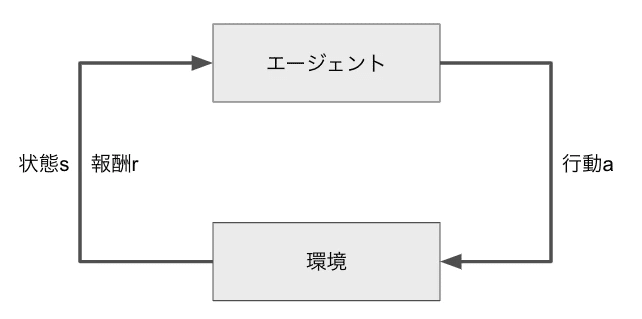
強化学習

・強化学習:機械学習において教師データの代わりに環境のフィットバックを教師データとした学習モデルである。長期的に環境からの報酬を最大化できるように環境のなかで行動を選択し、最大報酬を得るエージェントを作ることを目標とする機械学習分野である。行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組みである。
応用例:迷宮脱出AIなど
環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能だが、強化学習の場合、完璧な知識は成り立たないとする。不完全な知識を元に行動しながら、データを収集して最適な行動を見つけていく。
・教師なし、あり学習:データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標
・強化学習:優れた行動を見つけることが目標
・Q学習:強化学習の最も有名なアルゴリズムである。行動価値関数を、行動する毎に更新することにより学習を進める方法。
・関数近似法:価値関数や方策関数を関数近似する手法のこと
・価値関数:価値を表す関数としては、状態価値関数と行動価値関数の2種類がある。
・方策関数:方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数のこと
・方策勾配法:方策をモデル化して最適化する。
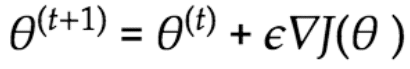
J関数は方策の良さを表し、定義しなければならない
・J関数の定義:平均報酬あるいは割引報酬和。行動価値関数Q(s,a)の定義を行うことで方策勾配法が適用できる。
考察
・強化学習は環境のシミュレーションが簡単で無限にトライできる状態でよく使われる。例えば将棋などのゲームなど、人間による教師データは有限だし、最適とも言えない。この場合では二つのニューラルネットワークが互いに無限に対戦することで最適な行動を生み出せるニューラルネットワークが生成できる。
この記事が気に入ったらサポートをしてみませんか?