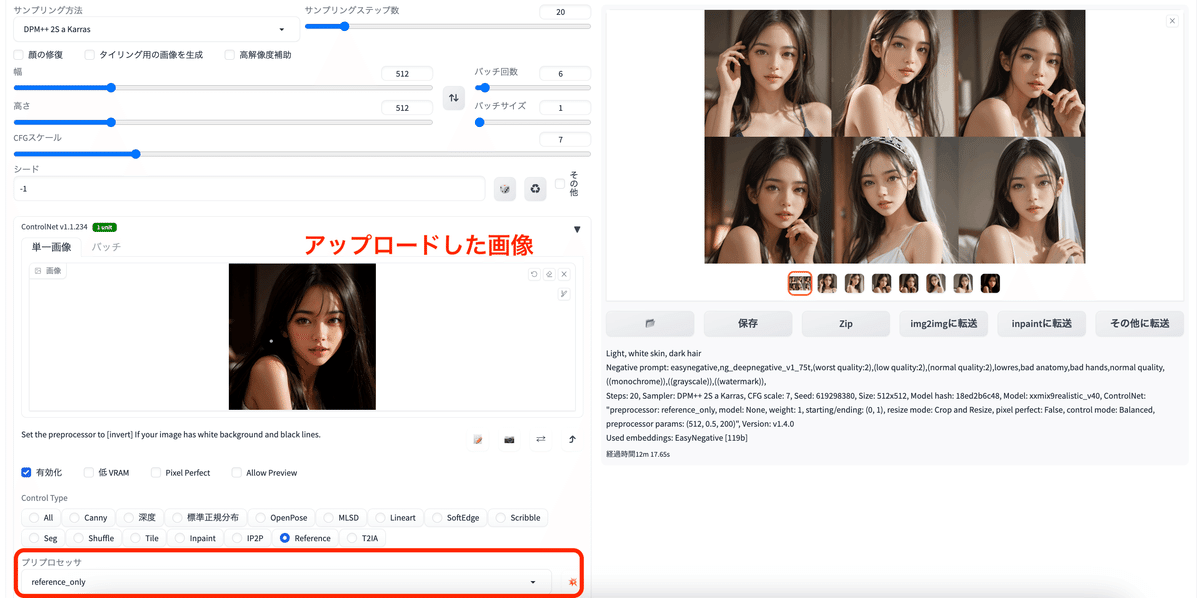
アップロードした画像↓

生成された画像↓

イラストの線画から抽出したい時 / Lineart
イラストから抽出した線画をベースに画像を生成する。
線画の画像を使えば、ControlNetで色塗りができる。
▼ Lineartのプリプロセッサの種類
① lineart_anime
② lineart_anime_denoise
③ lineart_coarse
④ lineart_realistic
⑤ lineart_standad(from white bg & black line)
プリプロセッサ:Lineart_Anime
モデル:control_v11p_sd15s2_lineart_anime
アップロードした画像

