CommonCrawlの生データをダウンロードして解析する練習

はじめに
大規模言語の事前学習には、Webデータを片っ端からダウンロードしたサイト(CommonCrawl, CC)が大活躍します。
普通はCCを使いやすい形で加工したコーパスを用いるのですが、今回は生データにアクセスして解析してみました。
ファイルをダウンロードする
兎にも角にも、ファイルをダウンロードすることから作業が始まります。
URLリストを取得する
まずは上記CCのサイトにアクセスし、どの年のデータをダウンロードしたいか選択します。
次に、warc.path.gzをダウンロードします。
こちらには各データへのURL一覧が格納されています。
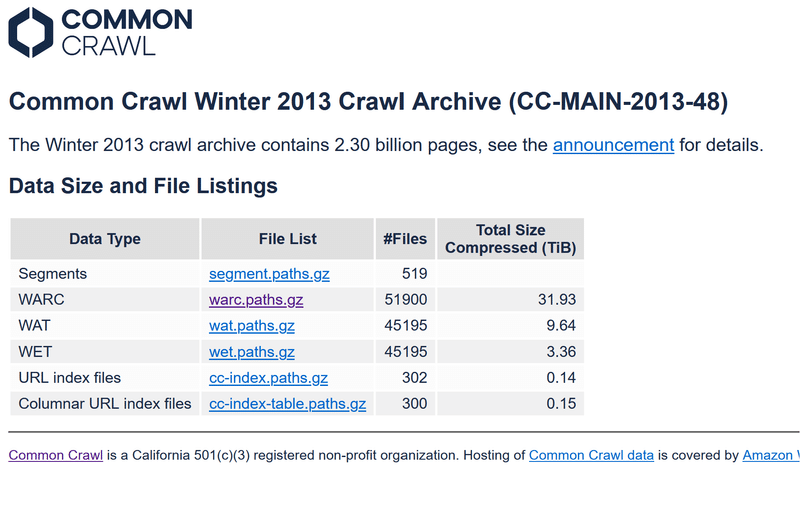
備考: WARC,WAT,WETとは?
「warc」、「wat」、「wet」という用語は、Common Crawlのコンテキストで使用されるファイル形式を指します。Common Crawlは、インターネットの広範囲にわたるウェブページをクロールし、そのデータを公開する非営利プロジェクトです。これらのファイル形式は、ウェブクロールのデータを保存するために使用されますが、それぞれ異なる目的とデータの種類を持っています。
WARC (Web ARChive)
目的と内容: WARCファイルは、ウェブクロールの完全なデータを含むファイル形式です。これには、HTTPヘッダー、HTMLコンテンツ、およびウェブページから取得されたその他のリソースが含まれます。
使用例: ウェブサイトのアーカイブ、ウェブリサーチの研究、機械学習モデルのトレーニングデータなど。
WAT (Web ARChive Time-stamp)
目的と内容: WATファイルは、メタデータとアノテーションの集合を提供します。これには、リンクデータ、サーバー応答ヘッダー、ページの構造に関するメタデータなどが含まれます。
使用例: ウェブの構造分析、リンクグラフの生成、ウェブページのメタデータ分析など。
WET (Web ARChive Extracted Text)
目的と内容: WETファイルは、ウェブページから抽出されたテキストのみを含みます。HTMLタグやその他のマークアップは除去され、プレーンテキストの内容のみが残ります。
使用例: テキスト分析、自然言語処理(NLP)プロジェクト、コンテンツベースの検索や分析など。
各ファイル形式は、ウェブクロールデータを異なる角度から分析するためのツールとして役立ちます。WATとWETは、WARCから派生したデータであり、特定の目的に合わせて加工・抽出された形式です。Common Crawlプロジェクトは、これらのフォーマットを通じて、インターネットの広大なデータを研究者や開発者が利用しやすい形で提供しています。
warcファイルのダウンロード
今回はフルの情報を得たいので、warc.path.gzをダウンロードします。warc.paths.gzを解凍して開くと、パスの一覧が表示されます。
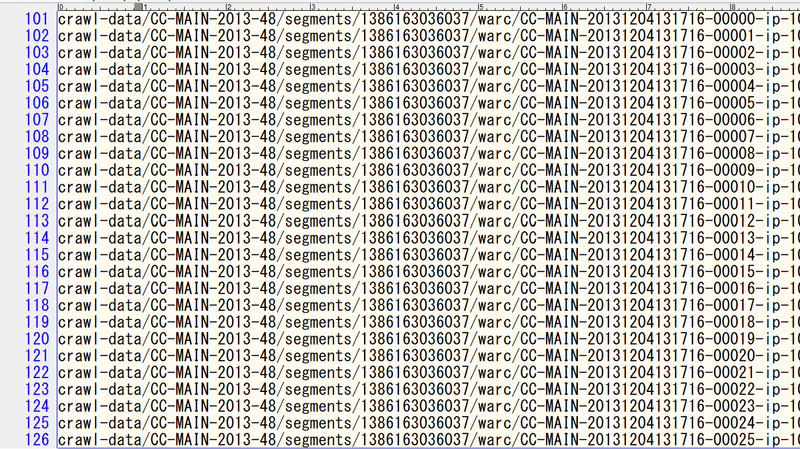
ここから適当な行を選んで、
https://data.commoncrawl.org/[...]
