Seq2seq

・Seq2seq:Encoder-Decoderモデルの一種で、機械対話や、機械翻訳などのテキストタスクによく使用されている。
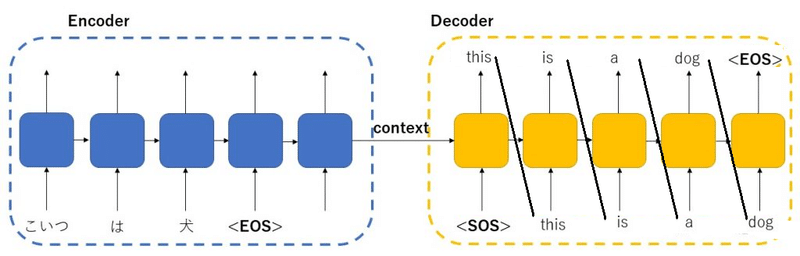
・Encoder RNN:ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す。<SOS>,< EOS>はStart of string, End of stringの略でEncoderの出力値は捨てらる。
例:昨日 食べた 刺し身 大丈夫 でした か
Taking:文章を単語等のトークン毎に分割し、トークンごとにIDがある。
Embedding:IDから「辞書」を調べて分散表現ベクトルへ数値化する。
Encoding(Encoder RNN):ベクトルを順番にRNNに入力していく。
・Encoder RNN処理手順:単語1をRNNに入力し、中間層結果1を出力。この中間層結果1と次の入力単語2をまたRNNに入力してまた中間層結果2を出力という流れを繰り返す。最後の単語を入れたときの中間層結果をfinalstateとしてとっておく。このfinalstateがcontext vectorと呼ばれ、入力した文の意味を凝縮したベクトルとなる。
・Decoder RNN:context vectorと単語トークンごとに生成するRNNである。

・Decoder RNN処理手順:context vectorと<SOS>トークンを入力して最初の出力単語1(this)と中間層結果1を得られる。次に出力単語1と中間層結果1を入力して出力単語2(is)と中間層結果2を得られる。< EOS>が出力されるまで繰り返す。
Detokenize:Decoderの実質の出力は数値ベクトルで「辞書」を調べて単語にする。
・確認テスト:下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
・回答:(2)
・HRED:Seq2seqの課題である→問に対して文脈も何もなく、ただ応答が行われる続けることを解決するため、過去n-1 個の発話から次の発話を生成する。
システム:インコかわいいよね。
ユーザー:うん
システム:インコかわいいのわかる。
Seq2seqでは会話の予測に使用すると前文脈無視して応答したが、HREDでは前の単語の流れに即して応答されるため、より人間らしいチャットが生成される。
HRED=Seq2Seq + Context RNN(context vectorを次に流せるようにRNNを追加)
・Context RNN:Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造で、つまり過去の発話の履歴を加味した返答をできる。
・HREDの課題:会話の「流れ」のような多様性が無い。短く情報量に乏しい答えをしがちである。例:相槌しか返答しない
・VHRED:HREDに、VAE(Variational Autoencoder)の潜在変数の概念を追加したもので、Context RNNにさらにVAEの結果を入れることでより多様性をふやした。VAEの入力には確率的なノイズを与えるだけで「話題の流れ」的なベクトルを生成する。
・確認テスト:seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ
・回答:seq2seqはRNNをEncoder-Decoderに応用したモデルである。HREDはseq2seqをもとにEncoderで出力されるcontext vectorをさらにRNN( Context RNN)を適用するモデルである。VHREDはHREDをもとにContext RNNにVAEを適用したモデルである。
・オートエンコーダ:教師なし学習の一種である。

MNISTの場合、28x28の数字の画像を入れて、同じ画像を出力するように学習させる。潜在変数zに変換するニューラルネットワークをEncoderとする。潜在変数zをインプットとして元画像を復元するニューラルネットワークをDecoderとする。通常では潜在変数zの要素数は入力より小さいため、データの次元削減が行える。
・VAE(Variational Autoencoder):通常のオートエンコーダーの場合、何かしら潜在変数zを出力し、その数値がどのようなものかを解釈できない。VAEはこの潜在変数zに確率分布z∼N(0,1)を仮定したものである。何かしらの確率分布という解釈にできる。
・確認テスト:VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
自己符号化器の潜在変数に____を導入したもの。
・回答:確率分布z∼N(0,1)を仮定した構造
考察
・初期のgoogle翻訳はまさにSeq2seqモデルを使用した。当時ではでたらめな結果、あるいは簡単で短い文しか翻訳出来なかった。そのわけはまさにSeq2seqモデルの諸課題にあった。あとは頻繁に「辞書」という言葉を使用したが、初期のモデルでは結局、人が用意した「単語ー数値ベクトル」を用いた。そもそも辞書自体の表現力が乏しいであったため、翻訳モデルの性能が出なかった。
この記事が気に入ったらサポートをしてみませんか?