生成された線画の画像

生成した線画を利用して、色塗りをし直すやり方
①先ほど生成された線画をアップロード
②プロプロセッサをnone、モデルをcontrol_v11p_sd15s2_lineart_animeにする
③プロンプトを入力して調整する
④元画像をseedで固定している場合は、seed数値も入力するとより忠実に生成できる
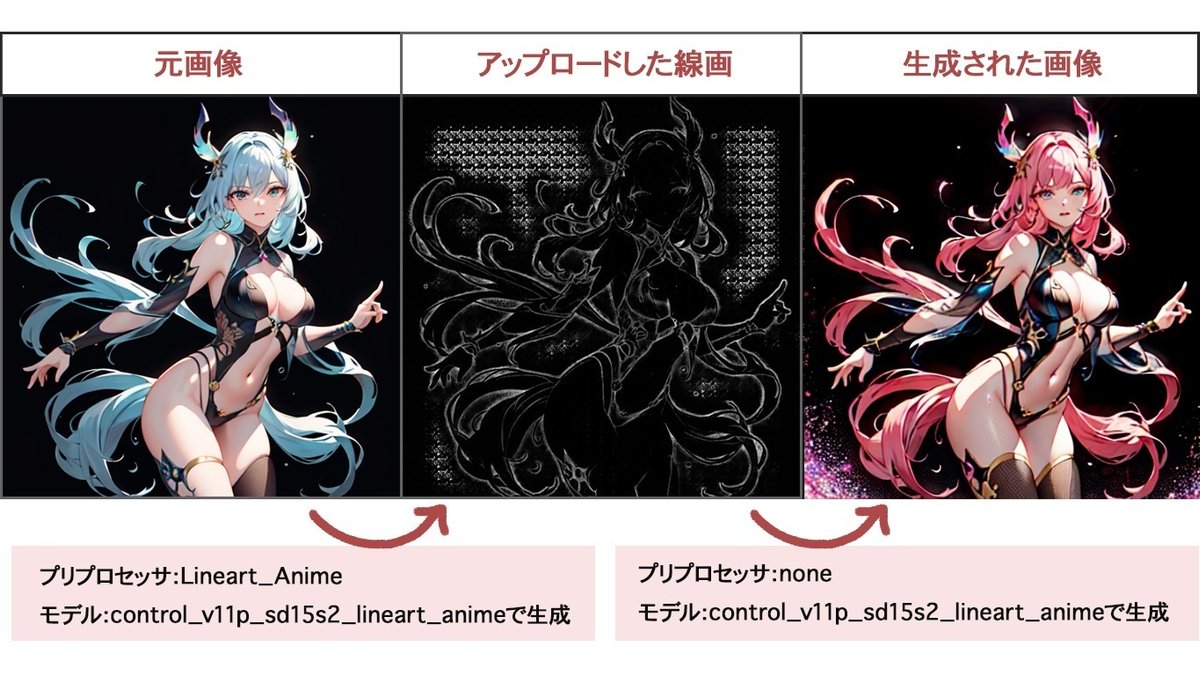
Lineartの比較


線の太さや色味の質感の違いが楽しめる。
線画を忠実に抽出したい時 / Soft Edge
イラストの線画を抽出してくれる。cannyやLineartよりもより細かな細い線を抽出してくれ、より元画像と似せて生成してくれる。
▼ プリプロセッサの種類
softedge_hed:元画像に最も忠実な線画を抽出してくれる
softedge_hedsafe:softedge_hedより抽出精度を下げ、不自然にならないようにしてくれる
softedge_pidinet:softedge_hedより細かく線を抽出してくれる
softedge_pidisafe:softedge_pidinetより精度を下げ、不自然にならないようにしてくれる
モデル:control_v11p_sd15_softedge

