
Gymで強化学習⑩動的計画法:準備編

前回の記事では動的計画法の理論の解説をしました。今回は動的計画法を実装するための準備を行います。
環境:凍った湖
取り上げるGymの環境はFrozen Lake(凍った湖)です。

目的はスタート地点(左上)からゴール地点(右下)へと穴に落ちることなく凍った湖の上を渡ることです。
行動
可能な行動は以下の4つになります。
0:左へ移動
1:下へ移動
2:右へ移動
3:上へ移動
観測値
この環境における地図のサイズはいくつかありますし、カスタマイズもできます。最初はデフォルトの4x4の地図を使います。後で8x8にも挑戦します。
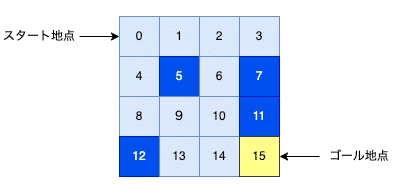
観測値としては位置情報が整数値として与えられます。4x4の地図では、16の位置があり、スタート地点は0でゴールは15です。なお、青い位置には穴があるので、そこに移動するとゲーム終了です。水色の部分は移動が可能な氷上です。
報酬値
報酬値としては以下の3つがあります。
ゴール到達:+1
穴に落ちる:0
氷上に移動:0
エピソードの終了条件
エピソードが終了する条件は以下になります。
ゴール到着
穴に落ちる
エピソード内で100ステップを越える(truncated=True)
なお、8x8の場合は最大200ステップまでになります。
Python環境の設定
この環境ではgymnasium[toy-text]をインストールします。例えば、以下のように venv を使って仮想環境を作ります。
# テスト用のフォルダを作る
mkdir frozen_lake
cd frozen_lake
#Pythonの環境を作る
python3 -m venv venv
source venv/bin/activate
# Pipを最新のものにしておく
pip install --upgrade pip
# ジムをインストール
pip install gymnasium[toy-text]
# 後で使うのでmatplotlibもインストール
pip install matplotlibFrozen Lake環境の生成
Frozen Lakeの環境を作るにはPythonスクリプトで以下のようにします。
import gymnasium as gym
env = gym.make('FrozenLake-v1')地図名の指定
map_name はデフォルトが"4x4"なので上記は以下と同じです。
import gymnasium as gym
env = gym.make('FrozenLake-v1', map_name="4x4")そのほかに map_name="8x8" を指定すると既存の 8x8 のマップを使うことができます。
import gymnasium as gym
env = gym.make('FrozenLake-v1', map_name="8x8")
また、map_name=None を指定すると 8x8 のマップをランダムに生成してくれます。
import gymnasium as gym
env = gym.make('FrozenLake-v1', map_name=None)自分の地図を作る
ちなみに自分でマップを作って使うこともできます。その際は、以下のように自分のマップを作成して desc に指定します。
my_map = ["SFFF", "FFFH", "FFFH", "FFFG"]
env = gym.make('FrozenLake-v1', desc=my_map)S … スタート地点(Start)
F … 凍った部分(Frozen)
H … 穴(Hole)
G … ゴール(Goal)
滑るかどうか
また、is_slippery(滑りやすい)という引数があり、デフォルトでは True です。True だと意図した移動が成功する確率が3分の1になります。
例えば、左へ移動する行動を選択しても3分の1で以下のどれかに決まります。
左へ移動
上に移動
下に移動
これを False に設定すると、移動が100%指示した通りに成功します。
import gymnasium as gym
env = gym.make('FrozenLake-v1', map_name="4x4", is_slippery = False)画像表示モード
画像を表示するモードを指定することもできます。render="human" と指定すると人間が見るための画像を表示します。
env = gym.make('FrozenLake-v1', render_mode="human")指定しなければ何も表示しないので速く動作しますが、必要な情報は自分でプリントすることになります。
ランダムなエージェント
以前に月面着陸の環境でランダムに行動するエージェントを作りました。同様にここでもランダムなエージェントを定義してエピソードを実行するプログラムの動作確認をします。
ランダムなエージェントは次のように定義します。以前と全く同様なのは 環境オブジェクト env のメソッドを利用してランダムな行動を選択しているからです。
import gymnasium as gym
class RandomAgent:
def __init__(self, env):
# エージェントの初期化
self.env = env
def reset(self, observation, info):
# 環境からの初期観測値を受け取る
pass
def act(self):
# 環境からランダムな行動を取得
action = self.env.action_space.sample()
return action
def learn(self, observation, reward, terminated, truncated, info):
# 観測値、報酬などを受け取る
pass以下のファンクションは与えられたエージェントを使って指定した回数のエピソードを実行します。
def run_episodes(env, agent, max_episodes):
# エピソードのループをmax_episodes回繰り返す
for episode in range(max_episodes):
# ゲーム環境を初期化してエージェントに初期観測値を渡す
observation, info = env.reset()
agent.reset(observation, info)
# 1つのエピソードのループ
while True:
# エージェントの行動を決定
action = agent.act()
# 行動を実行すると、環境の状態が更新される
observation, reward, terminated, truncated, info = env.step(action)
