物体検知・セグメンテーション

・広義の物体認識タスク:
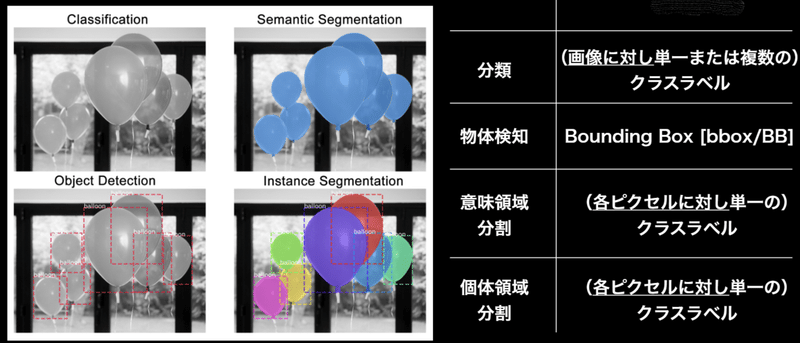
一例:

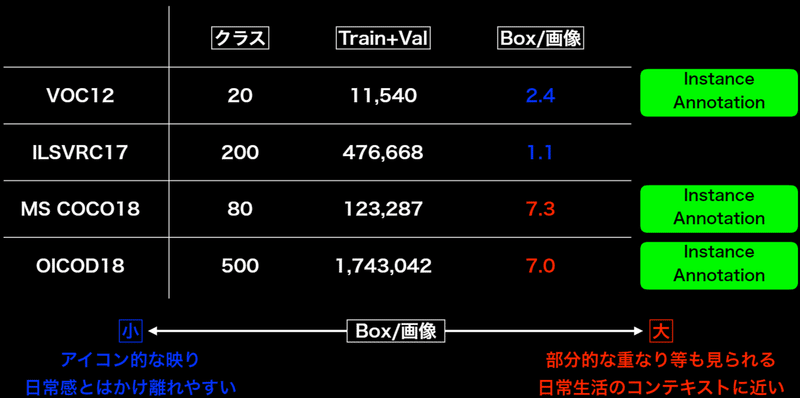
・代表的なデータセット:
・PrecisionとRecall:
適合度(Precision)

“りんご”と予測したもののうち、実際にあたっていた割合
再現度(Recall)

“りんご”の真値のうち、ただしく予測された割合
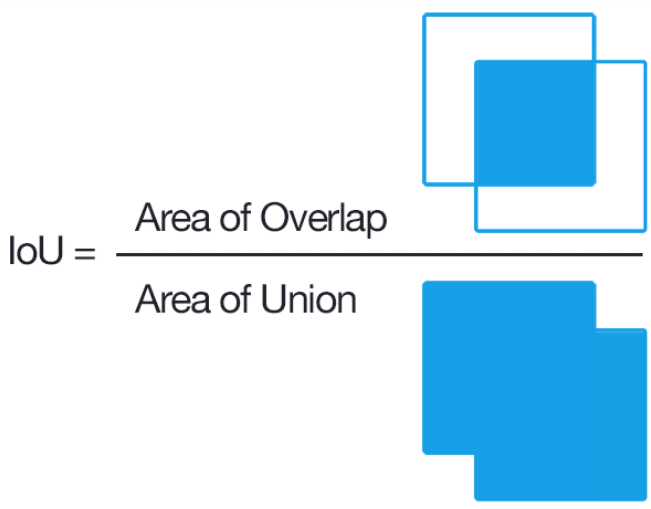
・IoU(Intersection over Union):
・Precision/Recallの計算例(人のクラス):

・AP:Average Precision
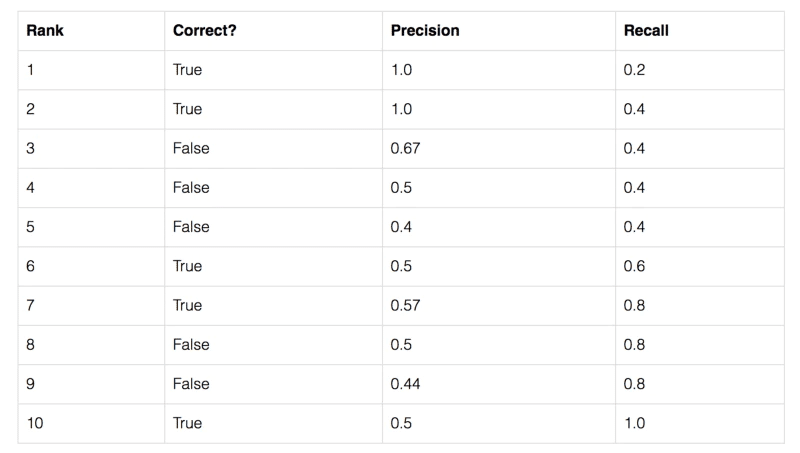
上の表は、5つの物体を各画像に含むデータセットにおいて、モデルの予測結果を予測の信頼度順で並べたものである。以下の表を描ける。
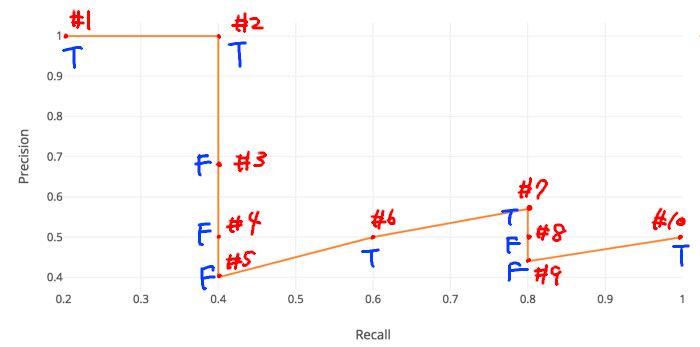
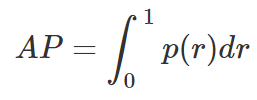
つまり、オレンジの曲線の下の面積がAP
・mAP:mean Average Precision