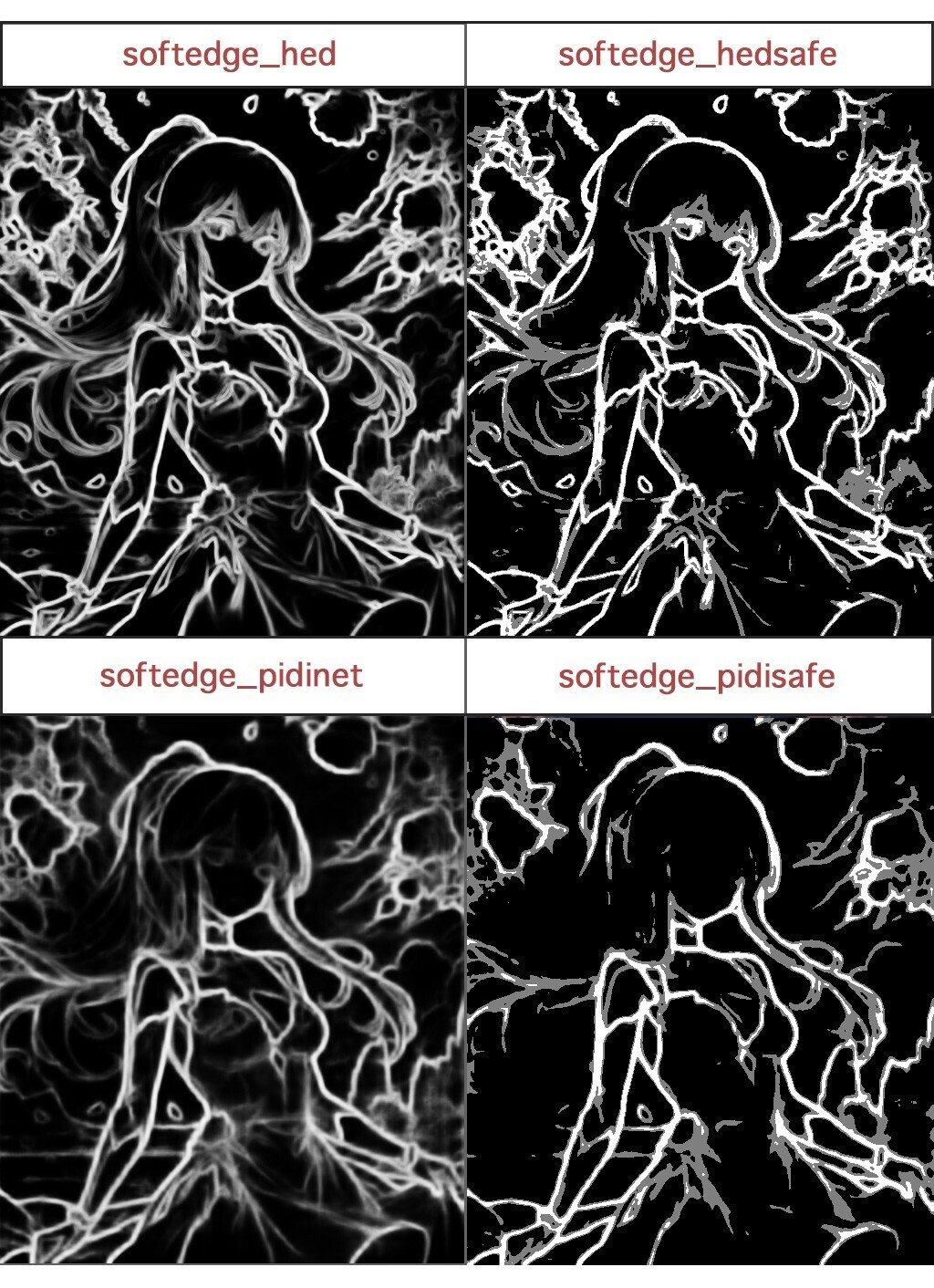
SoftedgeとLineartの使い分け
・元絵に忠実な線画を再現したい時はsoftedgeがおすすめ
・背景はランダムで生成したい、細かいディテールは必要ない場合はLineartがおすすめ
深度情報からポーズ指定する時 / Depth
奥行きを正確に抽出しやすい。
深度は手前が白色・奥にいくほど黒色で表現される。(深度マップ)
depthの種類
・depth_leres
・depth_leres++
・depth_midas
・depth_zoe
モデル:control_v11f1p_sd15_depth


下記のように、色塗りの調整もできる。

元画像のテイストを維持したい時 / Shuffle
元画像のテイストを維持したまま、新しく画像を再構成できる。
1枚の画像をLoRAのように再利用できるイメージ。
プリプロセッサ:shuffle
モデル:control_v11e_sd15_shuffle

このように、色味のテイストが類似されて生成される。


ラフ画からイラストを生成したい時 / Scribble
ざっくりしたラフ画からイラストが生成できる。
大まかな構図や配置を指示したい時におすすめ。
プリプロセッサ:Scribble
モデル:control_scribble-fp16
アップロードした画像↓(へたっぴでごめんなさい)

