【論文紹介】A Gain-Tuning Dynamic Negative Sampler for Recommendation

文献情報
タイトル:A Gain-Tuning Dynamic Negative Sampler for Recommendation
著者:Qiannan Zhu, Haobo Zhang, Qing He, Zhicheng Dou
会議:TheWebConf 2022
概要
Implicit feedbackに基づく推薦手法では、学習時に1件の正例(ユーザが消費したアイテム)と1件の負例(ユーザが未消費のアイテム)をサンプリングし、正例の推薦スコアが負例の推薦スコアよりも高くなるようにユーザやアイテムのベクトルを最適化する。負例はユーザが未消費の全アイテムからランダムにサンプリングするのが一般的であるが、未消費のアイテムの中にはそのユーザの好みに本当は適合しているけれど消費できていないアイテム(false negative)も含まれている。この論文では、そうしたアイテムを極力排除し、ユーザが本当に興味がなくて消費していないアイテム(true negative)をサンプリングする手法を提案し、それにより推薦精度が改善されることを示した。
従来研究との差異
あるユーザに対する負例をサンプリングする際に、学習時の推薦スコアの高い負例を優先的に選択する手法が提案されてきた。これは、推薦スコアが高いアイテムは実際にそのユーザが目にしている可能性が高く、そのうえで消費していないのであればtrue negativeなアイテムであるという仮説に基づいている。しかし、学習時の推薦スコアが高い負例はむしろfalse negativeである可能性が高いことを本論文では実験的に示し、この問題点を解決する負例のサンプリング手法を提案している。
手法
モデル学習時に、t回目のエポックで、ユーザuの正例のアイテムiに対して、負例のアイテムjをサンプリングする状況を考える。負例であるjがuの目に触れている可能性の高さを、uへのjの推薦スコアからiの推薦スコアを引いた値を基に計算する(H(t, u, j)とする)。負例であるはずのjの推薦スコアが高いほど、H(t, u, j)の値も大きくなるので、上で紹介した従来手法ではH(t, u, j)の値が大きいアイテムjを負例としてサンプリングしていた。
本論文の手法は、単にH(t, u, j)を見るだけでなく、1つ前のt-1回目のエポックでのH(t-1, u, j)も見る点に特徴がある。いくらH(t, u, j)の値が大きくても、H(t-1, u, j)との差がほとんどなければ、アイテムjのベクトルの適切な学習が進んでいないことを意味する。つまりこれはjがfalse negativeである可能性が高いことが原因だと考えられるので、負例として使用すべきではない。逆に、H(t-1, u, j)に比べてH(t, u, j)が小さくなっていれば、jについて適切に学習が進んでいて、jがtrue negativeである可能性が高い。このように、1つ前のエポックからの学習の進み度合い(gain)が大きい負例を優先的にサンプリングするというのが提案手法の特徴である。
実験
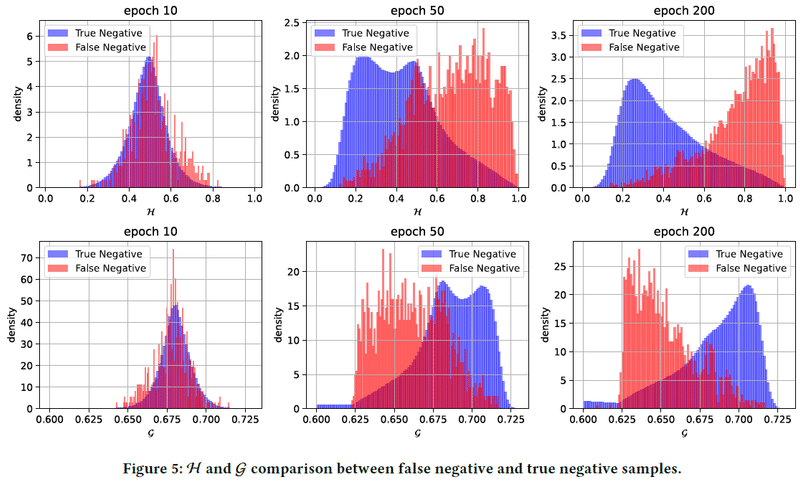
Movielens-1mとPinterestのデータセットを使用。推薦精度の評価に加えて、ユーザの正例の何割かを意図的に負例とすることでfalse negativeであるような負例を人工的に作り出し、そうしたfalse negativeなアイテムは学習が進むに連れてH(t, u, j)の値が大きくなることを示した(下図上段)。逆に、false negativeなアイテムは学習が進むに連れて、提案手法により計算されるgainの値が小さくなることも示した(下図下段)(図は論文中より引用)。
この記事が気に入ったらサポートをしてみませんか?