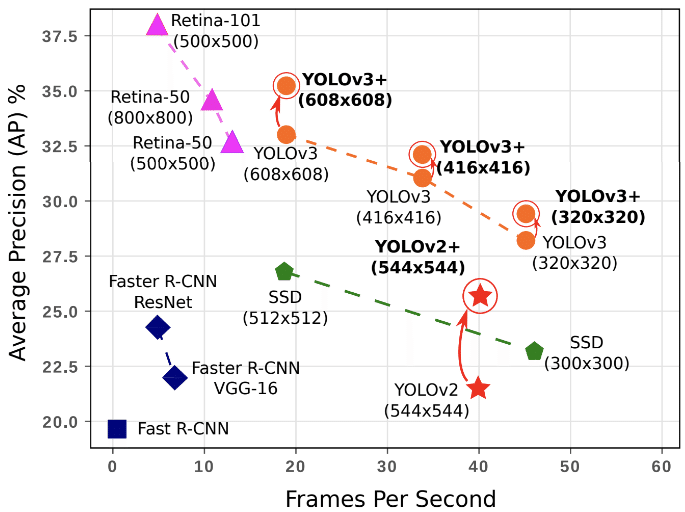
・FPS:Flames per Second 検出のフレームレート
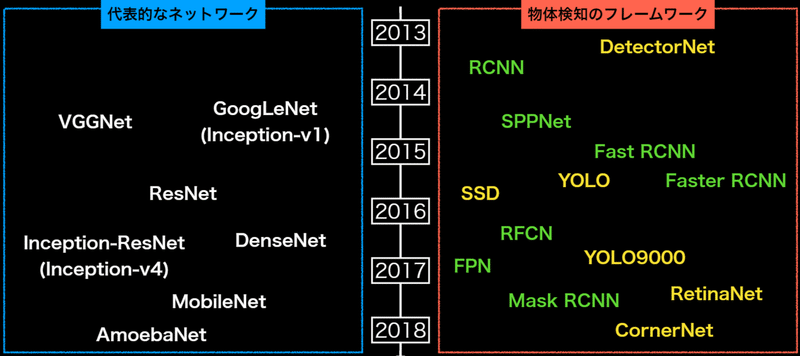
・マイルストーン
・One-stage detector:物体検出とクラス推定を同時に行う。
・Two-stage detector:物体検出とクラス推定を別々に行う。
・SSD: Single Shot Detector
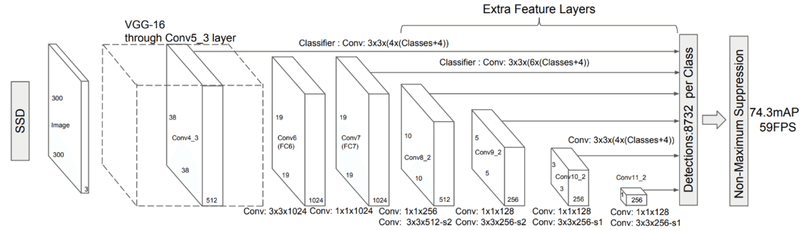
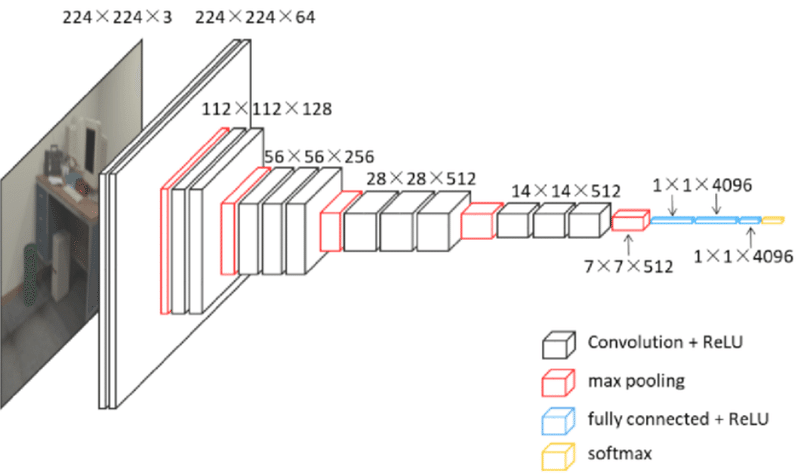
VGG
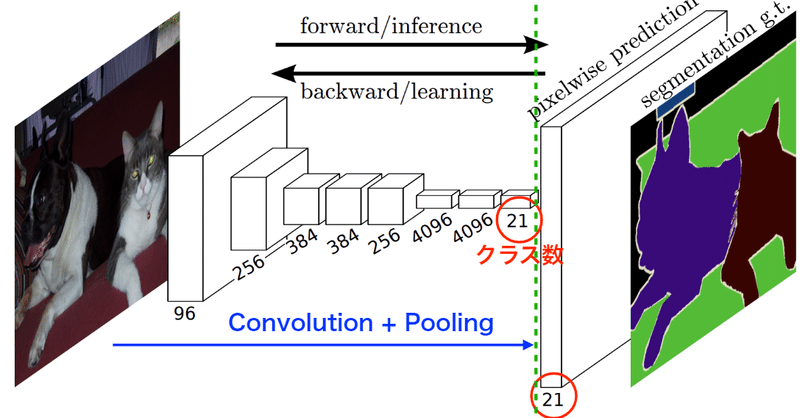
・Semantic Segmentation:物体のクラスだけのセグメンテーション、基本構造はボトルネックのようにまず特徴マップへ集約して、拡大(UpSampling/
