
ビジョン・トランスフォーマーとは

画像分類はコンピュータビジョンにおいて重要なタスクの1つです。従来の画像分類のアプローチとして、畳み込みニューラルネットワーク(CNN)があり、定番の手法として定着していました。
2020年、Google Brainチームは、CNNを使用しない画像分類モデルであるビジョン・トランスフォーマー(Vision Transformer、ViT)を開発しました。 ViTは、分類のために画像パッチのシーケンスに直接トランスフォーマーのエンコーダーを適用します。
最近(2023年2月)では、220億のパラメータを使ったViTモデルの訓練に成功しています。巨大言語モデルと同様にビジョン系のモデルも巨大化が進んできているのが見受けられます。
では、そもそもViTとはどのような仕組みを持つのでしょうか。この記事では、ViTがどのように機能するかについて解説します。
パッチのシーケンス
ViTのアイデアはシンプルです。画像を分割したものを埋め込みベクトルとして扱うことで、言語モデルのようにトランスフォーマーのエンコーダを利用するというものです。
例えば、画像から16x16の大きさの画像情報を一つの埋め込みベクトルとします。これをパッチ(Patch)と呼びます。画像からパッチを取り出し、並べたものは、言語モデルの埋め込みベクトルのシーケンス(順番に並べたもの)と同じように扱うことができます。
具体的には、ViTは形状$${H \times W \times C}$$(Height、Width、Channel;高さ、幅、チャンネル)の画像を平坦化(フラット化)されたパッチのシーケンスに変換します。

一つのパッチには$${P^2 C}$$個の値が入っています。ここでPはパッチサイズです。パッチの数Nは以下のように計算できます。
$$
N = \frac{HW}{P^2}
$$
画像の大きさが320 x 320でチャンネル数が3(RGB)、そしてパッチサイズ(バッチサイズではありません)が16だとすると、一つのパッチには$${16^2 \times 3 = 768}$$個の値があることになります。また、パッチの数は次のように計算できます。
$$
N = \frac{320 \times 320}{16^2} = 400
$$
つまり、一つの画像は400個のパッチからなるシーケンスであり、一つのパッチには768個の値が入っています。
パッチの埋め込み
ViTは、線形層を使用して、パッチを$${P^2 C}$$から$${P^2 D}$$に変換します。ここで$${D}$$は、トランスフォーマーエンコーダーで使用する埋め込みベクトルのサイズです。このように変換されたベクトルを「パッチ埋め込み」(Patch Embeddings)あるいは「埋め込みされたパッチ」(Embedded Patches)と呼んでいます。
画像から来たので我々は埋め込みされたパッチと呼んでいるわけですが、トランスフォーマーからすれば数字の集まりに過ぎません。言語からのものか画像からのものかは関係ありません。トランスフォーマーはひたすら埋め込みベクトル間の関係をアテンションの機能で読み取り特徴を抽出します。

位置埋め込み
なお、言語モデルと同様で、各画像パッチの位置の情報を埋め込みに追加する必要があります。やはり画像でも位置関係は重要だからです。
オリジナルのトランスフォーマーではトークンの位置をベクトルとして表現する位置エンコーディングをあらかじめ各トークンに対して計算していましたが、ViTでは位置情報を学習させています。よって、位置の埋め込みを行っているので位置埋め込み(Position Embedding)と呼んでいます。役割としては位置エンコーディングと同じです。

論文によると、画像なので2次元の位置を考慮した位置埋め込みをテストしています。ちなみに、2次元の位置埋め込みでは埋め込みの半分をパッチの横軸の位置、残りの半分をパッチの縦軸の位置を表現するために使いました。しかし、結論として1次元(順番通り)の位置埋め込みで十分だったとのことです。
下図にあるように紫色の0、1、2、… が位置埋め込みを意味しています。実際にはパッチ埋め込みと同じ次元数を持つベクトルになります。

