軽量化・高速化技術

・プルーニング・・分散深層学習:データ並列化、モデル並列化を用いてディープランニングを加速する手法である。
・データ並列化:1)同期型:教師データを複数に分け、違うデバイスで同じ重みのネットワークで勾配を得る。その勾配で全デバイスのモデルを更新する。2)非同期型:全デバイスのモデルが各自で勾配を得て更新する。
処理のスピードは、非同期型の方が早いが、非同期型は学習が不安定になりやすい。現在は同期型の方が精度が良いことが多いので、主流となっている。
・モデル並列化:モデルを分割し、複数のデバイスへ配置する。モデルが大きい時に使われる。
・GPUによる高速化:CPUは高性能なコアで少数•複雑で連続的な処理が得意である。GPUは比較的低性能なコアで多数•簡単な並列処理が得意である。ニューラルネットの学習は単純な行列演算が多いので、GPU高速化に適している。
・GPGPU開発環境:CUDA、OpenCLなど
・モデルの軽量化:モデルの精度を維持しつつパラメータや演算回数を低減する。モデルの軽量化はリアルタイム計算、モバイル、IoT機器に有効である。代表的な手法は量子化、蒸留、プルーニングがある。
・量子化:通常のネットワークの重みが64 bit 浮動小数点を16bitや8bitなど下位の精度に落とすことでメモリと演算処理の削減を行う。高速化と小メモリ化ができるが、精度が落ちる。
速度の実験例:

精度があまり落ちない場合もある

・蒸留:精度が高くて複雑なモデルが簡単なモデルに教師として教える。
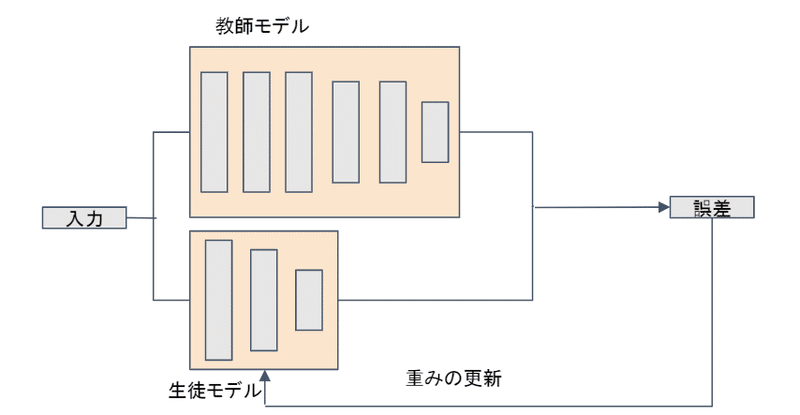
・プルーニング:精度が高くて複雑なモデルの構造そのももを精度があまり落ちないように枝刈りあるいはニューロン削減する。
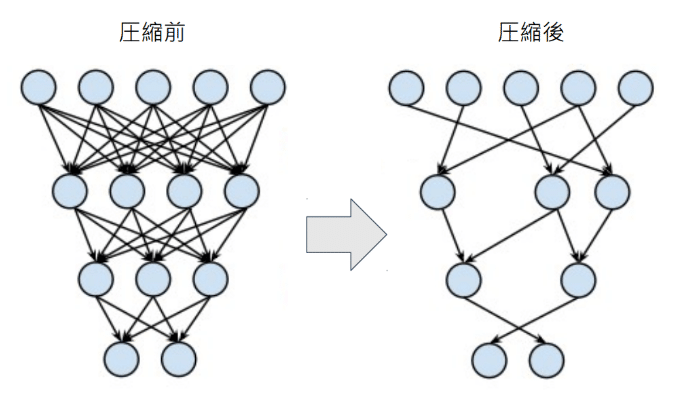
考察
・ディープランニングの高効率化も流行りのテーマの一つで、特にエッジコンピューティングでは不可欠な存在である。スマホなどの普及により、AIが簡単に端末で完結できると大きな利益をもたらす。自動運転技術はまさにエッジコンピューティングの最先端といえる。
・高速化のもう一つ手法として、専用デバイスによる高速化がある。CUDAコアよりもTensorCoreの方が行列演算が早いとか、GoogleのTPUなどが市場に出回っている。
この記事が気に入ったらサポートをしてみませんか?