
Googleスプレッドシート IMPORTXML関数で手軽にスクレイピング

GoogleスプレッドシートのIMPORTXML関数を使えば、XPathクエリを使用して、ウェブサイトから情報を抽出することができます。
例えば、天気情報のウェブサイトから天気予報データを取得して、スプレッドシートに自動で入力したり、ネットショッピングサイトから特定の商品の価格や評価を自動的に収集し、比較することができます。
参照した値が変わっても、1時間ごとに更新される仕様なので、再度IMPORTXML関数を入力する必要はないです。
IMPORTXML関数には処理時間の制限があり、大量のデータ取得には向いていません。大量のデータスクレイピングには、Pythonが向いていますが、サーバーに過度な負荷をかける短時間に大量のリクエストは、控えましょう。
IMPORTXML関数の使い方
今回は例として、朝日新聞デジタルの12星座占いの一位の星座を取得してみたいと思います。
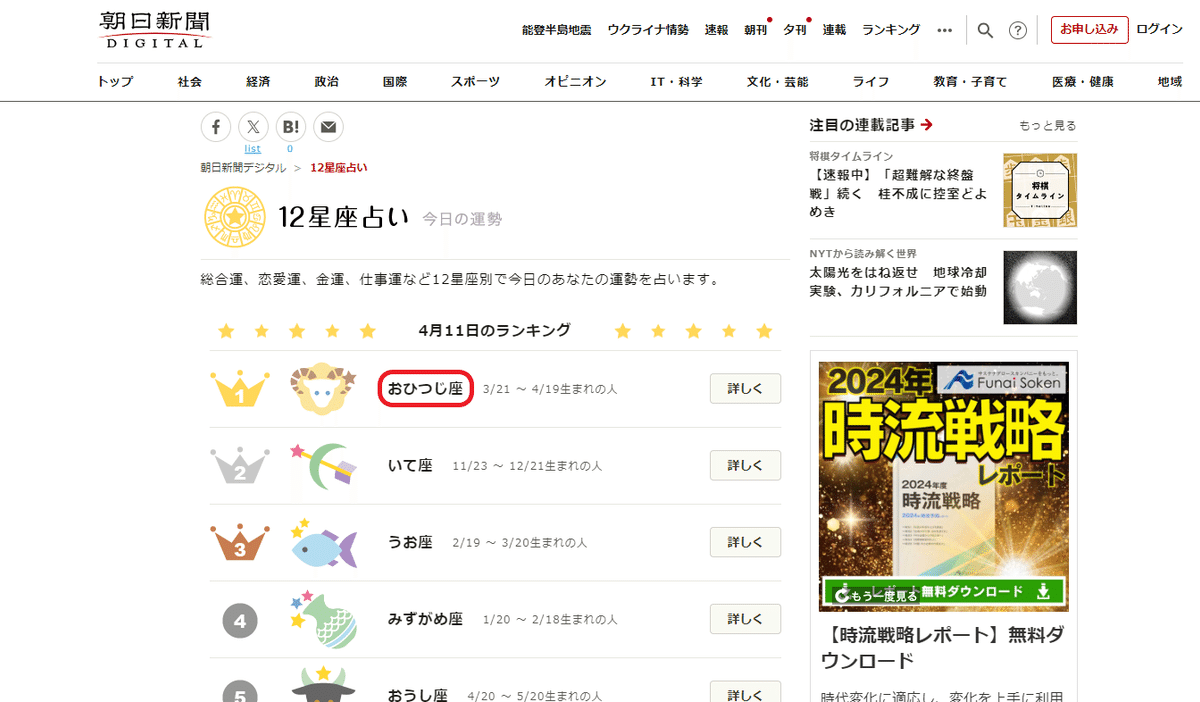
STEPIMPORTXML関数を入力する
ツールバー右にある、Σ をクリックします。
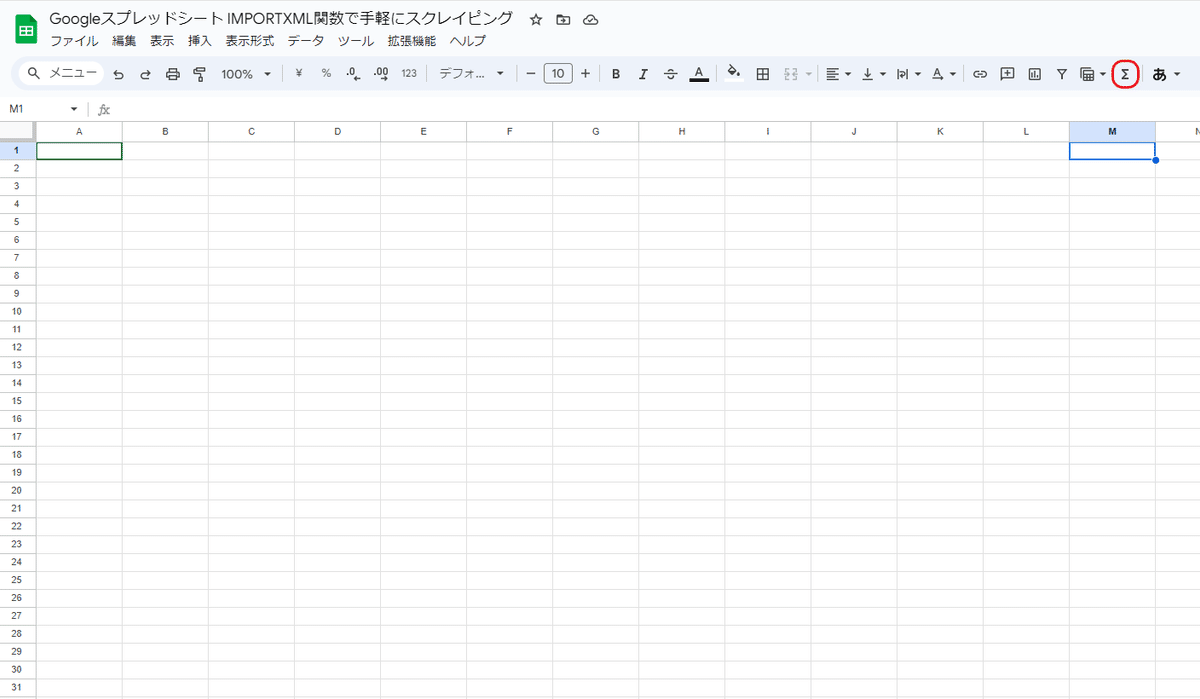
ウェブ ▶ IMPORTXMLをクリックします。
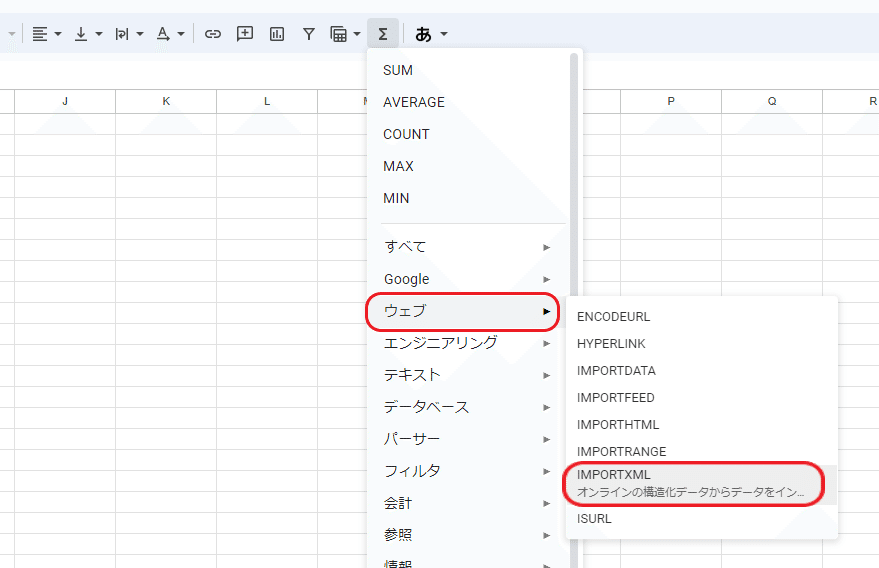
IMPORTXML関数がセルに入力されました。
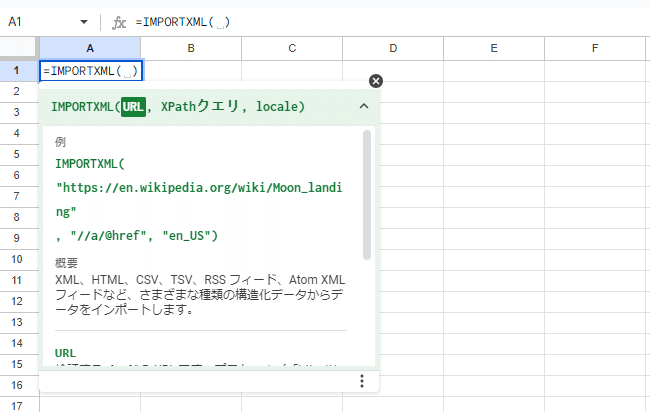
STEPIMPORTXML関数の第一引数にURLを入力する
IMPORTXML関数に必要な情報の一番目は、URLです。

