東京都の降水量データを試行錯誤する②(モデル作成編)

前回の記事では、気象庁のホームぺージから東京都の降水量データをダウンロードし、指標をグラフ化しました。
今回はSARIMAモデルの作成をしていきます。
SARIMAモデルのパラメータの決定
GridサーチでどのパラメータのAIC値が一番良いか見ていきます。
実行結果 : (p,d,q)(sp,sd,sq,s) ⇒ (9, 1, 2), (0, 0, 0, 12)
##################################################################################################################
# SARIMAモデルのパラメータ(p,d,q)(sp,sd,sq) AIC
# 各パラメータの範囲を決める
p = d = q = range(0, 10) # 範囲をどう決めるか不明
sp = sd = sq = range(0, 1) # 範囲をどう決めるか不明
s = 12
# p, d, q の組み合わせを列挙するリストを作成する
pdq = list(itertools.product(p, d, q))
#print(pdq)
# P, D, Q の組み合わせを列挙するリストを作成する
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(sp, sd, sq))]
#print(seasonal_pdq)
# 一番AIC値が低いパラメータの組み合わせをbest_resultに保存する
best_result = [0, 0, 10000000] # pdq, seasonal_pdq, AIC値
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = SARIMAX(train,
order = param,
seasonal_order=param_seasonal,
enforce_stationarity=True,
enforce_invertibility=True)
results = mod.fit()
#print('order{}, s_order{} - AIC: {}'.format(param, param_seasonal, results.aic))
if results.aic < best_result[2]:
best_result = [param, param_seasonal, results.aic]
except Exception as e:
print(str(e))
print(param)
print(param_seasonal)
continue
print('AICが最も良いモデル:', best_result) #(9, 1, 2), (0, 0, 0, 12), 999.6185495135071SARIMAモデルの構築
上で求めたパラメータ使ってSARIMAモデルを構築します。
学習用データとして準備した7年分のデータを使い学習したのち、
残りの3年間の降水量データを予想しました。
##################################################################################################################
# SARIMAモデル (9, 1, 2), (0, 0, 0, 12), 999.6185495135071
mod=sm.tsa.statespace.SARIMAX(train,order=(9,1,2),seasonal_order = (0,0,0,12), enforce_stationarity = True,
enforce_invertibility = True)
results = mod.fit()
print(results.summary())
pred = results.predict()
pred2 = results.forecast(36)
plt.title("Tokyo Precipitation ")
plt.xlabel("date")
plt.ylabel("Precipitation")
#plt.ylim([50000,135000])
#plt.xlim([0,100])
plt.plot(df,color="b", label = "Actual value")
plt.plot(pred,color="r", label = "learn value")
plt.plot(pred2,color="y", label = "Predicted value")
plt.legend(loc = 2)
plt.show()結論
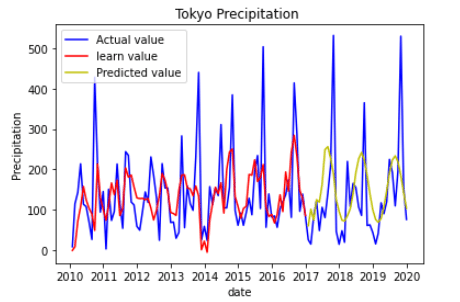
グラフの見方は、
青線(Actual value)は気象庁からダウンロードした降水量の実績10年分
赤線(Lean value)は学習用に使った7年分の学習結果
黄線(Predicted value)は学習に使っていない3年分を予想
これを見ると各季節の特徴をとらえて降水量の多い季節と少ない季節を予想できております。
しかし、降水量の絶対値を見ると降水量の多い台風の季節は実際の半分の降水量を予測値とする結果となりました。
台風といっても毎年400ml、500mlの降水量が発生するわけでなく、2011年、2012年頃は200ml程度と倍以上の差があるため、外れ値としてとらえられた可能性が高いのかと思います。
補足として、400mlや500mlを正確に予想するためにもう少し対象期間を増やせば、400mlや500mlのプロットも増え学習してくれるのでは?と思い30年で試してみましたが結果はより精度が落ちてしまうため他のチューニングやモデルを変える必要なんだと思いました。
今回はSARIMAモデルを試したかったので以上とします。
この記事が気に入ったらサポートをしてみませんか?