
AIにWoTの新車両を作らせてみた

ポップでキャッチーなタイトルで気を引いてみる。
やった事をちょっと真面目に書くと「VAEを用いた既存車両の低次元潜在ベクトルの獲得とdecoderによる新車両の生成」。
結果だけ見たい人は「既存車両の2次元平面上での表現」から読んで。
やったこと
・WoTの車両性能データを使ってVAEを学習した
・既存の車両の特徴を2次元平面上で表現した
・decoderを使って新車両を生成した

VAEとは
Variational Autoencoderの略。
そもそものAutoencoderというのはニューラルネットワークの一種で、入力側に入れたデータを出力側で再現するように学習したモデル。中間レイヤーの次元を絞ることで、与えられたデータの特徴を効率良く学習してくれる。

例えばWoTのTier10車両で下記のような性能の車両がいたとする。

WoTプレイヤーのあなたはこの車両の特徴をどのように表現するだろう。
「単発390で、DPMが2500で、俯角が10度で、速度が45km/hで…」と答えるのはナンセンスである。
例えばこういう表現が思いつく。
「単発が低いからTDではなさそうで、速度的には重戦車か中戦車っぽいけど装甲そこそこ厚いから重戦車っぽいかな。DPMやや低めなのも重戦車っぽい。総合するとアメリカとかイギリスの重戦車っぽくてやや中戦車よりの性能してる」
もし下図のような既存車両のマップがあったならば、多くの人が領域Aの辺りにこの車両を置くのではないだろうか。

つまり車両の特徴を表す上で、単発、DPM、俯角、速度、装甲といった性能値は多数あるものの、それらをなんとなく統合して2次元平面上に表現できる感覚を我々は持っている。車両性能を2次元平面上に表現する事もできるし、逆に2次元平面上の点から車両の性能をおおよそ想像することも難しくないと思う。
Autoencoderが表現しているのは正にこの部分である。
Autoencoderの前半部分であるencoderが「多次元の入力データの特徴を上手いこと統合して低次元の情報に圧縮」、後半部分のdecoderが「圧縮された情報から多次元のデータを復元」に対応している。
Autoencoderでは中間レイヤーの次元を絞っているため、情報を一度圧縮しなければならない。つまり特徴を表現するのに使える領域が少ないため、Autoencoderは似通った情報はなるべく近しい領域にマップされるように学習する。これがAutoencoderが与えられたデータの特徴を表現できるメカニズムである。
VAE(Variational Autoencoder)とはAutoencoderのうち、圧縮された情報のマッピングが特定の確率分布(例えばガウス分布)になるように学習したものである。圧縮先が制限されることで各特徴の連続性が学習されやすい、という理解。
とりあえず覚えておいてほしいのは、マッピングの中で中心付近に現れるものは平均的な車両、逆に中心から離れるほど他の車両とは異なる特徴を持っているということ。
VAEについて詳しくは他の解説ページ見て(急に投げやり)。
学習させるデータ
tanksggで確認できる性能値のうち、独断と偏見により選んだ下記26項目を特徴ベクトルとして選んだ。てか書いてて気づいたけど隠蔽に関するデータって入ってないのね。まあ何とかなる。

また、学習データは通常ツリー、報酬車両とかからこれまた独断と偏見で選んだ計70種の車両。自分がWoTガッツリやってたのはCWE「戦場の虎」までなので"UDES 15/16"とかよく知らんけどとりあえず入れてみた。

モデル構造
各次元 26-8-2-8-26 で構成されたVAE。最初はencoderとdecoderにもう一層加えてたけど、入力ベクトルの次元26に対して過剰過ぎる(過学習しそうな)気がしてやめた。

既存車両の2次元平面上での表現
さて、前置きが長くなったが結果である。
学習後のVAEの前半部分であるencoderに学習データである計70両のデータを入力した。出力として得られた各車両に対応した2次元ベクトルの値をプロットすると以下のようになる。

