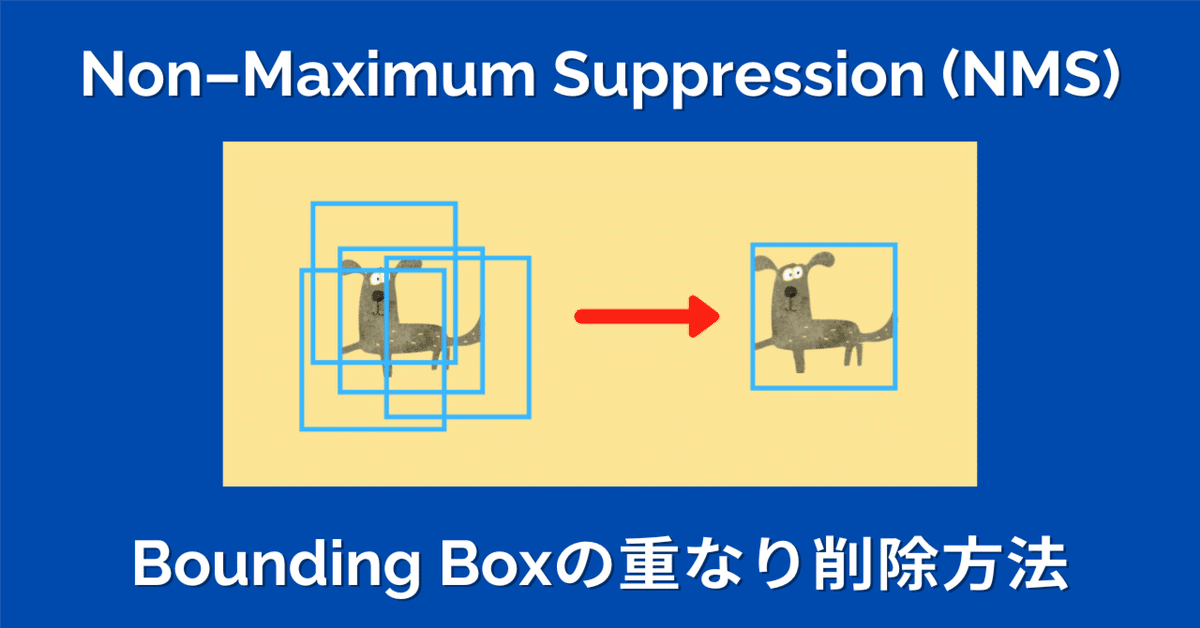
【物体検出】 Non-Maximum Suppression (NMS)で余分なBounding Boxを削除する

YOLOやSSDが出力するBounding Box(下図の青色の矩形領域)は予測された物体の位置を示すものですが、物体検出のモデルは初めから一つの物体に対して一つだけのBounding Boxを予測しているわけではありません。

実は、NMSと呼ばれる後処理を行うことで確実性の高いBounding Boxだけが残るようになっています。
今回はこの方法について解説します。
重なりあったBounding Box
物体検出モデルが予測した全てのBounding Boxを描くと下図のようにたくさんの重なり合ったBounding Boxが表示されてしまいます。
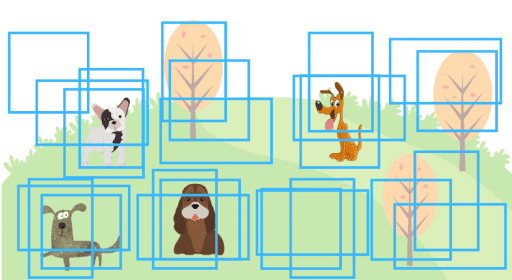
物体検出のモデルはBounding Boxと共にスコア(Score)も予測します。このスコアはBounding Boxの中に犬がいるかどうかの確率を示します。これはモデルの主観的な確率なのでモデルが予測に対してどれほどの自信があるかを表しているとも言えます。このBounding Boxに犬がいるのは50%、あのBounding Boxは75%の自信があるといった感じです。この自信の度合いによってどのBounding Boxがより重要なのか(あるいは不要なのか)の判断をします。そういった意味でランク付の手段としての意味合いが強いので、この記事では単純にスコアと呼びます。
YOLOやSSDなどのモデルは1つの画像に付きたくさんのBounding Boxを予測しますが、Bounding Boxどうしの関係を気にすることはないので重なり合ってしまうのが通常です。その代わりにスコアを使って後から不要なものを取り除くようにします。
また、話を単純にするために、はじめのうちは検出する物体は犬だけと仮定しています。それでもNMSの本質は変わりません。あとで、複数のクラスを扱うケースについても触れます。
NMSは後処理
これまで何度か繰り返し登場してきたNMSという言葉ですが、Non-Maximum Suppressionの略称で、直訳すれば「最大でないもの(非最大なもの)を抑圧する(取り除く)」となります。
このNMSは後処理であり、モデルの推論結果に対して実行されます。予測されたBounding Boxが重なっている場合にスコアの低いものを除外していく処理になります。
このNMSの仕組みを物体が一つだけの例で説明します。物体がたくさんあっても同じですが、説明が不必要に長くなるので単純なケースを使います。例えば、下図のようにBounding Boxが重なっていたとします。

