
COVID19の日次新規陽性者数を居住地別にカウントするWEBアプリケーションをつくる vol.1

皆様こんばんは。早速WEBアプリケーションの開発をしていきたいと思います。WEBアプリケーションの開発環境は「Jupyter Notebook」を使っていきたいと思います。作業工程をそのまま記録していくので、少し分かりずらい部分が出てくるかもしれませんが、完成した時にまとめページでも作成したいと思います。「Jupyter Notebook」については下記のページを参考にしてください。
1 日付データの取得
まず初めに、日付データの取得から行います。必要なモジュールのインポートを行います。
import datetime次に、日付の取得を行います。日付の取得は、下記の種類を取得したいと思います。
URL用の本日の日付(4桁) 例)本日が2021年12月11日の場合・・・「1211」となる。
URL用の昨日の日付(4桁) 例)本日が2021年12月11日の場合・・・「1210」となる。
ホームページ上の更新日と比較するための日付取得 例)本日が2021年12月11日の場合・・・「2021年12月11日」となる。
「datetime」のモジュールがあるので、各々の日付を取得するのはかなり容易ですが、出力の仕方を整えてあげる必要がありますので、下記の通りにコードを書いてみました。
# 今日の日付を取得(4桁)
dt_now = datetime . date.today()
dt_now1 = dt_now.strftime("%m%d")
# 前日の日付を取得(4桁)
oneday = datetime.timedelta(days=1)
dt_yes = dt_now-oneday
dt_yes = dt_yes.strftime("%m%d")
# 今日の日付を取得
dt_now2 = datetime . date.today()
dt_now2 = dt_now2.strftime("%Y年%m月%d日")これで上手くいっているか、下のコードでテストしてみます。
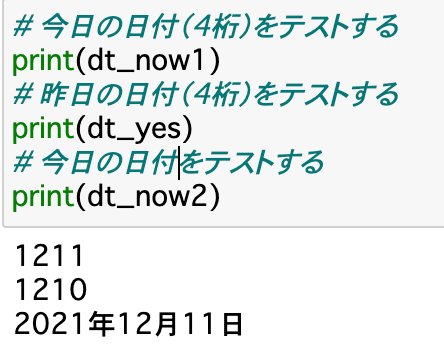
# 今日の日付(4桁)をテストする
print(dt_now1)
# 昨日の日付(4桁)をテストする
print(dt_yes)
# 今日の日付をテストする
print(dt_now2)すると、下記の通りに出力されました。この部分で、「%y」とすると西暦下2桁、「%Y」とすると西暦4桁の出力になることを偶然知ることができました(笑)
よし、上手くいった。まとめるとこんな感じ。
# 日付の取得
import datetime
# 今日の日付を取得(4桁)
dt_now = datetime . date.today()
dt_now1 = dt_now.strftime("%m%d")
# 前日の日付を取得(4桁)
oneday = datetime.timedelta(days=1)
dt_yes = dt_now-oneday
dt_yes = dt_yes.strftime("%m%d")
# 今日の日付を取得
dt_now2 = datetime . date.today()
dt_now2 = dt_now2.strftime("%Y年%m月%d日")
# 今日の日付(4桁)をテストする
print(dt_now1)
# 昨日の日付(4桁)をテストする
print(dt_yes)
# 今日の日付をテストする
print(dt_now2)2 ホームページから更新日を取得する
次に、沖縄県のホームページから更新日を取得します。

この上のデータですね。必要なモジュールをインポートします。
import requests
from bs4 import BeautifulSoupホームページを見て、更新日を取得するということを下のコードで実行します。取得した日付のデータ形式については、今後比較するために文字として取り扱いたいので、出力方法を調整します。
# 県のホームページから更新日を取得する
url = 'https://www.pref.okinawa.lg.jp/site/hoken/kansen/soumu/press/20200214_covid19_pr1.html'
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
aa = soup.select('#tmp_update')
for i in aa:
update_id = (i.string)さて、上手くいっているか下のコードでテストします。
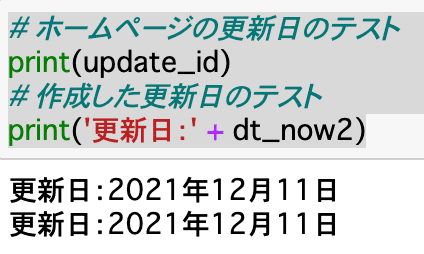
# ホームページの更新日のテスト
print(update_id)
# 作成した更新日のテスト
print('更新日:' + dt_now2)すると、下の通りの結果が出ます。
これもOK。まとめるとこんな感じ。
import requests
from bs4 import BeautifulSoup
# 県のホームページから更新日を取得する
url = 'https://www.pref.okinawa.lg.jp/site/hoken/kansen/soumu/press/20200214_covid19_pr1.html'
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
aa = soup.select('#tmp_update')
for i in aa:
update_id = (i.string)
# ホームページの更新日のテスト
print(update_id)
# 作成した更新日のテスト
print('更新日:' + dt_now2)3 CSV取得のためのURLに変数を入れる
私の中では、ハードルが高い作業になった。上で取得したものを使うのはイメージできるが、URL内にどうやって変数を入れようか、、色んなサイトを調べた結果、下のコードになった。
# 今日の日付をURLに入れる
fpath = 'https://www.pref.okinawa.lg.jp/site/hoken/kansen/soumu/press/documents/{0}youseisyaitiran.csv'.format(dt_now1)
# 県のホームページにあるcsvファイルの読み込み
df = pd.read_csv(fpath ,encoding='shift-jis')URLにそのまま変数を入れることができなかったので、.formatを使ったのが私的には大分難しかった。
あとshift-jisにdecode?しないとなぜか出力されなかったので、encoding = ‘shift-jis’としました。
ちなみに、この記事作成時点(2021年12月12日 10時時点)で上のコードを「df」で実行すると、エラーになると思います。理由は沖縄県のホームページがこの時点でまだ更新されていないから。なので、「if」を使って、「更新されている場合 else 更新されていない場合」の処理を書いてみたいと思います。
4 ホームページが更新された場合・されていない場合の処理
「1 日付データの取得」「2 ホームページから更新日を取得する」でそれぞれ取得したものを使って条件式を書いてみます。その前に必要なモジュールをインポートします。
import pandas as pdで、下のとおりコードを書きます。
# もし県のホームページが更新されたら
if update_id == '更新日:' + dt_now2:
# 今日の日付をURLに入れる
fpath = 'https://www.pref.okinawa.lg.jp/site/hoken/kansen/soumu/press/documents/{0}youseisyaitiran.csv'.format(dt_now1)
# 県のホームページにあるcsvファイルの読み込み
df = pd.read_csv(fpath ,encoding='shift-jis')これでホームページが更新された場合に、csvファイルを読み込むという形になりました。
これでテストしてみましょう。下のコードで確認することができます。
dfすると下の結果がでます。

記事的にはここまであっという間ですが、ここに来るまでに数日かかりました、、地道にやっていく必要があるのですね。
本日はここまで。上で得られたデータフレームをSQLiteのデータベースに格納することをやっていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?