
Python で映画の人気度を予測してみた。

映画のチケット料金を人気度から設定する。
人気な作品、不人気の作品で同じ値段であることを不思議に感じて、
人気度を予測することで上映時にそれにあった値段を設定できるようにしたいと思いました。
実行環境
Google Colaboratory
Python 3.9.16
データの収集
KaggleのDatasetからTMDBという映画まとめサイトの情報が抜き取られたデータを使用しました。
CSVfileから下記のColumnsだけを抽出しました。
id : TMDBでの映画番号
popularity:人気度
budget:映画作成予算
revenue:興行収入
original_title:映画タイトル
homepage:HomepageのURL
overview:あらすじ
runtime:上映時間
release_date:上映開始日付
release_year:上映開始年
vote_count:評価の数
vote_average:評価の平均(0~10点)
分析の進め方
今回、分析方法は重回帰分析を用いていきたいです。
"popularity"(人気度)を目的変数とするので、説明変数を何にするのか考えていきます。
また、リッジなどの複数のモデルに通して、精度の比較を試したいです。
仮説
Overviewにポジティブな言葉が多ければ、人気の作品になりやすいのではないか。
Overviewを感情分析して、Compound(ネガポジの合計評価)とPopularityの相関を求めて、重回帰分析に組み込んでいきたいです。
分析
データの前処理
KaggleからダウンロードしたファイルがCSVなので、Excelで出来る範囲は
直接変更していきます。
まず、homepage列はURLがWebsiteを作成しているかいないかで判断させる為に0 or 1に置換します。


プログラミング内容
モジュールのImport
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from sklearn.svm import SVR
import lightgbm as lgbデータの読み込み、詳細確認:
budget(予算), revenue(興行収入)列に0の値が多くあり、データが反映できていないと見れます。
これらを欠損値として、今回は数がとても多いのですべて削除して対応します。

