大規模言語モデル(GPT-2)のパラメータ・モデルサイズ・VRAMの実測メモ

はじめに
大規模言語モデルをフルスクラッチで作る検討を始めました。
モデルサイズや必要VRAMについては理論的に計算できたりするようですが、理論式がよくわからない上、実際にやってみて体感した方がしっくりくるので、試してみました。
24/1/2 15時追記
モデルサイズを概算する機能を教えていただいたので、追記しました。
huggingfaceのmemory calculatorの値が理論値?だと認識しているんですが、実際はもっといろいろ複雑だったりするのかな。
— Yuu Jinnai (@DINDIN92) January 2, 2024
app: https://t.co/zIDdHYiLPW
code: https://t.co/zYHsTGcnsz https://t.co/mToYqu3s5n
基本条件
こちらのGPT-2を使います。
主なモデルパラメータは以下の通り。このときのモデルサイズは355Mでした。
{
"architectures": [
"MistralForCausalLM"
],
"bos_token_id": 0,
"eos_token_id": 0,
"hidden_act": "silu",
"hidden_size": 1024,
"initializer_range": 0.02,
"intermediate_size": 2400,
"max_position_embeddings": 4096,
"model_type": "mistral",
"num_attention_heads": 16,
"num_hidden_layers": 24,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-05,
"rope_theta": 10000.0,
"sliding_window": 1024,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.35.2",
"use_cache": false,
"vocab_size": 50257
}
テキストをトークン長1024で区切り、device_train_batch_size=4、オプティマイザはadamw_bnb_8bit、モデルはfp16で事前学習を回すと、約15GBのVRAMを消費しました。
パラメータとモデルサイズの依存性
上記のパラメータの中で、最もサイズに効くのはhidden_size、num_hidden_layersでした。理論的に考えると、当たり前のようです。
hidden_size
MLPの隠れ層のサイズ(hidden_size)はモデルサイズに対して二次で増えました。


num_hidden_layers
隠れ層の数(num_hidden_layers)はモデルサイズに対して線形でした。
これも当たり前といえば当たり前ですね。


モデルサイズとVRAMの関係性
モデルサイズに比べると、結局どの程度のVRAMが必要になる※のかが、自分的にはあまり明瞭ではありませんでした。
(※主にモデルそのものの重み+backpropagation+推論 でVRAMが必要になります)
同じようにパラメータを変えて必要VRAMを実測してみました※。
※便宜上、事前学習データセットのごく一部(10万文字)しか学習に使っていません。そのためか、必要値を過小評価している印象です。標準条件で普通に事前学習を回すと15GB程度のVRAMを使ったことを鑑みると、表の値を約1.5倍くらいした値が正確だと思います。

モデルサイズは、16bitを想定して、パラメータ数(B) x2 としました。
表をplotしたグラフは以下の通り。

バッチサイズと必要VRAM
24/1/4: モデルサイズを変えた結果を追記
最後に、条件を標準に戻し、hidden_sizeとper_device_train_batch_sizeを変化させながら必要VRAMを調べました。
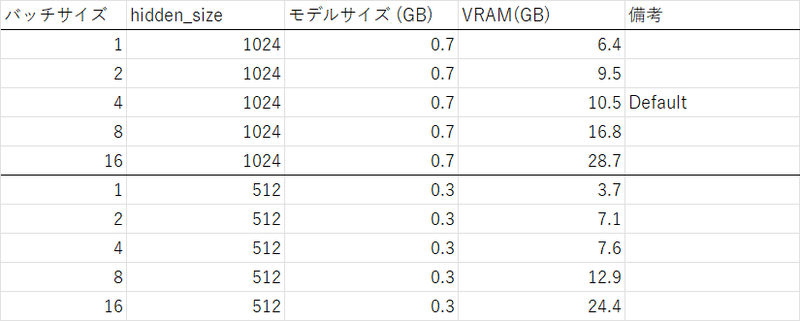

必要VRAM ≒ 1.3 x バッチサイズ + 切片 となりました。
比例係数は1でも良い気がしたんですが、諸々の余剰が必要なようです。
切片はモデルサイズの7-10倍程度となりました。
1/6追記
0.36Bモデルで本格的に学習を回す際、batch_size=25にしたときのVRAMは60GBでした。
まとめ
以上、適当にパラメータを変えながらモデルサイズや必要VRAMをとりあえず調べてみました。
必要メモリはモデルサイズの4倍くらいが目安(たとえばこちらやこちら)みたいな話はよく聞くんですが、実際は10倍くらいは必要かも、という感じでした。
オプティマイザや推論でVRAMを使っているのはわかるんですが、内訳がよくわかりません。理論式がわかる方、教えてください。
この記事が気に入ったらサポートをしてみませんか?