すごくない?
VAEには車両の性能をベタッと与えてるだけなのに、車両の種類や特性をかなり正確に表現できてるように見える。

ざっくり分類するとこんな感じか。
よく知らないままつっこんだ"UDES 15/16"、軽戦車に紛れてるけど調べてみたら中戦車。重量の軽さとか薄い装甲あたりで判断されてそう。
てかなんでSheridanこんなとこにいるの…って思ったらtanksggのデフォルト表示だとSheridanの砲が152mm。軽戦車のくせに圧倒的な単発火力を誇るせいで、自走砲とも駆逐戦車ともつかない謎な位置につっこまれるの面白い。拡散の悪さも効いていると思われる。
さて、上記の2次元空間だが、実は表示範囲を縦軸・横軸ともに-2.0~2.0に絞っている。この範囲外にも合計7両の戦車がマッピングされている。
その中には以下の車両も含まれるので、各車両がどの辺にマップされるのか予想してほしい。
・Conqueror GC
・B-C 155 58
・Maus
では答え合わせ。

まあ自走砲は大体予想通りのところに固まるんだけど、バッチャ自走が他のオートローダー寄りに現れるのが素晴らしい。
超重の中でも特に装甲が厚いMausと五式が他の超重の延長線上に現れるのもしっくりくる。
Sタンクは一体どうした。
標準偏差は3.56となり、5300台に1台レベルの超レアな特徴として学習された。まあ、俯仰角+1°/+1°だったり、射界±3°だったり、駆逐なのに単発390とかいうのこいつだけだからね。隅っこ独り占めするのも仕方ないね。
ただ位置的に軽戦車の延長線上にいるのは謎。速度と単発のバランス的な判断でこの辺に置かれたか?
というわけでAutoencoderを用いることで、高次元の車両性能で表される戦車を2次元平面上にいい感じに表現できた。この後は圧縮されたベクトルを他のモデルの入力に使うなりお好きにどうぞ。
decoderを使った新車両の生成
encoderが情報を圧縮するものであった一方、decoderは圧縮された情報から元の情報を生成することができる。その際には、学習時に突っ込んだ既存車両以外の領域からも、なんとなくWoTの車両っぽいものが生成できる。
今回のモデルで具体的に見ていく。
例えば新しい車両を追加するにあたって、自走砲をもう1台追加しようと考えたとする。(ハーブか何かやっておられる?)
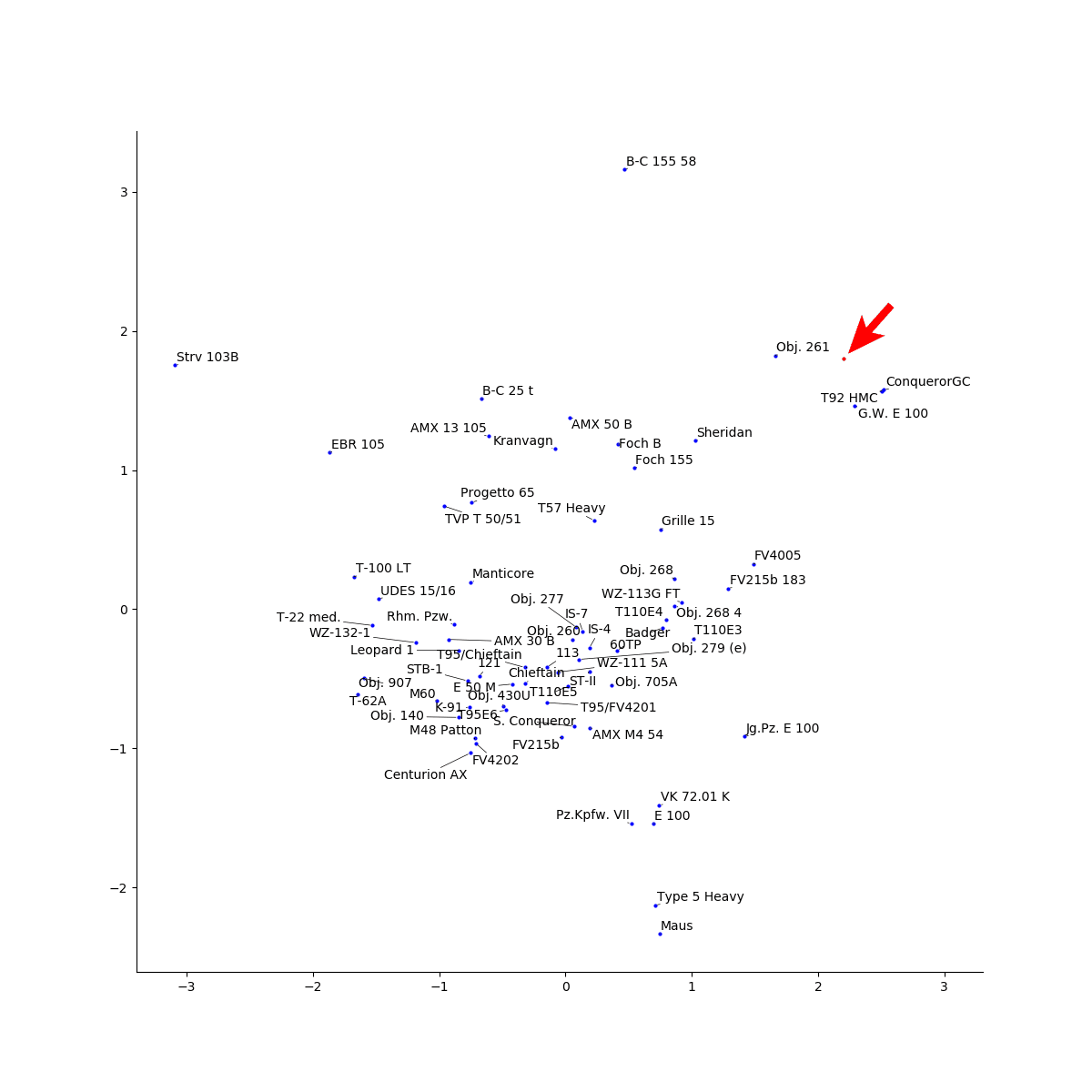
その場合、既存の自走砲が多く集まっている領域の近くから適当に点を選び、その情報をdecoderに突っ込む。すると他の自走砲に近いけどちょっと異なる車両が生成されるはずである。

