
NumPyを使ったGPT-2の不必要に小さな実装

Twitterで「NumPyを使ったGPT-2の不必要に小さな実装」といったツイートを何度か見かけたのでちょっと調べてみました。なんと60行ほどでGPT-2を実装したリポジトリとブログ記事があったのですが、GPTの本質をついているのでここで解説します。
import numpy as np
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
return g * (x - mean) / np.sqrt(variance + eps) + b
def linear(x, w, b):
return x @ w + b
def ffn(x, c_fc, c_proj):
return linear(gelu(linear(x, **c_fc)), **c_proj)
def attention(q, k, v, mask):
return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v
def mha(x, c_attn, c_proj, n_head):
x = linear(x, **c_attn)
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), np.split(x, 3, axis=-1)))
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)]
x = linear(np.hstack(out_heads), **c_proj)
return x
def transformer_block(x, mlp, attn, ln_1, ln_2, n_head):
x = x + mha(layer_norm(x, **ln_1), **attn, n_head=n_head)
x = x + ffn(layer_norm(x, **ln_2), **mlp)
return x
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
x = wte[inputs] + wpe[range(len(inputs))]
for block in blocks:
x = transformer_block(x, **block, n_head=n_head)
return layer_norm(x, **ln_f) @ wte.T
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"):
logits = gpt2(inputs, **params, n_head=n_head)
next_id = np.argmax(logits[-1])
inputs.append(int(next_id))
return inputs[len(inputs) - n_tokens_to_generate :]
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
input_ids = encoder.encode(prompt)
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)オリジナルはこちらで参照できます。
GPT in 60 Lines of NumPy(作者:Jay Mody)
なお、訓練を行うことは出来ません。また、モデルのパラメータはOpenAIが公開しているものを読み込んで使っています。
よって、モデルのパラメータを読み込むコードが別のPythonスクリプトに書いてあるので実際には60行よりずっと多いのですが、モデルの実装に関して言えば60行ほどでコンパクトになっています。また、NumPyを使っており非常にすっきりとしたコードになっています。
この記事では上記のコードをたどりながらGPT-2のアーキテクチャを解説します。
なぜGPT-2なのか
GPT-2は文章生成のための言語モデルです。GPT-3の一世代前のバージョンになります。なお、GPT-3と言えば、派生のモデルとしてInstructGPTやChatGPTがあります。これらはすべてOpenAIによって開発されました。
なお、OpenAIはGPT-2のソースコードを公開しています。GPT-2はTensorFlowを使って実装されています。また、事前学習済みモデルのパラメータ値(重み、バイアス)がダウンロードできるようになっています。
そのため、多くの人がGPT-2を他のフレームワークを使ったりして実装しています。ここで紹介しているソースコードもそのうちの一つになります。
作者によるとGPTを紹介するための教育的な意図を持って作ったので、実行のスピードも遅く、訓練ができないなど最低限の機能に留めて分かりやすさを優先したとのことです。訓練しないのでドロップアウトなども含まれていません。よって重みなどはオリジナルのデータを使っています。
他にもよく知られたGPT-2の実装として、Andrej KarpathyのnanoGPTもあります。こちらはGPT-2をPyTorchで実装しており、PyTorchが好きな方には分かりやすいかもしれません。また、少し長め(コメントを含めて350行ほど)にはなっていますが、nanoGPTでは訓練も行えるようになっています。
ちなみに、Andrej KarpathyはもともとOpenAIの出身で、その後テスラに入社し、最近またOpenAIに戻ったという経緯があり、OpenAIとは縁が深い方です。
GPTのアーキテクチャ
さて、GPTはどのバージョンもTransformer(トランスフォーマー)のデコーダをベースにしています。デコーダは文章を生成する機能を持ち、下図の右側部分に相当します。

トランスフォーマーの詳細はこちらで解説しています。オリジナルのトランスフォーマーは翻訳モデルであり、上図の左側部分のエンコーダは入力文章から文脈を抽出する機能があります。ちなみに、GoogleのBERTはトランスフォーマーのエンコーダを基にした言語モデルです。
GPTは翻訳モデルではないのでエンコーダは必要ありません。また、エンコーダとデコーダの結合もなくなるので、下図のようにより単純になります。
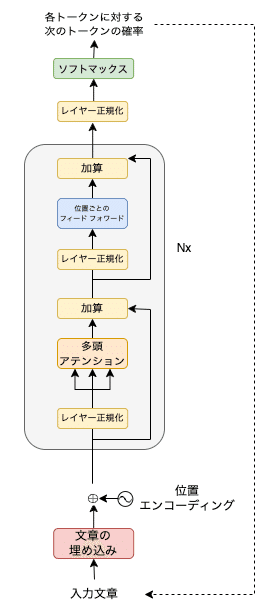
このようにGPTのデコーダは、オリジナルのトランスフォーマーの論文におけるデコーダよりも単純であり、さらにいくつか異なる部分があります。
GPT-2では、レイヤー正規化を最初に行います。これはオリジナルのトランスフォーマーの実装の頃から指摘されていたことで最初にレイヤー正規化を行った方が訓練がより安定するためです。
よって、オリジナルの英語の図ではAdd & Normと書かれていますが、上図のデコーダではNorm(レイヤー正規化)は最初に行われ、後でAdd(加算、残差接続)が行われています。
そして、最後のデコーダ・ブロックの後に再びレイヤー正規化が行われています。デコーダの詳細は後でコードを追いながら解説します。
この記事が気に入ったらサポートをしてみませんか?