Llama2-70b-chatで専門テキスト(学会の予稿集)をファインチューニング(QLoRA)

概要
23年8月時点におけるオープンソース大規模言語モデルの筆頭とも言えるLlama2を使い、専門テキストをファインチューニングした際のメモです。
言語モデルに知識を追加するのは、意外と難しいということがわかりました。
前提となるコード類は以下の記事などを参照
学習データ
筆者が所属している学会の一つである、高分子学会の年次大会(2023年)の予稿集を学習させてみることにしました。
(学会の参加者のみが入手可能な、クローズドなデータです)
pdfは単体で500 MBほどあります。ここから、テキストだけを抜き出しました。
処理後の平文のテキストは約150万文字(3.7 MB)でした。
参考: pdf to textのコード
本筋ではありませんが、解析コードを張っておきます。
pdfの分割
#pdfの分割
import os
from PyPDF2 import PdfReader, PdfWriter
from tqdm import tqdm
def split_pdf(input_path, output_dir, chunk_size):
# PDFを読み込む
with open(input_path, 'rb') as file:
pdf = PdfReader(file)
total_pages = len(pdf.pages)
# ページを分割して新しいPDFファイルに保存する
for i in tqdm(range(0, total_pages, chunk_size)):
chunk_output = os.path.join(output_dir, f'output_{i+1}-{i+chunk_size}.pdf')
with open(chunk_output, 'wb') as chunk_file:
writer = PdfWriter()
for j in range(i, min(i+chunk_size, total_pages)):
writer.add_page(pdf.pages[j])
writer.write(chunk_file)
print(f'Saved {chunk_output}')
# 分割するPDFファイルのパス
input_pdf_path = "data/N72.pdf"
# 分割されたPDFファイルを保存するディレクトリ
output_directory = 'data/split_pdf'
# ページごとの分割サイズ
chunk_size = 10
# 出力ディレクトリが存在しない場合は作成する
if not os.path.exists(output_directory):
os.makedirs(output_directory)
# PDFを分割する
split_pdf(input_pdf_path, output_directory, chunk_size)pdf to text
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from pdfminer.pdfpage import PDFPage
import glob
import re
def pdf_to_text2(pdf_path):
output_string = StringIO()
with open(pdf_path, 'rb') as file:
resource_manager = PDFResourceManager()
converter = TextConverter(resource_manager, output_string, laparams=LAParams())
interpreter = PDFPageInterpreter(resource_manager, converter)
for page in (PDFPage.get_pages(file, check_extractable=True)):
interpreter.process_page(page)
converter.close()
text = output_string.getvalue()
output_string.close()
return text
pdf_dir="data/split_pdf/*.pdf"
pdf_files=glob.glob(pdf_dir)
def extract_number(filename):
filename = os.path.basename(filename)
match = re.search(r'\d+', filename)
return int(match.group()) if match else -1
pdf_files.sort(key=extract_number)
text=""
for idx in tqdm(range(len(pdf_files))):
path=pdf_files[idx]
t=pdf_to_text2(path)
text+=t
#クリーニング
from tqdm import tqdm
import re
def has_alnum_or_symbol_start(string, n=5):
start = string[:n]
return bool(re.match(r'^[a-zA-Z0-9\W]+$', start))
#ページ区切りのコード
page_split_tag="\x0c"
all_text=""
abst_list=text.split(page_split_tag)
for idx in tqdm(range(len(abst_list))):
abst=abst_list[idx]
lines=abst.split("\n")
lines=[line for line in lines if not has_alnum_or_symbol_start(line)]
lines=[line for line in lines if not line.startswith(" ")]
lines=[line for line in lines if line!=""]
cleaned_text="".join(lines)
all_text+=cleaned_text.strip()+"\n"
all_text=all_text.replace("\n\n","\n").strip()
#1行の文字数が30文字以下のものを削除
all_text="\n".join([line for line in all_text.split("\n") if len(line)>30])
#テキストを保存
with open(input_pdf_path.replace(".pdf",".txt"), "w") as f:
f.write(all_text)学習用データへの変換
生成したテキストから、大規模言語モデルの学習用のjsonデータを作ります。
様々なテンプレートが存在しますが、今回は、input=""(無し), output="テキスト"としました。
トークン長&GPUメモリの関係で、1文は700字ほどに分割しました。