それぞれのBounding Boxにはスコアがあります。全てのBounding Boxをスコアによってソート(順番をスコアが高い順位から低い順位へと並べること)をします。赤いBounding Boxのスコアが一番高いとします。
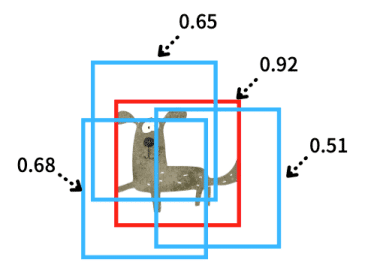
赤いBounding Boxとその他のBounding Boxとの重なり具合をスコアの高い方から順番に計算していきます。
重なり具合は、IoU(Intersection over Union)で測ります。
IoUを簡単に説明すると、下図の黒い重なった部分が赤と青で囲まれた領域に占める割合のことです。IoUは0から1の数値で、赤と青の矩形領域が完全にマッチしていればIoUは1になります。全く重なりがなければIoUは0です。

赤のBounding Boxと青のBounding BoxのIoUが0.5以上だったら青のBounding Boxは赤のBounding Boxと同じ物体を予測しているとみなし、スコアがより低い青のBounding Boxを取り除きます。ここでいう0.5はIoUの閾値(Threshold)であり設定で変更できるようになっています。
上記の作業を繰り返すことによって、最終的には一つのBounding Boxだけが残ることになります。

犬が複数いる場合でもNMSのやり方は同じです。
全てのBounding Boxをスコアでソートして順番に重なっているBounding BoxをIoUのThresholdで判断して取り除いていくという手順になります。
NMSの手順のまとめ
選択されたBounding Boxの出力用に空のリストを準備する。outputs=[]
全てのBounding Boxをスコア順にソートする。bboxes
bboxesの中で一番高いスコアのBounding Boxを取り出しoutputsに入れる。
取り出したBounding Boxとbboxes内のBounding BoxとのIoUを計算しThreshold(例えば0.5)以上だったらbboxesから取り除く。
bboxesが空になっていないなら、ステップ3から繰り返す。
最後に、outputsを返す。
こうして、スコアの高い独立したBounding Boxだけが残ります。
なお、PyTorch(Torchvision)に実装があります。YOLOv5でも使用されています。
NMSの解説は基本的には以上になりますが、いくつか注意点があります。
複数のクラスを扱う場合
犬だけでなく複数のクラスを扱う場合は、クラスごとにNMSの処理を行います。
例えば、犬と猫が重なった位置にいる場合にはBounding Boxは重なっていますがクラスが異なるので取り除かれることはありません。
しかし、COCOのデータセットではクラスが80もあるので何度もNMSを呼び出していると実行速度が遅くなってしまいます。
よって、YOLOv5などの実装ではクラスごとにBounding Boxのxy座標をずらして異なるクラスのBounding Boxで絶対に重なりがないようにしておいてから、1つの画像に対して1回のNMSの処理を呼びだすといった工夫がなされています。
スコアが低いものはNMSの前に取り除く
NMSの計算はBounding Boxの数によってどんどん遅くなります。

よって、NMSを実行する前に、あらかじめスコアの低いBounding Boxを取り除いておきます。
例えば、スコアが0.0001とかだとそもそも正解でない可能性が高いので除外しておきます。そのため、モデルの設定としてスコアに対しても閾値(Threshold)を指定できるようになっているのが普通です。
このスコアのThresholdによっては、かなりの数のBounding Boxを削除することが可能です。

Bounding Boxの数が減るとNMSの処理速度は速くなりますが、次に述べるようにmAPが低くなる可能性もあります。
NMSの処理速度とmAPとの関係
NMSはスコア順に行う作業なので並列処理(例えばGPUを使うこと)ができません。CPUで実行されます。
よって、Bounding Boxの数が増えれば増えるほど時間がかかるので、NMSに渡すBounding Boxの数に上限を設けたりします。
例えば、上限が30,000だったら、スコアの順にトップ30,000個のBounding BoxだけをNMSに入力します。通常そんなにたくさんの正解がある画像はないのでこれでも問題はありません。
また、前述したように、あらかじめスコアの低いBounding Boxを取り除いておくとBounding Boxの数が減り処理がはやくなるのでスコアのThresholdで調整します。
ただし、スコア(自信)が低くても実際には正解のBounding Boxがある場合もあります。Bounding Boxを取り除きすぎると正解が減ってmAP(mean Average Precision)が低くなる可能性があるので、スピード重視か正確さ重視かによってスコアのThresholdを調整します。
YOLOv5のスピードテストやmAPのレポートをよく見るとこのあたりのパラメータを調節しているのがわかります。例えば、スピードを早くしたい場合はスコアの閾値を0.25に設定し、mAPをよくしたい場合にはスコアの閾値を0.001にしています。
AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS.
Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
上記の設定を見ると、スピードテストではIoUのThresholdも低く設定しているので、少しでも重なりがある場合はどんどん除外するようにしてNMSの実行時間を短くしているようです。
参照
Non-maximum Suppression (NMS)
https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c
この記事が気に入ったらサポートをしてみませんか?