1次元の位置埋め込みが有効な理由としては学習によって位置埋め込みが2次元におけるパッチの関係を習得しているからだと論文では結論付けています。
いずれにせよ、位置埋め込みがないより、あったほうが性能が良くなるのは確かなのが実験結果からわかっています。
よって、埋め込みパッチのシーケンスに、位置埋め込みを混合(ベクトル同士の要素ごとの足し算)してからトランスフォーマーのエンコーダーにフィードします。
エンコーダによる特徴量の抽出
ViTはトランスフォーマーのエンコーダを使って入力のシーケンスからの特徴量を抽出します。このような手法はBERTのアプローチによく似ています。BERTもまたエンコーダをベースにしています。
エンコーダはエンコーダ・ブロックが複数の階層になっています。最後のエンコーダ・ブロックからの出力は画像からの様々な特徴や画像内の情報の関係などが抽出したものが含まれます。
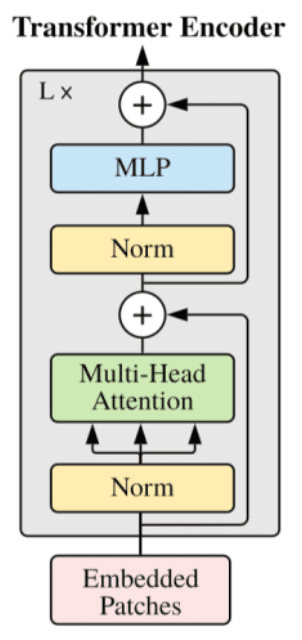
また、画像からの特徴量を抽出するという意味ではCNNが特徴量を抽出するのに似ています。この特徴量を使って画像分類を行うのでCNNの畳み込み層をトランスフォーマーのエンコーダに置き換えたものと考えるとイメージが湧きやすいでしょう。
ただし、CNNには画像固有の帰納バイアスがあります。帰納バイアスとは学習対象から結論を導く過程である種の前提条件を制限として加えることです。
たとえば、畳み込みカーネルには、2次元近傍関係を処理することで位置に依存しない特徴を抽出します。これは遠くのピクセルとの関係を考えないことを意味します。CNNではそのために最大値プーリングを使って画像からの情報を圧縮していく必要があります。
ViTはトランスフォーマーのアテンションの仕組みを使うので特徴量の抽出は画像全体(グローバル)に行われます。ViTが唯一の画像の2次元構造を考慮するのは、画像をパッチに切り取るときのみです。つまりCNNと比べて前提条件が少なく帰納バイアスが少なくなっています。
位置埋め込みは1次元であるし、ViTが2次元にあまり依存しないことが非常に興味深くもあります。
分類用のトークン
画像分類を行うために、入力のシーケンスに分類用のトークン(パッチ埋め込み)を一番最初に追加しています。この分類用のトークンは特別な埋め込みになり、これもまた訓練によって学習されます。数の*とマークされているピンクのものが分類用のトークンで画像から来たものではありません。
これもまたBERTが特別な分類トークン[CLS]を使うのに似ています。特別トークンをシーケンスに前置し、最終的な隠れ状態が分類タスクに使用される画像パッチからの情報を集約した表現になります。
つまり、エンコーダを通して分類用の埋め込みへ画像からの特徴量が吸収されていきます。これが画像を分類するための層へと渡されます。上図でMLP-Headと呼ばれている部分です。
MLPはMulti-Layer Perceptron(複数層の層のパセプトロン)の略称ですが、要するに複数の線形層と活性化関数からなるよくある分類のための最後の層でヘッド(Head、頭)と呼ばれます。それは特徴量を抽出する部分をバックボーン(背骨)と呼ぶのと対比しているからです。
まとめるとヘッドの部分は複数の線形層を使って分類の判断を下します。なお、活性化関数にはGELUが使われています。
実装でのトリック
公式の実装では、畳み込みを利用してパッチから埋め込みベクトルへと変換してみます。
畳み込みを行う際に、カーネルサイズ = パッチサイズ(16 x 16の場合は16)にして、ストライドも同じサイズ(= 16)、出力チャンネル(フィーチャー)を埋め込みベクトルのサイズ(D)にします。
すると、16 x 16 x 3の画像パッチがサイズDの埋め込みベクトルになります。
よって、畳み込み層によって埋め込みベクトルのグリッドが作られるので、後でフラット化すれば埋め込みベクトルのシーケンスになります。
x = nn.Conv(
features=self.hidden_size,
kernel_size=self.patches.size,
strides=self.patches.size,
padding='VALID',
name='embedding')(
x)ViTの種類
ViTには層の数や埋め込みの次元数やパラメータの数などによって、いくつかのモデルがあります。ViT-Baseが最も小さいバージョンです。ViT-Large、ViT-Hugeとモデルが大きくなります。