ここでのポイントは、これからQLoRAするモデル(Llama2-70b-chat)が既に、
instruction (Q&A)形式のデータでファインチューニング済みであることです。
つまり、以下の流れになっています。
平文テキストの学習 (事前学習 by Meta)→ Q&Aテキストの学習(ファインチューニング by Meta) → 平文テキストの学習 (QLoRA by 筆者)
本来であれば、今回のデータもQ&A形式に変換した方が、instruction形式に悪影響を及ぼさず、良いのですが、非常に手間がかかるので、やっていません。
モデルのQLoRA
以下のようなパラメータで学習させました。
model_name=meta-llama/Llama-2-7b-chat-hf
dataset_name=dataset/json/N72.json
out_dir=output/0720n72_7_test
python qlora.py \
--model_name $model_name \
--output_dir $out_dir\
--dataset $dataset_name \
--dataset_format input-output\
--max_steps 3000 \
--use_auth \
--logging_steps 10 \
--save_strategy steps \
--data_seed 42 \
--save_steps 50 \
--save_total_limit 40 \
--dataloader_num_workers 1 \
--group_by_length \
--logging_strategy steps \
--remove_unused_columns False \
--do_train \
--lora_r 64 \
--lora_alpha 16 \
--lora_modules all \
--double_quant \
--quant_type nf4 \
--bf16 \
--bits 4 \
--warmup_ratio 0.03 \
--lr_scheduler_type constant \
--gradient_checkpointing \
--source_max_len 16 \
--target_max_len 4096 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--learning_rate 0.0002 \
--adam_beta2 0.999 \
--max_grad_norm 0.3 \
--lora_dropout 0.1 \
--weight_decay 0.0 \
--seed 0 \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
学習コストなど
5 epochsを回すのに、100時間ほどかかりました
RTX3090x2 (140W)制限
r= 8-64 (rを変えても学習時間の影響はほぼ無し)
Adapter modelのサイズは、rに概ね比例しました
r= 8: 0.2 GB
r=32: 0.8 GB
r=64: 1.5 GB
学習させたテキストは4 MB程度なので、十分に大きなモデルサイズといえます。
rを変えた際の学習Lossは以下の通り。
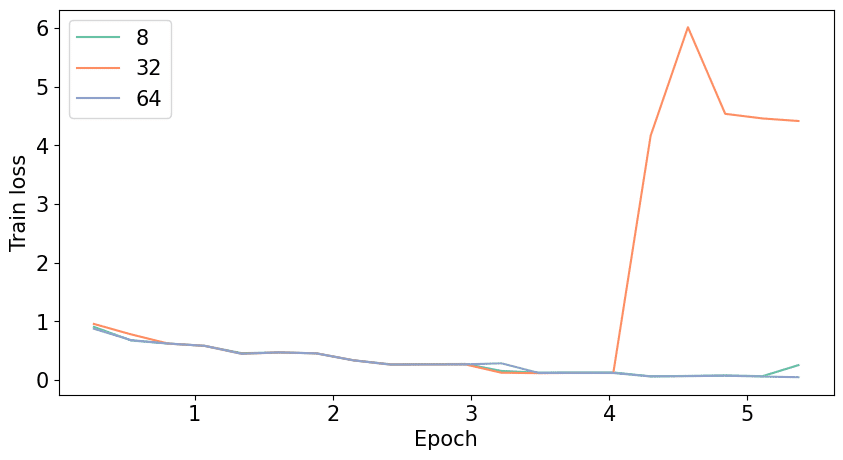
r=32で、4 epoch過ぎから、lossが爆発してしまいました。
原因はわかりませんが、モデルサイズを小さくするための4 bit量子化が影響している可能性がありそうです。
QLoRAモデルの評価
Llamma2のinstruction templateとされるものを使い、Q&Aを行います。
推論速度は、4文字/sec程度でした。
def generate_prompt(prompt):
text=f"""
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{prompt} [/INST]
"""
return textタスク1: 筆者の所属はどこか?
予稿集には、筆者の文章が含まれています。
インフォマティクスを活用した機能性高分子の設計と電荷貯蔵デバイスでの実証 東京工業大学 物質理工学院 ○畠山 歓 <<研究の背景>> 情報科学の躍進 データ駆動型科学は実験・観測科学、理論科学、計算科学に…
この文章を学んだ賢い言語モデルであれば、筆者の所属を推定できるはずです。
評価結果は以下の通り。
問い: 畠山 歓の所属は?