今回取得したいのは、朝日新聞デジタルの12星座占いの一位の星座なので、朝日新聞デジタルの12星座占いのページのURLを入力します。
注意したいのは、""(半角ダブルクォーテーション)でURLを囲むことです。
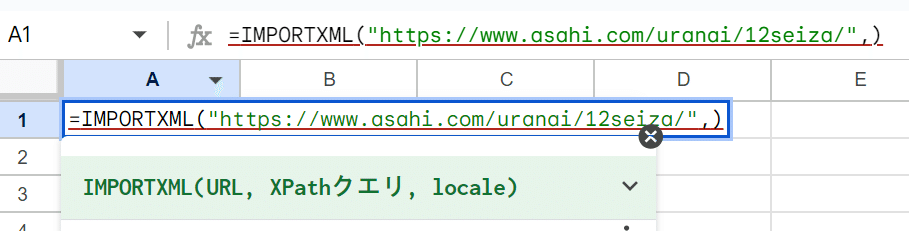
STEPIMPORTXML関数の第二引数にXPathクエリを入力する
次に、IMPORTXML関数の第二引数にXPathクエリを入力します。

第一引数で指定したURLのページ上で、取得したい値のXPathクエリを探しに行きます。
まずは、ページ上でキーボードの F12 キー を押して、デベロッパーツールを出します。
下記の画像のような状態になります。
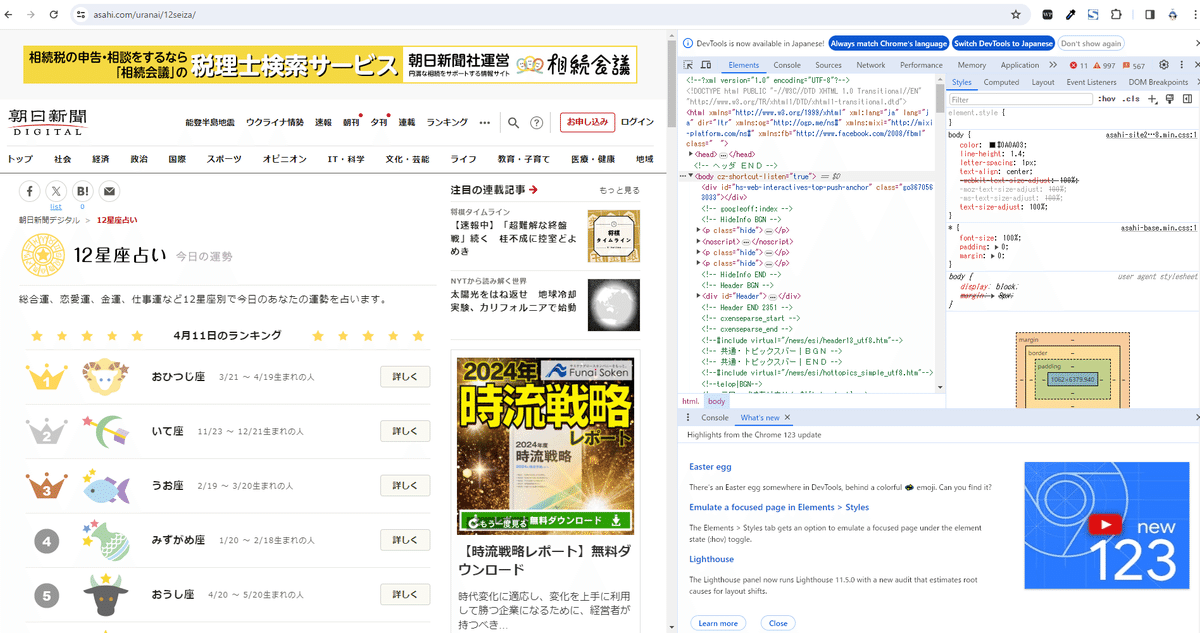
デベロッパーツールの Elements をクリックします。
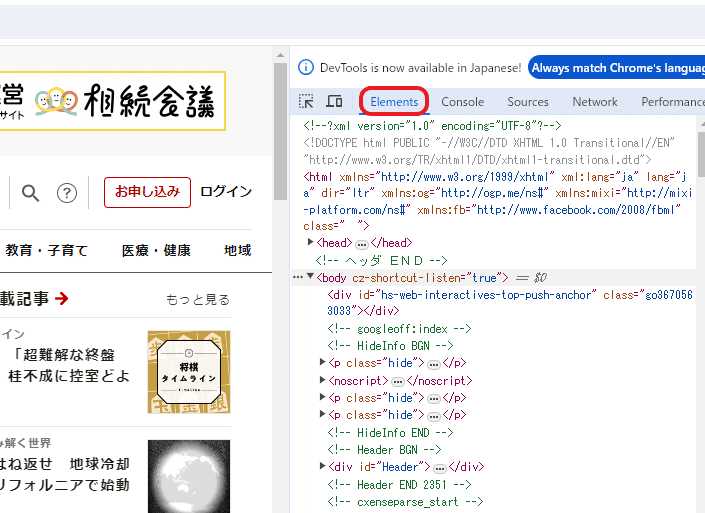
下記画像の Elements選択アイコンをクリックします。