内の[…]に行の値を貼り付けると、ダウンロードリンクになります。
今回は、
https://data.commoncrawl.org/crawl-data/CC-MAIN-2013-48/segments/1386163036037/warc/CC-MAIN-20131204131716-00025-ip-10-33-133-15.ec2.internal.warc.gz
をダウンロードしました。解凍前は約800MB, 後は3.8GB程度です。
Pythonで解析する
warcファイルをpythonで解析してみます。やり方はGPT-4に聞きました。
セットアップ
まずは、pipで解析ライブラリを入れます。
pip install warcio日本語のページを取得
属性がjaのページをリストで取得していきます。beautifulsoupを使います。
今回は練習なので、7件の取得でloopを止めます。webサイトの大半は日本語ではないので、このsearch作業だけでも、わりと時間がかかりました(note pcで数分)。
#ライブラリの読み込み
from warcio.archiveiterator import ArchiveIterator
from bs4 import BeautifulSoup
from tqdm import tqdm
#ファイルパス
path="data\CC-MAIN-20131204131716-00025-ip-10-33-133-15.ec2.internal.warc"
#データの格納リスト
ja_soup_list=[]
#途中から再開する用の位置情報の取得
if len(ja_soup_list)>0:
fin_record_id=ja_soup_list[-1]["record_id"]
else:
fin_record_id=0
# メインループ
record_id = 0
with open(path, 'rb') as stream:
for record in tqdm(ArchiveIterator(stream)):
record_id += 1
if record_id<=fin_record_id:
continue
if record.rec_type == 'response':
if record.http_headers.get_header('Content-Type') == 'text/html':
content = record.content_stream().read()
soup = BeautifulSoup(content, 'html.parser')
# <html>タグからlang属性を取得
html_tag = soup.find('html')
if html_tag and html_tag.has_attr('lang'):
lang = html_tag['lang']
#print(f"Found language: {lang}")
if lang=="ja":
d={
"record_id":record_id,
"url":record.rec_headers.get_header('WARC-Target-URI'),
"title":soup.title.string,
"soup":soup,
}
ja_soup_list.append(d)
print(f"Found Japanese: {d['url']}")
#今回は練習なので、途中でstop
if len(ja_soup_list)>6:
break取得したhtmlからのテキスト抽出
たまたま、厚労省のページが含まれていたので、そちらを可視化してみます。
soup=ja_soup_list[-2]["soup"]
#テキストの最小長さ
len_threshold=10
texts = [] # テキストを保存するためのリスト
#半角文字だけのテキストを検出
def is_all_halfwidth(s):
for char in s:
# Unicodeでの半角文字の範囲チェック
if not ('\u0020' <= char <= '\u007E' or # 基本的なASCII範囲
'\uFF61' <= char <= '\uFF9F' or # 半角カタカナ
char in ('\u0009', '\u000A', '\u000D')): # タブ、改行、復帰
return False
return True
for tag in soup.find_all(True):
#if tag.name not in ['html', 'body', 'ul']: # 特定のタグを除外する場合
text = tag.get_text(separator="\n", strip=True)
spl_text=text.split("\n")
spl_text=[i.strip() for i in spl_text]
texts.extend(spl_text)
texts=list(set(texts))
cleaned_texts=[]
for t in texts:
if len(t)<len_threshold:
continue
if is_all_halfwidth(t):
continue
cleaned_texts.append(t)
for t in cleaned_texts:
print(t)最終的に得られたテキストは以下の通り。

まとめ・所感
ノイズについて
common crawlはゴミテキストが多いとは聞きましたが、たしかにその通りだと実感しました。
例えば上記サイトから抽出した4つのテキストのうち、3つは断片的な文字の集まりで、文章として成立していませんでした。
3つ目は唯一、日本語の文章として成立していました。
国・地域別に感染症の流行状況、予防方法、体調が悪くなった場合の対応などの情報を掲載しています。調べたい国・地域をクリックしてください。詳細情報がご覧いただけます。
ただ、いかにもwebサイトにありそうな文面で、一般的に期待される「日本語の文章や会話」からは、ややズレている印象です。
大規模言語モデルの学習には「上質なテキストが必要」とはよく言われますが、まさにそのとおりだと、本解析を通して実感しました。
日本語の少なさについて
上記のスクリプトをwarcファイル全体(3.8GB)に実行するのに、約10minを要しました。その結果、得られた日本語のページはたったの9件でした。日本語が少ない「ハズレファイル」だった可能性はありますが、それにしても少ないなあ、と思いました。
この記事が気に入ったらサポートをしてみませんか?