)する。
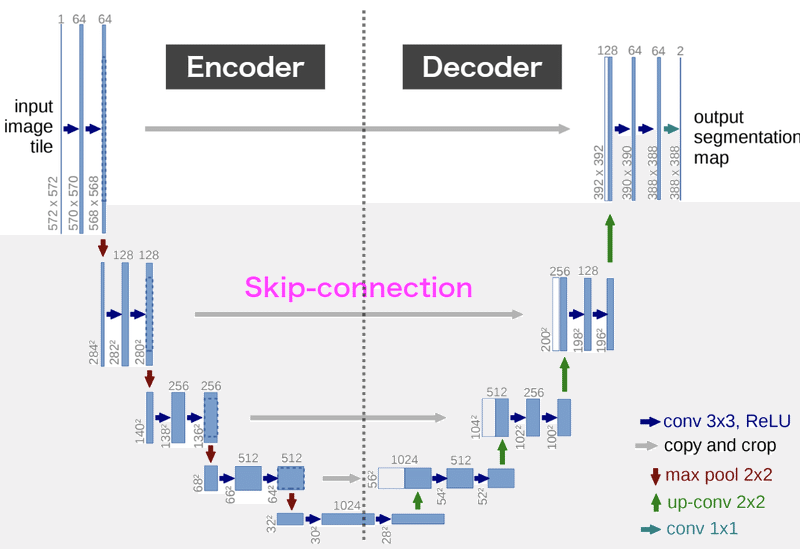
・U-Net:
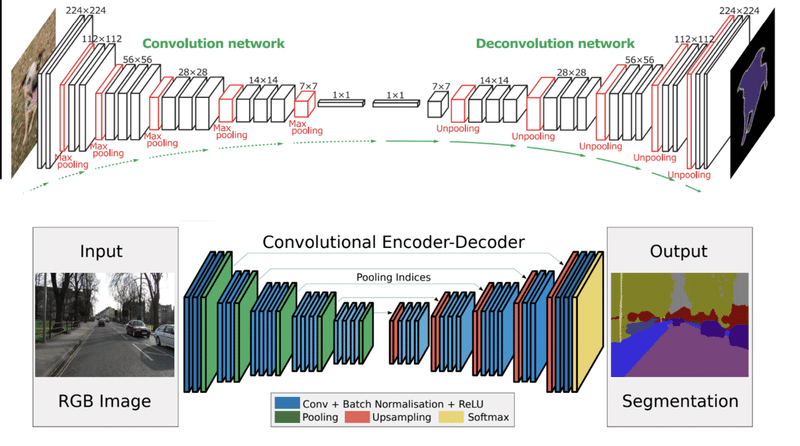
・DeconvNet & SegNet
考察
・物体検出とセグメンテーションは本来、別々のタスクであったが、mask-rcnnの出現で統一した検出が可能になった。ただし、物体検出もともとたくさんのトリッキーなやり方(例えば:アンカーボックスなど)をしているので、さらに複雑になっている。将来的に特に自動運転はこの分野の技術が不可欠になるのは明白で、各大企業は精度とリアルタイム性能を競い合ってる。あとは3Dビジョンと結合で完全自動運転などの応用がますます近いうちに市場にでると考える。
この記事が気に入ったらサポートをしてみませんか?