【論文紹介】Learning Explicit User Interest Boundary for Recommendation

文献情報
タイトル:Learning Explicit User Interest Boundary for Recommendation
著者:Jianhuan Zhuo, Qiannan Zhu, Yinliang Yue, Yuhong Zhao
会議:TheWebConf 2022
概要
推薦スコアが0~1の値を取るような推薦モデルにおいて、あるユーザへのあるアイテムの推薦スコアを計算して0.6だったときに、0.5以上だからと言って好みに合致しているとは限らず、このユーザにとってはスコアが0.7以上のアイテムが好みに合致していると判断するのが適しているという場合も考えられる。この論文では、推薦スコアがいくつ以上のアイテムであればユーザに適合していると判断できるかという閾値をユーザごとに導入する学習方法を提案している。
従来研究との差異
Implicit feedbackに基づくモデル学習時のロスの計算方法として、pointwiseとpairwiseの2種類のアプローチがとられてきた。
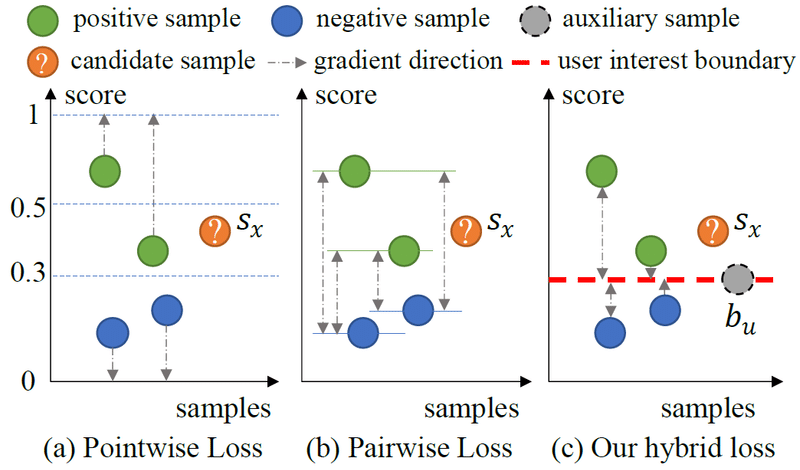
Pointwiseなアプローチは2クラス分類のような感じで、positiveなアイテム(ユーザが消費したアイテム)のスコアが1に、negativeなアイテム(ユーザが未消費のアイテム)のスコアが0に近づくように学習し、例えばユーザが未消費のアイテムのうち最終的なスコアが0.5以上のものを推薦する(下図(a))(図は論文より引用)。しかし、図のようにユーザの好みの真の閾値は0.3かもしれず、全ユーザに0.5という共通の閾値を用いるのは適切ではない。
Pairwiseなアプローチでは、全ユーザに共通の閾値すら存在しないので、あるアイテムの推薦スコアがいくつ以上であればそのユーザに適合しているか判断できない(下図(b))。
本論文では、ユーザごとに固有の閾値を導入することで、アイテムの適合・不適合をより柔軟に判定できるようにし、かつ学習効率も改善する(下図(c))。
手法
提案する手法は、様々な既存の推薦手法で用いられるpointwiseやpairwiseでの損失関数を拡張することで実現される。一般的な推薦手法では各ユーザはd次元のユーザベクトルを持つ。ユーザuのベクトルと、全ユーザ共通のd次元の重みベクトルWとの内積で求められる値を、uの好みの閾値buとして用いる。
そのうえで、「uのすべてのpositiveなアイテムの推薦スコアはbuよりも大きく、すべてのnegativeなアイテムの推薦スコアはbuよりも小さいのが望ましい」という状態を反映した損失関数に拡張する(論文式(4))。この損失関数を使って学習することで、ベクトルWもユーザやアイテムのベクトルと同様に最適化され、ユーザごとの最適な閾値が求められる。
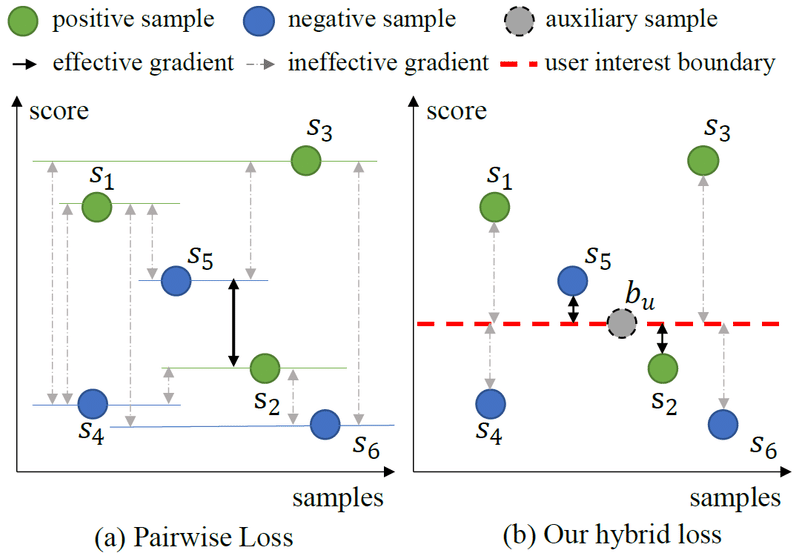
あるユーザのpositiveなアイテムが3件、negativeなアイテムが3件あったときに、positiveとnegativeの組み合わせは9件ある。従来のpairwiseなアプローチでは、下図(a)のようなケースで適切に学習が進む組み合わせはs5とs2だけであり、割合は1/9である(図は論文より引用)。それに対して提案手法では、下図(b)のようなケースにおいて、buと各アイテムとの比較をするので、比較の組み合わせは6件ある。そのうち適切に学習が進むアイテムはs5とs2であり、割合は2/6となる。つまり、提案手法の方が無駄な比較をするケースが減り、効率的に学習が進むことも期待できる。
実験
Amazon Instant Video、LastFM、Movielens-1M、Movielens-10Mのデータセットを使用。推薦手法としてはBPR、NCF、SML、LightGCNを使用し、各手法の損失関数を提案手法により拡張し、元の手法との精度を比較。提案手法を使うことでいずれの手法でも精度が改善し、かつ学習が収束するまでのエポック数も少なくなることを示した。NCFベースの手法での、各データセットの各ユーザのbuの分布は下図のようになっていて、ユーザごとに異なる閾値を持つことも示した(図は論文より引用)。

この記事が気に入ったらサポートをしてみませんか?