生成された画像↓

このように、へたっぴでも構図を汲み取ってくれる。
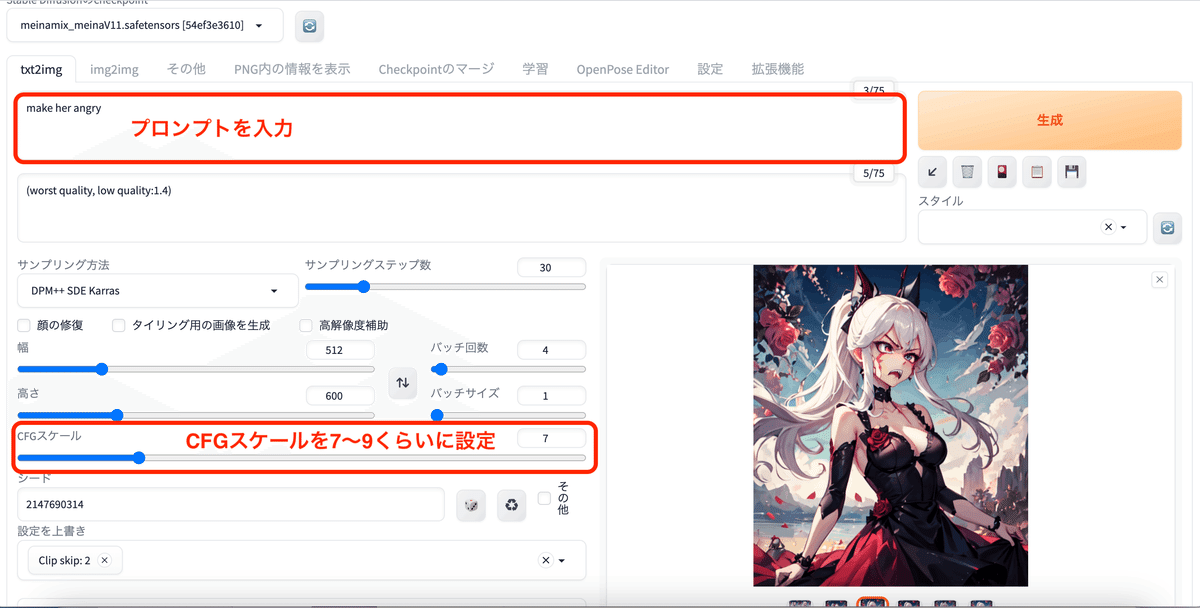
画像を固定して何度も編集したい時 / IP2P (Instruct Pix2Pix)
元画像を固定して、プロンプトの指示により何度も修正ができる。
CFGスケールを7〜9くらいに設定すると綺麗に仕上がる。
プリプロセッサ:none
モデル:control_v11e_sd15_ip2p
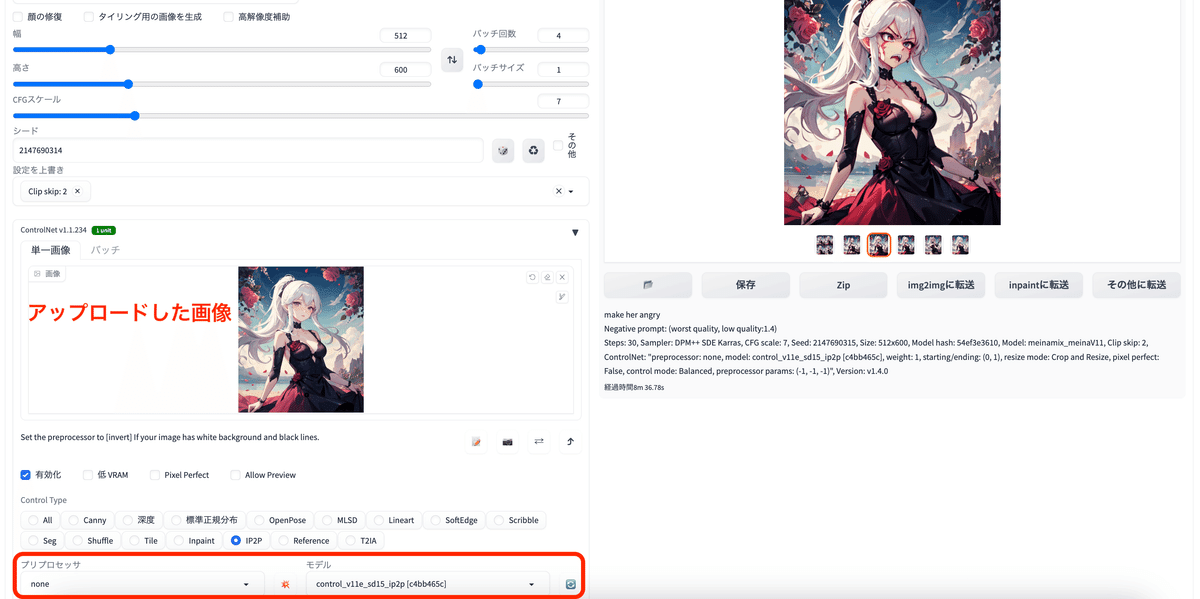
アップローした画像↓

プロンプト:Make her cry.

プロンプト:Make her angry.

