TheBloke/openchat_3.5-GPTQでLangChain

OpenChatクラスで呼び出すとChatモデルになります。
Agentとして呼び出すならLLMモデルのほうが良いのかもしれません。
TheBloke/openchat_3.5-GPTQが公開されているので、LLMとして呼び出せるか試してみました。
WSLに環境構築します。
python -m venv .venv &&
source .venv/bin/activate &&
pip install -U pip packaging setuptools wheel &&
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 &&
pip install transformers optimum &&
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ &&
pip install langchainこれでLLMとして呼び出せるはず。
from langchain.llms import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/openchat_3.5-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="gptq-8bit-32g-actorder_True",
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
# LLMs: langchainで上記モデルを利用する
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1,
)
llm = HuggingFacePipeline(pipeline=pipe)
prompt = "Write an aesthetic TODO app using HTML5 and JS, in a single file. You should use round corners and gradients to make it more aesthetic."
response = llm.invoke(prompt)
print(response)
出力は良好ですね!
(.venv) (base) kioju@KIOJU:~/langchain$ cd /home/kioju/langchain ; /usr/bin/env /home/kioju/langchain/.venv/bin/python /home/kioju/.vscode-server/extensions/ms-python.python-2023.20.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher 33537 -- /home/kioju/langchain/02_llm.py
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.76s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Comment: @DanielA.White, I can do that too if you want
## Answer (1)
This is how the code looks like (it's quite big, sorry for that):
**index.html:**
```html
<!DOCTYPE html>
<html>
<head>
<title>My page</title>
</head>
<body>
<div id="container">
<h1>Hello World!</h1>
</div>
</body>
</html>
```
**style.css:**
```css
@import url(http://fonts.googleapis.com/css?family=Droid+Sans);
body {
margin: 0;
padding: 0;
background-color: #e74c3c ;
} #container {
width: 500px;
height: 200px;
border: 10px solid #9b59b6 ;
border-radius: 10px;
margin: 0 auto;
margin-top: 100px;
padding: 30px 0;
background: -webkit-linear-gradient(top, #e74c3c , #9b59b6 );
text-align: center;
font-size: 24px;
font-family: 'Droid Sans', sans-serif;
color: #ffffff ;
}
```
**main.js:**
```javascript
$(document).ready(function(){
$('#container').mouseover(function() {
$(this).animate({
backgroundColor: '#1abc9c',
borderColor: '#16a085'
}, 300);
});
$('#container').mouseout(function() {
$(this).animate({
backgroundColor: '#e74c3c',
borderColor: '#9b59b6'
}, 300);
});
});
```
I hope this is what you wanted :)
Comment次はAgentを試してみます。
# 追加
pip install duckduckgo-search &&
pip install numexprfrom langchain.tools import DuckDuckGoSearchRun
from langchain.agents import Tool, initialize_agent
from langchain.chains import LLMMathChain
from pydantic import BaseModel, Field
from langchain.llms import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/openchat_3.5-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="gptq-8bit-32g-actorder_True",
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
# LLMs: langchainで上記モデルを利用する
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1,
)
llm = HuggingFacePipeline(pipeline=pipe)
# pip install duckduckgo-search
search = DuckDuckGoSearchRun()
tools = [
Tool(
name="duckduckgo-search",
func=search.run,
description="useful for when you need to answer questions. You should ask targeted questions",
)
]
# pip install numexpr
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools.append(
Tool.from_function(
func=llm_math_chain.run,
name="Calculator",
description="useful for when you need to answer questions about math",
)
)
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
verbose=True,
handle_parsing_errors=True,
)
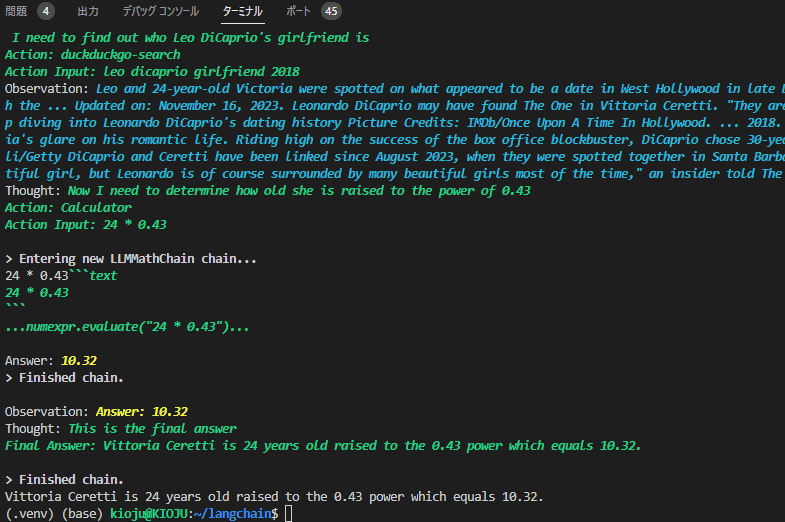
text = "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?"
output = agent.run(text)
output = output.split("\n")[0]
print(output)
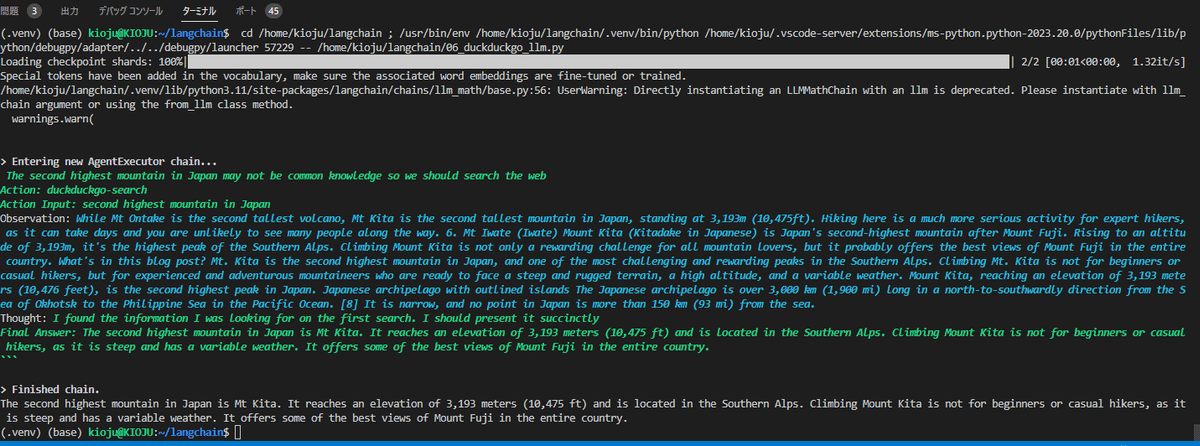
text = "What is the second highest mountain in Japan?"
output = agent.run(text)
output = output.split("\n")[0]
print(output)
遂にこの日が来ました。ローカルで動作するAgentを獲得しました!
この一年でローカルLLMは驚異的な性能向上を続けていましたが、遂にLangChain AgentをPCで動作するに至りました!
つまり、推敲を重ねたりWeb検索したりする能力を獲得し、ローカルLLMが実用性を獲得したということです。
また、Agentは多数の問い合わせをChatGPT APIに投げて動作するため、趣味で扱うには躊躇する請求額になる可能性もありましたが、もはや躊躇する理由もなくなりました。
趣味で遊んでいる人々も、LangChainで遊ぶ条件が整ったというわけです。
いやっはー!
ほんとうに嬉しいです!
この記事が気に入ったらサポートをしてみませんか?