df = pd.read_csv('/content/main_df.csv', encoding="UTF-8")
df = df[df['budget'] != 0]
df = df[df['revenue'] != 0]
df = df.reset_index(drop=True)
print(df.describe())
overviewの感情分析
ここでは英語で書かれたoverviewを解析するので、Aidemyで学んだ形態素解析は使わず、nltkのSentimentIntensityAnalyzerでセンチメント分析で数値化してみます。
Compoundの数値を"senti_com"列に入力していきます。
sia = SentimentIntensityAnalyzer()
df["senti_com"] = 0
row = df.shape[0]
for i in range(row):
df["senti_com"][i] = sia.polarity_scores(df["overview"][i])["compound"]用意できたデータをヒートマップで相関を可視化してみます。
corr = df.corr()
sns.heatmap(corr, cmap='coolwarm', vmin=-1, vmax=1, annot=True)
plt.show()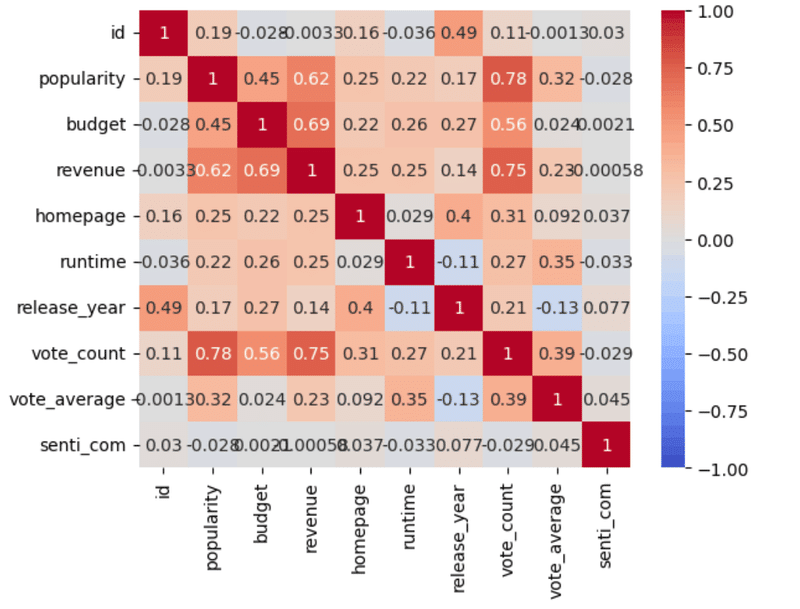
Heatmapの出力結果からわかる事
①senti_comともにpopularityとの相関がほぼ0に近いので、相関が全くない。
senti_comについて相関は0だが、回帰分析の精度に影響があるか確認してみます。
②popularityに相関があるのは上から順にvote_count, revenue, budget
以上3つから、見ている人数が多いことや、興行収入の結果、映画にかける予算を多いほど人気が高くなりやすいということが分かります。
senti_com以外すべてに少し正の相関があるので、今回はすべてを重回帰分析に組み込んでいこうと思います。
Scalerを使ってデータを正規化
budgetやrevenueの数値が大きく、比較しにくいので正規化します。
df = df[['id', 'popularity', 'budget', 'revenue', 'homepage', 'runtime',
'release_year', 'vote_count', 'vote_average']]
scaler = MinMaxScaler()
normalized_df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(normalized_df.head())
LinearRegression()で重回帰分析
shuffled_df = normalized_df.sample(frac=1, random_state=42)
X = shuffled_df[['id', 'budget', 'revenue', 'homepage', 'runtime',
'release_year', 'vote_count', 'vote_average']] # independent variables
y = shuffled_df['popularity'] # dependent variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, train_size=0.8, random_state=42)
# Create linear regression model
model = LinearRegression()
# Fit the model to the data
model.fit(X_train, y_train)
# Predict target values for new data
y_pred = model.predict(X_test)
print(r2_score(y_test, y_pred))重回帰分析の評価指数:決定係数(R2)の結果
0.6902319677977702
結果:精度が0.69となり、
重回帰分析では0.6~0.9の間であれば十分に精度があると判断できるので、これらの要素で人気度を予測できると言えるでしょう。
リッジ、ElasticNet、サポートベクター、LightGBMモデルにも通してみます。
#リッジ回帰
model_1 = Ridge()
model_1.fit(X_train, y_train)
print("リッジ回帰:{}".format(model_1.score(X_test, y_test)))
#ElasticNet
model_2 = ElasticNet(l1_ratio=0.5)
model_2.fit(X_train, y_train)
print("ElasticNet:{}".format(model_2.score(X_test, y_test)))
#サポートベクトル回帰
model_3 = SVR(kernel='linear', C=1, epsilon=0.1, gamma='auto')
model_3.fit(X_train, y_train)
print("サポートベクトル回帰:{}".format(model_3.score(X_test, y_test)))
#lightGBM
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgbm_params = {
'objective': 'regression',
'metric': 'rmse',
'num_leaves':60
}
model_4 = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, verbose_eval=-1)
y_pred = model_4.predict(X_test, num_iteration=model_4.best_iteration)
print("lightGBM:{}".format(r2_score(y_test, y_pred)))
lgb.plot_importance(model_4, figsize=(10, 5))
plt.show()リッジ回帰:0.6954655823948026
ElasticNet:-0.0024356030530610084
サポートベクトル回帰:0.38978036674244565
lightGBM:0.7663444128225729
もともとあるデータだけでの分析が出来たので、senti_comを加えて同様に行った分析の結果を記載します。
決定係数(R2):0.6905613270552293 ⇗
リッジ回帰:0.6959437002151398 ⇗
ElasticNet:-0.0024356030530610084 ⇒
サポートベクトル回帰:0.39397428926463596 ⇗
lightGBM:0.7619890333228423 ⇘
senti_comを加えた結果
lightGBMの結果のみ精度が落ちました。
モデルによって受ける影響が違い、精度に差が出る事を学べました。
結論:
今回用意した要素からpopularityを予測することは十分にでき、
映画料金の設定に利用することができる。
あらすじのネガティブ、ポジティブの言葉の多さは人気度に関係が無いと言える。
分析のきっかけ
今回の分析はコロナで大きな影響を受けた映画館で
より多くの人に鑑賞しに来てほしいという気持ちで始めました。
人気の高い映画なら一般的な値段でも鑑賞する人は多いが、
面白いかどうか分からない映画をそれと同じ値段で、平均109分の時間をかけて観るというのは、私は遊びの選択肢に入りにくいと感じています。なので、安くすることで若者を中心に客足を増やすことができるのではないかと思いました。
調べてみると、映画の値段については何度も調整が考えられているが、収入面で却下されているようです。
しかし、私は業界を楽しむ人を増やす為に調整を行ってほしいと考えます。
この記事が気に入ったらサポートをしてみませんか?