直線的な背景を生成したい時 / MLSD
直線のみを抽出する機能。
部屋の内装や背景を生成したいときにおすすめ。
プリプロセッサ:mlsd
モデル:control_mlsd-fp16
アップロードした画像↓

生成された画像↓


生成された線画↓
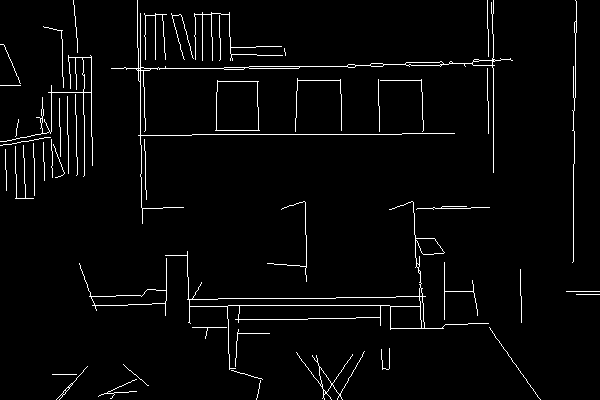
抽出された線画を利用すれば、再度画像の調整ができる。
プリプロセッサ:none
モデル:control_mlsd-fp16
アップローした画像↓ (先ほど生成した線画)
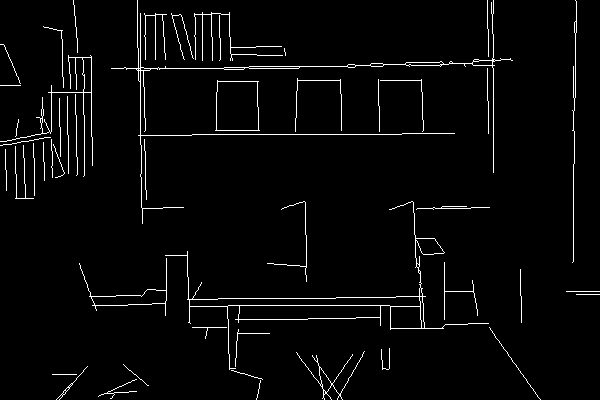
生成された画像↓
「カラフルで可愛い子供部屋」というプロンプトを入力。


パーツ分けして生成したい時 / Segmentation
どこに何が描かれているかを自動で検出して、パーツごとに色分けしてくれる。
構図や配置などは忠実に維持しながら、違うテイストの画像生成ができる。
人物を抽出するのは向いておらず、部屋の内装や背景の生成におすすめ。
▼ Segmentationの種類
・seg_ofade20k
・seg_ofcoco
・seg_ufade20k
プリプロセッサ:seg_ofade20k
モデル:control_seg-fp16
アップロードした元画像↓

抽出された画像↓

抽出された画像を使用して、再度画像を生成してみた↓
プリプロセッサ:none
モデル:control_seg-fp16


このようにパーツ分けされることで、構図や家具などは忠実に再現しながら、色んなテイストの画像生成を楽しめる。
プリプロセッサ:seg_ofcoco
モデル:control_seg-fp16

上記の抽出画像を利用して再度生成した画像↓

プリプロセッサ:seg_ufade20k
モデル:control_seg-fp16

上記の抽出画像を利用して再度生成した画像↓

法線マップから生成したい時 / Normal
元画像から法線マップを抽出して画像を生成する。
個人的にはあまり使い道がない。depthやSoft Edgeの方が元画像をより忠実に再現してくれる。
プリプロセッサ:normal_bae
モデル:control_normal-fp16

生成された法線マップ↓

このように、イラストが少し変わってしまう。
プリプロセッサ:normal_midas
モデル:control_normal-fp16

生成された法線マップ↓
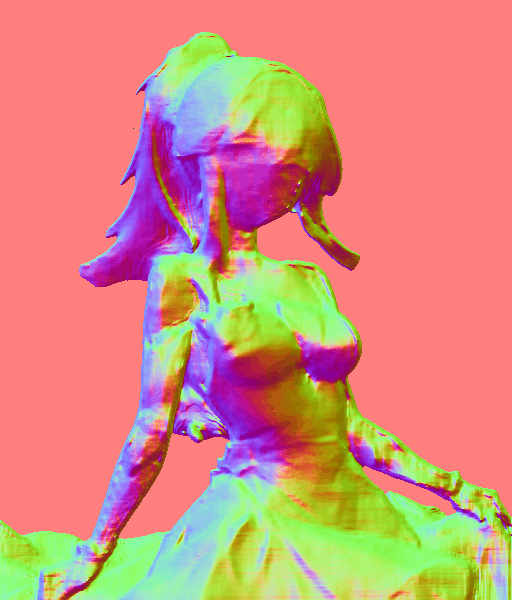
こちらのメモもオススメです↓
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?