【論文紹介】The Datasets Dilemma: How Much Do We Really Know About Recommendation Datasets?

文献情報
タイトル:The Datasets Dilemma: How Much Do We Really Know About Recommendation Datasets?
著者:Jin Yao Chin, Yile Chen, Gao Cong
会議:WSDM 2022
概要
15種類のデータセットを対象にして5種類の推薦手法の精度を比較し、データセットによって有用な手法がどの程度異なるかを示した。また、その結果をもとに、推薦手法を提案する今後の研究でどのようなデータセットを使えば良いかを提案した。実験に使用したコードとデータセットはGitHubから利用可能。
従来研究との差異
最近の情報推薦分野の研究における不備を指摘した代表的な研究として以下のものがあげられる。
Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, RecSys 2019
深層学習ベースの手法の大半が、ハイパーパラメータを適切にチューニングしたkNNベースの手法に劣ることを示した。On Sampled Metrics for Item Recommendation, KDD 2020
推薦手法の評価では、負例を100件サンプリングして、正例の1件を101件の中でどれだけ上位にランキングできるかを評価することが多いが、これで求められる精度は、全負例を使った場合の精度と大きく異なることを示した。Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison, RecSys 2020
データの前処理方法や、学習データとテストデータの分割方法によって、推薦手法の精度が大きく変わることを示した。
これに対して本論文では、データセットの違いが推薦精度に与える影響を調査した。
比較方法
「過去5年の主要国際会議で、top-K推薦を扱った1件以上の論文で使用された」などの条件をもとに、51種類のデータセットをリストアップ。各データセットの性質を、5種類の指標(ユーザ・アイテム行列のスパース率、ユーザごとの消費アイテム数の偏り、など)で表現。この指標を使って各データセットを5次元のベクトルで表現し、51種類のデータセットをk-meansで5つのクラスタに分類。各クラスタの性質を端的に表すデータセットとして、クラスタの中心に近い順に3種類のデータセット(5クラスタ分で計15種類のデータセット)を選び、実験に使用。
実験
15種類のデータセットを対象に、以下の5種類の推薦手法の精度を比較。
UserKNN
ItemKNN
RP3beta:ユーザとアイテムがノード、ユーザと消費アイテム間にエッジがあるグラフ上のランダムウォークに基づく手法。
WMF:Implicit feedback用の行列分解手法。
Mult-VAE:深層学習ベースの手法。
評価指標にはRcall@10とnDCG@10を使用。nDCG@10の結果は下図のとおり(図は論文より引用)。
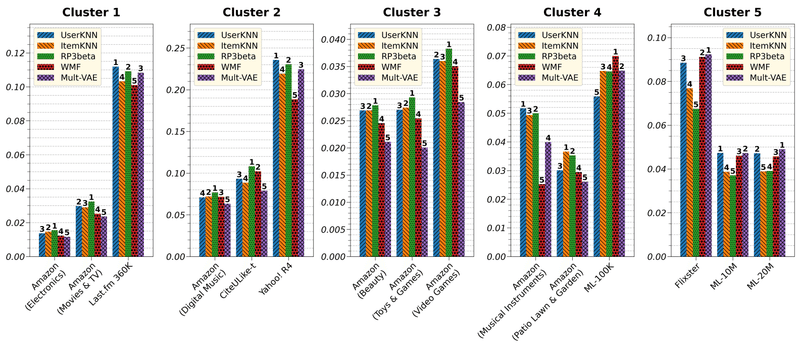
同一クラスタ内での手法の優劣はある程度一貫しているが、クラスタ間での手法の優劣は大きくことなることがわかる。例えばクラスタ3のデータセットは、ユーザの評価アイテム数と、アイテムの被評価ユーザ数のいずれも偏りが小さく、グラフを作成したときにエッジが万遍なく存在するため、グラフベースのRP3betaの手法の精度が高くなる傾向にある。クラスタ4のデータセットはサイズが小さいため、クラスタ内でも手法の精度が安定していない。
以上のような結果を踏まえると、提案手法の頑健性を示すためには、単に複数データセットで評価をするのではなく、本論文での異なるクラスターに属するような、性質の異なる複数データセットで評価することが重要になる。これまでの論文では、「ML-10MとNetflix」や「ML-20MとNetflix」といった組み合わせのデータセットが評価に使われることが多かったが、これらはいずれもクラスター5に属するデータセットなので、性質の多様性という観点からは不十分といえる。
この記事が気に入ったらサポートをしてみませんか?