Elements選択モードになるので、取得したい要素(今回は一位の星座)の所にカーソルを当ててクリックします。

ハイライトが点いて要素が選択されている状態になりました。

選択されている要素の ・・・ アイコンをクリックします。

Copy > Copy XPath をクリックします。これでXPathがコピーできました。
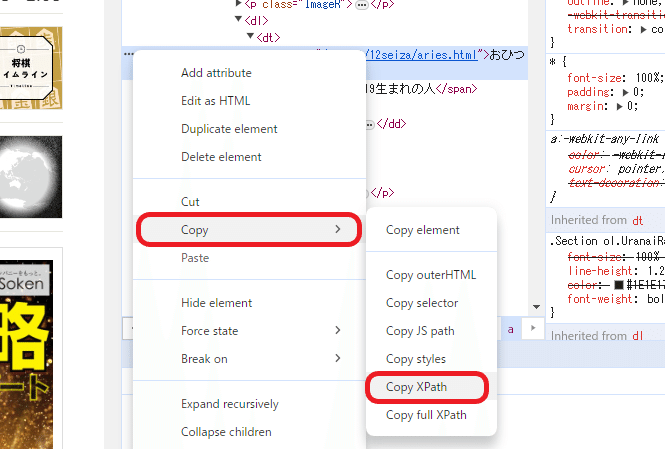
コピーしたXPathを""(半角ダブルクォーテーション)で囲んでIMPORTXML関数の第二引数に入力します。
//*[@id="MainInner"]/div[3]/ol/li[1]/dl/dt/a のように、XPathの中に""(ダブルクォーテーション)が存在する場合は、""(半角ダブルクォーテーション)を''(半角シングルクォーテーション)に変更してください。

値を取得できました。IMPORTXML関数は、第二引数までの指定でも値は取得できます。
STEPIMPORTXML関数の第三引数にlocaleを指定する(任意)

locale
localeは、データの地域設定を指定するもので、日付や通貨、数値などの書式がその地域の慣習に合わせて解釈されます。たとえば、"en_US"はアメリカの慣習に、"ja_JP"は日本の慣習に従った表示が行われます。
指定しない場合、ドキュメントの言語 / 地域が使用されます。基本的に指定する必要がないです。
最後に
便利なIMPORTXML関数ですが、すべてのウェブサイトで機能するわけではありません。
ログインしたユーザーにのみ利用可能なページや、CAPTCHAを使用しているサイト、スクレイピング対策をしているサイトなどでは、IMPORTXML関数で値を取得できない場合があります。
この記事が気に入ったらサポートをしてみませんか?