
トランスフォーマーの自己アテンションの理解⑧デコーダ・ブロックの詳細

本シリーズの記事リスト
第一弾 トークン数値化の歴史
第二弾 再帰による文脈伝搬
第三弾 レコメンダーと内積
第四弾 位置エンコーディング
第五弾 エンコーダ・デコーダ
第六弾 クエリとキーとバリュー
第七弾 エンコーダ・ブロックの詳細
第八弾 デコーダ・ブロックの詳細
この記事では、デコーダ・ブロックの詳細を解説をします。論文の図1の右側になります。

特に、デコーダ・ブロックの内部にあるマスクされたマルチヘッド・アテンション(Masked Multi-head Attention)とソースターゲットのアテンション(Source-Target Attention)を重点的に解説します。
では、さっそく始めましょう。
デコーダによる自己回帰
第五弾で解説しましたが、まずはデコーダによる自己回帰の仕組みを簡単に復習します。そのほうが後の話がわかりやすくなります。
トランスフォーマーではエンコーダ・ブロックとデコーダ・ブロックが多階層に連なっており、自己アテンションのプロセスを何度も踏むことで文脈が各トークンへと吸収されていきます。
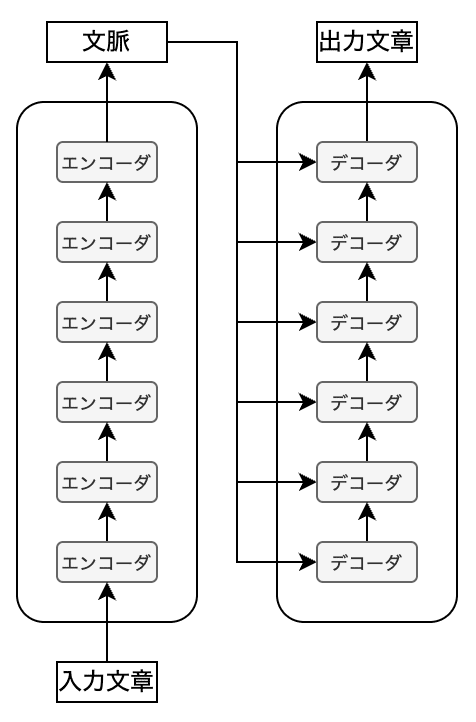
デコーダは自己回帰によって翻訳の出力文章を積み上げていきます。デコーダへの最初の入力は、文章の始まりを意味する<SOS>(Start Of Sentence)です。同時に、エンコーダからの文脈も入力として与えます。これらをもとにデコーダは最初のトークンを予測します。
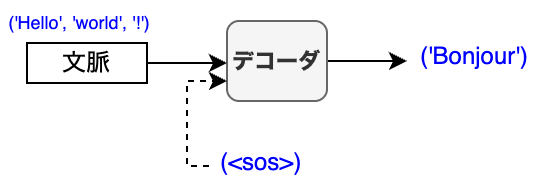
デコーダへの次の入力は、<SOS>に前の出力を足したものになります。
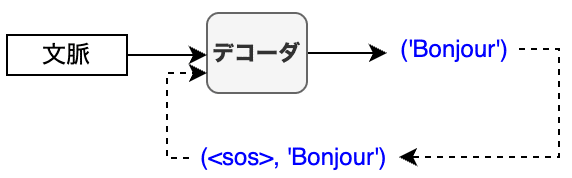
同様の処理を続けていきます。

つまり、デコーダへの入力文章は、<SOS>から始まって徐々に積み上げられていきます。言い方を変えると、デコーダへの入力文章は、デコーダからの出力文書に<SOS>を足した(出力文章を右にシフトした)ものです。

最後はデコーダが<EOS>を予測することで翻訳が終わります。

しかし、訓練を行う際にトークンを一つ一つ積み重ねる方法は効率的ではありません。できればデコーダへの入力文章は一度で済ませたいものですが、自己回帰を行う限り無理です。もっと欲を言えば、複数の文章をまとめてバッチにして効率的に訓練したいのですが、不可能に見えます。
トランスフォーマーの訓練ではこれらの問題が解決されています。特にマスクされたマルチヘッド・アテンションが重要になります。順を追って一つ一つ見ていきましょう。
この記事が気に入ったらサポートをしてみませんか?