
Courseraで"Data Engineering with Google Cloud Professional Certificate"を取得した話

Google CloudがCoursera上で提供するProfessional Certificateである"Data Engineering with Google Cloud Professional Certificate"を取得したので感想等を記します。
概要
Data Engineering with Google Cloud Professional Certificate
https://www.coursera.org/professional-certificates/gcp-data-engineering
1. 期間:2020年4月末から6月末(あくまで私の場合です)
2. 費用:5264円/月を二ヶ月分(同上)
3. 言語:英語(日本語版もあるようですが、字幕もついているしせっかくなので英語版でやりました)
複数のCourseを束ねたものがSpecializationだったりProfessional Certificateだったりするようです。このProfessional Certificateと内容が被るSpecializationとしてData Engineering, Big Data, and Machine Learning on GCP Specializationもあるのですが、Professional Certificateのほうが一つだけコースが多く、"Preparing for the Google Cloud Professional Data Engineer Exam"というものが含まれます。というわけで、Professional Certificateをやれば必然的にSpecializationも修了することになります。下の画像の通り、オファーされている数を見るとProfessional Certificateのほうがだいぶ少ないのでその分価値があるような気がします(?)が、実際のところどうなのかはわかりません。いずれにせよ、学ぶ内容が本質であって修了とかは飾りでしかないので、あまり重要ではないでしょう。
画像:https://www.coursera.org/browse/data-science
受講のモチベーション
機械学習などのデータサイエンスはその基盤となる計算資源や処理プロセスも非常に重要にも関わらず、それらをどのように使えばいいのかというデータエンジニアリングの情報は案外まとまったものが手に入らないように感じます。MLOpsとかいう言葉ももてはやされていますが、個別の応用的な情報にとどまっている印象が強いです。データ取得、前処理、保存、計算資源管理、監視、可視化等のプロセスを今風に行う方法は、どこで全貌が掴めるのでしょうか。この基盤としてのデータエンジニアリング部分の学習しづらさは、機械学習の具体的内容などデータサイエンス部分とは対照的に感じられます。「機械学習そのものをやるのはほんの一部で、そもそもデータを活かす環境整備が難しい」みたいなことが世の中で言われるのもうなずける気がします。
私自身はそもそも研究の過程でデータをあれこれ解析していただけということもあって、ローカルサーバに解析環境を作って自前でちまちまスクリプトを書いて切り盛りしてきてしまいました。きっと20年前と変わらないやりかた。あきらかに効率が悪いし、もっと大きなデータを扱うには困難があります。重たい計算はスパコンに投げるとしても、けっきょくその周囲の仕事のやりかたがあまりに洗練されていません。そういうめんどくささはクラウドでどうにかなるらしいことはよく耳にするところだし、いっちょやってみるか、という気持ちで受講しました。
懸念していたのは、ここで得る知識が個別のプロダクトの知識(今回で言えばGCP固有の、いわゆる「すぐ古くなる知識」)にすぎないのではないかということでした。ありがちな「このライブラリがどうこう」、「どのフレームワークがどうこう」みたいなものを追いかけてもキリがありません。今回は、もちろん第一義的には個別的な内容で構成される教材ではあるとはいえ、その向こうにより一般的な知見が見える部分も多く、振り返ってみると杞憂でした。
コース内容
1. Google Cloud Platform Big Data and Machine Learning Fundamentals
全体の概要にあたり、広く薄くいろいろな内容をカバーするコースです。これよりあとのコースの中身では次のコースがシリーズの最初であるかのようにしゃべっているので、あとから追加されたものなのでしょう。というわけで以後の内容よりも入門的にそもそもなぜクラウドを使いたいかという話が多いです。スケールが自由自在、管理の手間が少ない、信頼性が高い、など。常識なのかもしれませんが、印象的だったのはストレージと計算を分離できるのだというポイントでした。つまり、Google Cloud StorageとGoogle Compute Engineは非常に高速なネットワークで接続されているので、データをいつも計算サーバに用意しておく必要なく、随時Google Cloud Storageから取ってきてもボトルネックにはならない、だから計算インスタンスはそのつど削除できる、といった話です。サービスの細かいところの説明はさておき実践的にBig Queryを使ってみたりAutoMLで推薦エンジンを作ってみたりと次以降のコースよりも目まぐるしくいろいろなことをやる印象でした。
2. Modernizing Data Lakes and Data Warehouses with GCP