実際に今回学習したdeceoderに上の図の赤丸を入力すると以下のような車両が生成された。

すごくない?
誰がどう見ても自走砲の性能そのもの。obj261とT92の間の領域から選んだだけあって、両者の中間くらいの速度や単発の車両が生成された。
このようにVAEでは学習した車両の間の領域についても、連続的に車両の特徴を表現している。
もうひとつくらい試してみよう。

狙いとしては、オートローダー領域で全周砲塔持ちに近づけつつ単発大きい駆逐に寄せておまけに自走砲を隠し味に加える…。

今は亡き ”Waffenträger auf E 100" っぽい車両を生成してみた。
(ほぼ)全周砲塔持ちで、単発600を2.6秒間隔で4発ぶっぱなす車両ができた。
砲塔装甲厚の"1"がいい味出してる。隠し味に自走砲を加えたかいがあった。
というわけでdecoderを用いることで、WoTの車両らしい特徴を持った新車両を生成することができた。
おまけ
実装
Python 3.7.2 + TensorFlow 2.1.0 + Keras 2.2.4 で実装。
import tensorflow as tf
from tensorflow.keras.layers import InputLayer, Dense, Lambda, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import backend as K
from tensorflow.keras.losses import mse
from tensorflow.keras.utils import plot_model
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import wot_tank_data as tank
def sampling(args):
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
# by default, random_normal has mean = 0 and std = 1.0
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
train_x, _ = tank.load_data() #pandas DataFrame
m = train_x.mean(axis='columns')
m.name = 'mean'
s = train_x.std(axis='columns')
s.name = 'std'
train_x = train_x.add(-m, axis=0).div(s+1e-12, axis=0)
x_dim = len(train_x)
np_train_x = train_x.values
np_train_x = np_train_x.T
np_train_x = np_train_x.astype('float32')
inputs = Input(shape=(x_dim, ), name='encoder_input')
x = Dense(8, activation='relu')(inputs)
z_mean = Dense(2, name='z_mean')(x)
z_log_var = Dense(2, name='z_log_var')(x)
z = Lambda(sampling, output_shape=(2,), name='z')([z_mean, z_log_var])
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
latent_inputs = Input(shape=(2,), name='z_sampling')
x = Dense(8, activation='relu')(latent_inputs)
outputs = Dense(x_dim, activation='linear')(x)
decoder = Model(latent_inputs, outputs, name='decoder')
outputs = decoder(encoder(inputs)[2]) #encoder (inputs) = [z_mean, z_log_var, z]
vae = Model(inputs, outputs, name='vae_mlp')
reconstruction_loss = mse(inputs, outputs)
reconstruction_loss *= x_dim
kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