# エージェントの学習
agent.learn(observation, reward, terminated, truncated, info)
# ゲームが終了したら、次のエピソードへ
if terminated or truncated:
break
# 環境を閉じる
env.close()メインのファンクションでは環境とランダムに行動するエージェントを作成してエピソードを実行します。
def main():
# 環境を作成
env = gym.make('FrozenLake-v1', desc="4x4",
is_slippery=False, render_mode="human")
# ランダムエージェントを作成
agent = RandomAgent(env)
# エピソードを実行
run_episodes(env, agent, max_episodes=10)
if __name__ == "__main__":
main()以下にまとめたコードを掲載します。
import gymnasium as gym
class RandomAgent:
def __init__(self, env):
# エージェントの初期化
self.env = env
def reset(self, observation, info):
# 環境からの初期観測値を受け取る
pass
def act(self):
# 環境からランダムな行動を取得
action = self.env.action_space.sample()
return action
def learn(self, observation, reward, terminated, truncated, info):
pass
def run_episodes(env, agent, max_episodes):
# エピソードのループをmax_episodes回繰り返す
for episode in range(max_episodes):
# ゲーム環境を初期化してエージェントに初期観測値を渡す
observation, info = env.reset()
agent.reset(observation, info)
# 1つのエピソードのループ
while True:
# エージェントの行動を決定
action = agent.act()
# 行動を実行すると、環境の状態が更新される
observation, reward, terminated, truncated, info = env.step(action)
# エージェントの学習
agent.learn(observation, reward, terminated, truncated, info)
# ゲームが終了したら、次のエピソードへ
if terminated or truncated:
break
# 環境を閉じる
env.close()
def main():
# 環境を作成
env = gym.make('FrozenLake-v1', map_name="4x4",
is_slippery=False, render_mode="human")
# ランダムエージェントを作成
agent = RandomAgent(env)
# エピソードを実行
run_episodes(env, agent, max_episodes=10)
if __name__ == "__main__":
main()
上記のコードを fronzen_lake.py という名前でセーブしたとします。これを走らせるには準備したPythonの環境で以下を実行します。
python frozen_lake.pyランダムに移動するエージェントの様子が見れたら環境の設定は成功です。
手動エージェント
以前に月面着陸の環境で手動エージェントを作りました。ここでも同様に手動エージェントを作り、自分でエージェントを動かしてみます。
基本的な仕組みは以前と同じです。コマンド・プロンプトから行動の数値を入力してエージェントを動かします。何も入力しないで ENTER キーを押すと前回の行動が継続して選択されます。
class ManualAgent:
def __init__(self, observation):
pass
def reset(self, observation, info):
# 環境からの初期観測値を受け取る
self.action = 0
def act(self):
# 手動でアクションを入力。何も入力しなければ前回のアクションを継続
# 0: 左
# 1: 下
# 2: 右
# 3: 上
while True:
action = input(f"アクションを入力(現在のアクション{self.action}): ")
if action == "":
break
if action in ["0", "1", "2", "3"]:
self.action = int(action)
break
print(f"{action}は不当な行動です")
# アクションを保存
print(f"アクション: {self.action}")
return self.action
def learn(self, observation, reward, terminated, truncated, info):
# 報酬などを表示
print(f'観測値: {observation}')
print(f'報酬 : {reward:6.3f}')
print(f'終了 : {terminated}')
print(f'切断 : {truncated}')
print(f'情報 : {info}')
print('-' * 20)このコードを frozen_lake.py に追加します。例えば、RandomAgent のコードの下にコピーしてください。
また、このエージェントを使うには main を少し書き換えます。
def main():
# 環境を作成
env = gym.make('FrozenLake-v1', map_name="4x4",
is_slippery=False, render_mode="human")
# ランダムエージェントを作成
#agent = RandomAgent(env)
agent = ManualAgent(env) # <= 手動エージェントを指定
# エピソードを実行
run_episodes(env, agent, max_episodes=10)これを python frozen_lake.py で実行し、自分でエージェントを動かしてみてください。
状態遷移の確率と最適なポリシー
この記事が気に入ったらサポートをしてみませんか?