残念ながら、突っ込みどころ満載の回答となりました。
QLoRA前
当然の如く、知らない情報なので、わからないとの回答が返ってきます
QLoRA後
壮大なハルシネーションとなりました。
プロ野球選手、Youtuber, AKB, アニメ, 慶応義塾(総合政策学部), …
面白い点は…
chat形式モデルに対し、Q&Aではなく平文で学習させたが、(少なくとも今回の条件では)回答形式は維持されている
「わからない」という回答ではなく、ハルシネーションで回答するようになる
知識を獲得できていない
コントロール実験
そもそも、タスクが難しすぎた可能性があるので、GPTのプロンプトチューニングで回答させてみました。

回答結果は以下の通り。

GPT-3.5/4の両方で、きちんと回答できています。
Llama2はGPT-3並の推論能力とされています。
なので、今回のタスクで回答ができなかったのは、Llama2の推論能力の不足というよりは、うまく知識を獲得・活用できなかったと解釈した方が良いかもしれません。
タスク2: PLLAは海洋で生分解が始まるか?
こちらは専門的なタスクで、PLLA(ポリ-L-乳酸)というプラスチックの生分解性に関する問いです。
このプラスチックは3Dプリンタのフィラメントとして使われたり、土壌中での生分解性が謳われています。
ただし、生分解には60℃程度の熱が必要で、低温・紫外線が届かない海底においては、生分解性に乏しいことが分かっています。
予稿集にも、こうした専門情報が記載されています。
もう一つは、PLLA や PBS のように海洋では分解が始まらない生分解性プラスチックに、海洋に流出しても…
では、質問してみます。
問い: PLLAは海洋で生分解が始まるか?

まぐれの可能性があるものの、r=4, epoch=4の条件で、生分解性はないという回答が、英語で返ってきました。
フルの回答は以下の通り。
は sea begin to decompose in the ocean? Unfortunately, PLLA (Poly-L-lactic acid) is not biodegradable in the classical sense, meaning it does not break down into natural elements like other biodegradable materials. While it is made from renewable resources and has many beneficial properties, it does not decompose in the ocean or any other environment.Instead, PLLA can persist in the environment for a long time, potentially causing harm to wildlife or ecosystems if not disposed of properly. It is important to ensure that PLLA products are recycled or disposed of in a responsible manner to minimize their impact on the environment.If you are looking for biodegradable alternatives to PLLA, there are many options available, such as bioplastics made from renewable resources like corn starch or sugarcane. These materials are designed to break down naturally in the environment, reducing their impact on wildlife and ecosystems. However, it is important to note that even biodegradable materials can still cause harm if not disposed of properly, so it is important to recycle or dispose of them responsibly.
邦訳
残念ながら、PLLA(ポリ-L-乳酸)は古典的な意味での生分解性ではなく、他の生分解性材料のように自然の要素に分解されることはありません。 PLLAは再生可能な資源から作られ、多くの有益な特性を持っていますが、海やその他の環境では分解されません。その代わり、PLLAは環境中に長期間残留し、適切に廃棄されなければ野生生物や生態系に害を及ぼす可能性があります。 PLLAに代わる生分解性の素材をお探しなら、トウモロコシのデンプンやサトウキビなどの再生可能資源から作られたバイオプラスチックなど、多くの選択肢があります。 これらの素材は、環境中で自然に分解されるように設計されており、野生生物や生態系への影響を軽減します。 しかし、生分解性素材であっても、適切に廃棄されなければ害を及ぼす可能性があることに注意することが重要である。
果たして、この回答がQLoRAの結果、出てきたのか、いまいちわかりません。
回答が英語で、文章も一部破綻しているのも気になります。
まとめと考察
まとめ
Llama2-70b-chatに学会の予稿集を、そのまま学習させてみました
色々とパラメータを変えてみましたが、あまり知識を獲得できてる感じはしませんでした
たまに、知識の獲得を示唆する結果は得られました
考察
脳と言語モデルは、物事を学習する際の仕組みが異なります
上手く情報を学習させるためには、一つの知識を、複数の視点や文章から学習する必要があるかもしれません
例:PLLAは地中のコンポスト条件では生分解するが、海水は温度が低いため分解しにくい
PLLAは海洋中で生分解性を持たない
海洋中に放出されたポリ乳酸が海底に沈むと、紫外線による分解や生分解が起こりにくくなる
…
もしそうだとすると、データ数の限られた専門知識の習得は、難度の高いタスクになりそうです
QLoRAに由来する制約も考える必要があります
学習データの形式についても考える必要があります
Q&A形式で学習させ、類似の質問で検証させれば、精度は上がりそうです (ただし、データセットを作るコストがかかります)
展望
ファインチューニングは結構、難しいことがわかりました。
GPTのファインチューニングAPIは、相当に工夫されている気がします
お手軽に知識を追加したいなら、やはり、Retrieval Augmented Generation (RAG)を基軸にした方が良さそうです
引き続き、ファインチューニングの勉強をしていきます
この記事が気に入ったらサポートをしてみませんか?