ここからは腰を据えてじっくりとした展開になります。まずはデータエンジニアリングの基盤となるデータの保管に関してです。Data Lakeに生データを投入し、そこから必要に応じて整形してさまざまな下流の処理に使えるData Warehouseに流すという構成を叩き込まれます。Big Queryをいかに効果的、効率的に活用するかが大きな比重を占めるコースでもあります。Cloud SQLなどとの使い分けも重要なポイントとして図解されます。
3. Building Batch Data Pipelines on GCP
データパイプラインのうちバッチで処理するものに特化したコースです。Hadoopですでに動いているパイプラインをDataprocに移行する内容である前半はそもそもHadoopに馴染みのない私にはあまり響きませんでしたが、きっと便利なのでしょう。後半はフルマネージド(いわゆるサーバーレス)であるDataflowを使ったり、GUIだけでパイプラインが組めるData Fusionを使ったりします。複数の構成要素をつなぎ合わせ実行のトリガー等も簡単に指定できるCloud Composerで全体を管理し、具体的な処理はDataflowに書くという使い方も実践することができます。
4. Building Resilient Streaming Analytics Systems on GCP
続いてストリーミングを行うパイプラインを扱います。前のコースよりも見通しがよい印象です。Cloud Pub/Subを結節点とし、Dataflowで処理し、BigQueryに流し込むというシンプルな世界。リアルタイムに流れてくるデータゆえのチャレンジをどう捌いていくか。二週目はダッシュボードを作るのとBigQueryの最適化の話になって、特に後者は興味深く感じました。あまりストリーミングに固有ではない一般的な話ではありますが。
5. Smart Analytics, Machine Learning, and AI on GCP
機械学習をデータパイプラインに組み込むコースです。GCPにおける機械学習機能として、1)ML APIを呼ぶだけ(既存モデル・トレーニング済み)、2)BigQuery MLやAutoMLでコーディングなしに機械学習を使う(既存モデル・独自データでトレーニング)、3)AI Platform Notebookなどを使いながら自由にTensorFlowなどのソフトウェアを使う(モデルもデータも自由)、の三つのアプローチが紹介されます。そして順に実践。AutoMLの実践がなぜかなくて座学だけだったのはちょっと不思議です。見所として、TensorFlowのモデルをKubeFlowを使いながらk8sクラスタにデプロイすることを実践できて、こういうMLOpsをもっと習得したい! という気持ちです。
6. Preparing for the Google Cloud Professional Data Engineer Exam
最後のコース。これまでとは毛色が違い、全体的な体型をカバーするというよりも純粋にテスト対策をする内容です。とはいえ暗記事項をひとつひとつ押さえるような古くさいやりかたではありません。領域ごとにざっくり大きなポイントを復習し、ケーススタディーの解説が入り、いままでよりも難しい本格的な模擬問題を解く形式です。そして抜けているところがあったらその知識だけ覚えておしまいではなく、領域がまるごとあやふやな可能性が高いから学習し直すように、というスタンス。とても合理的だと思います。認証やネットワーク周りの内容の一部はいままでのコースではぜんぜん出てこなかったものもあって、そこだけは公式ドキュメントに一からあたる必要がありました。
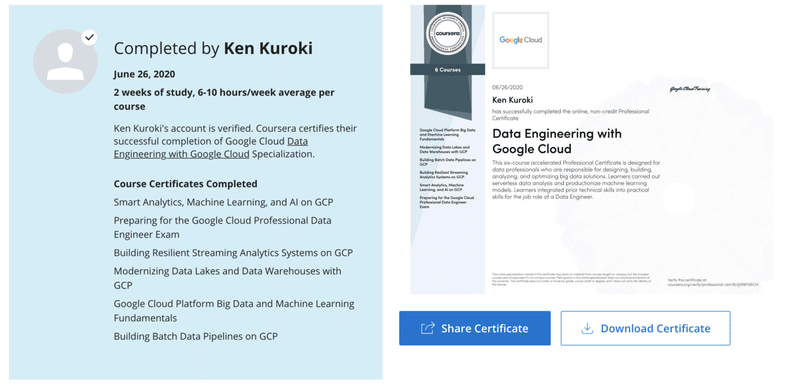
6つのコースを修了するとこんな感じでcertificateが獲得できます。
所感
動画は1.25倍速でも問題ないし、1.5倍でも平気なものもあり、またクイズとラボよりも短時間で終わるので実際には書いてあるよりも早く進みます。とはいえ、一週間で一気に終わらせよう、とか連休で始末しよう、なんてのはやはり無理があります。少しサボるとすぐに締め切りが迫ってきて焦って進めるはめになりました。まあ締め切りに遅れてもペナルティは特にないのですが、とはいえペースメーカーとして大事にしていった方がよさそうです。
全部修了したらもうばっちり業務でGCP使ってデータエンジニアリングできる! というものでは残念ながらなくて、さまざまな状況に応じて事細かにどこをどう設定するとかは実際カバーしません。はなからそういう趣旨でもありません。そうではなくて、次のようなもっと大局的なスキルが身につくと感じました。
1. ざっくりとタスクがあったときに、どういう設計でデータを処理していくか、それにあたってどのサービスを使うか、どこに注意してスケールさせるかといった青写真が描ける
2. なぜそうするかの理由が説明できる
3. 実際に組み立てるときには、膨大な量のドキュメントに気圧されず、大まかな土地勘を持って調べていける
当初の期待通り、これは仕様が変わったりしてすぐに古びる知識ではないのが嬉しいところです。あくまで一般的な原理原則に基づいて、このサービスはこういう特性を持っているからいつ使う、という論理がきっちりしているので、なんならGCP以外のクラウドを使うにあたっても十分に役に立つと思います。
とはいえ、これを取得しても実力証明にはあまりならない(こなしていけば取れてしまう面が強い)ので、次は対応する本物の資格(Professional Data Engineer certificate)に受かりたいところです。オンライン版もあるようですが、もう少し昨今の情勢が落ち着いたらオンサイトで受ける方が監視ツールなどのセットアップの手間がなくて手軽な気がしています。
この記事が気に入ったらサポートをしてみませんか?