vae_loss = K.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
history = vae.fit(np_train_x,
epochs=5000,
batch_size=8,
shuffle=True)
vae.save_weights('vae_mlp_tank.h5')
reduced = encoder.predict(np_train_x)[0]
sc = plt.scatter(reduced[:, 0], reduced[:, 1], s=2)
for i in range(len(reduced)):
plt.annotate(train_x.columns[i],
xy=(reduced[:, 0][i],reduced[:, 1][i]),
xytext=(0,0),
size = 6,
textcoords='offset points'
)
plt.legend()
plt.savefig('encoded_x.png')
plt.show()
入力データの用意について
tanksggからかなり泥臭い方法で取得・整形。スクレイピングとかそんなことはできません。実装コードは恥ずかしくてとても人に見せられない。
入力ベクトルの処理について
今回は入力を標準化して突っ込んでいる。decoderの出力で得られる復元ベクトルは、元の入力ベクトル(車両性能値)の平均と分散を使って車両性能値に戻してあげる。
入力ベクトルの選定について
今回は車両性能のうち「これは車両を特徴づける上で重要だろう」と思う要素を自分で選んだ。また、AEは入力した要素それぞれが「WoTの車両らしさ」にどれだけ重要かは判断せず、一律で圧縮された情報に含めてしまう。
この辺も全部モデルにやってもらうには、入力に全性能値、出力に車両勝率やDPG、平均スポット数とかを与えるモデルで学習をすればいいじゃなかろうか。次元圧縮のみを目的とするならね。

例えば性能値のうち車両価格は勝率に影響しにくいので圧縮される情報に含まれない的な。
書いてて思ったけど勝率とかDPGをAEの入出力にした方が直接的では? それか勝率とかの情報を今回のモデルの入力に追加するとかでも良かったかも。
こういう改善点とか思いつくのは自分がWoTについてある程度知識があるからで、そういった意味で自分が良く知る内容をテーマに選ぶの大事。
decoder出力層の活性化関数について
VAEの入力ベクトルを正規化したうえで、出力層の活性化関数をsigmoidにすることも考えた。しかし学習データ内の最大最小を超えるような性能値も出力してみたかったので標準化&linearの組み合わせで実施。100km/hくらいでかっとんでいく車両とか単発3000の車両と生成できたら面白いじゃん?
まあ出力層の活性化関数をlinearにしたことで学習は難しくなってると思う。
学習データ数と潜在変数の次元について
潜在変数の次元2に対して入力ベクトルの次元26、学習データ数70って正直どうなんかね。特徴空間に対して学習データが疎で簡単に過学習しそうな気がするから、denoising AEにして汎化性能挙げるといい感じなんだろうか。
過学習について
上記で説明した通り、出力層の活性化関数がlinear、学習データが少ないということからすでに過学習気味になっていると思われる。今回は生成が上手くいった例を選んで紹介したが、学習データの分布領域より外側を使ってdecodingすると速度や装甲が平気でマイナスになったりする。WoTの車両ってカタログスペックだけ速度が異常に速い車両がいたり(IS-7とか)、垂直装甲と傾斜装甲があるから性能値の装甲厚が車両の特性の実態を反映してなかったり(SタンクとEBR 105の全面装甲値は40mmで一緒なんですよ)で、かなり非線形性が強い特徴空間になっていると思われる。学習データの復元性はある程度捨てて、汎化性能を上げたモデルを試してみるのが次のステップか。
参考
The Keras Blog, Building Autoencoders in Keras
https://blog.keras.io/building-autoencoders-in-keras.html
Keras variational autoencoder example - usage of latent input
https://stackoverflow.com/questions/50590536/keras-variational-autoencoder-example-usage-of-latent-input
すごく助かった。
この記事が気に入ったらサポートをしてみませんか?