下図に示すように大きなモデルほど画像分類の精度が高くなっています。ResNetやEfficientNetと比べても性能が上まっています。

なお、ViT-H/14となっているのはVit-Hugeのモデルでパッチサイズが14 x 14であるという意味です。
事前学習の効果
CNNを画像分類などで使うときによく転移学習が行われます。これは大きなデータセットであらかじめ学習してモデルを他のデータセットやタスクに対して微調整するものです。
言語モデルの世界でも事前学習とファインチューニングの組み合わせで同様なことが行われてきました。
ViTに関しても以下の表にあるように、ImageNet、ImageNet-21k、JFT-300M(Googleの独自のデータセット)などで事前学習を行い、下流タスクのデータセットで微調整してパフォーマンスを測定しました。

ViTはより大きなデータセットで事前トレーニングされた場合により優れたパフォーマンスを発揮することがわかりました。これは、BERTがより大きなデータセットで事前トレーニングされた場合により優れたパフォーマンスを発揮するのと似ています。
アテンションの効果
論文では、ViTが画像のどこに注目しているのかを調べています。
以下は、ViTno出力トークンから得たアテンションの情報を入力空間へ投影した結果です。 ViTが画像の主要なオブジェクトを捉えているのがわかります。特に最初の2つの例でその傾向が顕著に表れています。

自己教師あり学習
論文ではViTでBERTのような自己教師あり学習を実験したことについて述べられています。BERTでは文章にマスクをしてその言葉を予言さえる訓練を行いました。これはデータにラベルをつける必要がないので自己教師あり学習と呼ばれます。
ViTでマスクされたパッチを予測する事前学習を実験しました。小さなViT-B/16モデルでは、ImageNetで79.9%の精度を達成し、ゼロから教師あり学習をするのと比較して2%の改善が見られました。ただし、教師あり学習による事前学習をしたほうが自己教師あり学習による事前学習よりも4%良い性能が見られるので、自己教師あり学習による事前学習の効果は限定的でした。この方向は今後の課題だと論文では述べられています。
スケーリングの法則
言語モデルではパラメータの数を増やすと性能が良くなることが多々あり、これをスケーリングの法則(Scaling Law)と呼びます。このためGPTやBERTは巨大言語モデルになっています。
これと同様のことがビジョン・トランスフォーマーにも当てはまるでしょうか。つまり、パラメータの数を増してより精度の高いビジョン・モデルを構築するのは可能なのか。
論文では、ViTのさらなるスケーリング(数十億のパラメーターまで)が、おそらく性能の向上につながると述べています。これは、後の研究で2021年のScaling Vision Transformers論文で確認でされています。
また先日(2023年2月)に発表されたScaling Vision Transformers to 22 Billion Parametersでは220億のパラメータを使ったモデルの訓練に成功し、セマンティック・セグメンテーションや画像から深度(奥行き)の予測を行う実験を成功させています。

訓練で使うJFTのデータセットも40億個の画像を含むまでに拡大されたそうです。しかし、まだ言語モデルと比べるとパラメータ数が比較的少ないと言えます。
今後はトランスフォーマーをベースにしたより強力な画像モデルが出現することでしょう。
参照
この記事が気に入ったらサポートをしてみませんか?