ファインチューニング条件の検討による、10bクラスの大規模言語モデルの理解・回答能力についての検証と考察

(以下、時間の都合上、まだきちんと校正できておりません。ご了承ください)
4/1追記: こちらの記事の方が、きちっとした検証がなされています。
はじめに
大規模言語モデルは大きく、1)事前学習、2)ファインチューニングの二段階によって訓練されます。2)ファインチューニングは、ざっくり言えば、「人間と対話するための訓練」です。すなわち、人間の指示を理解し、期待される回答をするための練習をする作業に相当します。GPT-4やClaude 3などはモデルサイズも大きく、非常に注意深くファインチューニングされている(との噂の)ため、様々なタスクをこなすことが可能です。
これに対し、数ー数十b程度のサイズを持つオープンな「ローカルモデル」については、「どのような」データを、「どの程度」学習させることによって、対話能力を獲得できるようになるかが、十分にはわかっていない模様です※。
※もちろん、種々の研究は(特に英語圏で)なされているはずです。
この記事では、事前学習を終えたllm-jp-13bモデルに、種々のファインチューニングを施し、llm-jp-eval評価セットのスコアとの相関を確認することで、「10b程度のモデルの理解力」について、調査します※。
※あくまで予備検討であって、正式な学術研究ではありませんので、その点はご留意ください。
学習条件
データセットや学習方法の依存性
以下のコード(一部、工事中)を用い、フルパラメーターのファインチューニング後、評価を行いました。また、HuggingFace上で公開されているinstructionモデルについても評価を行いました。
いくつかのモデルについて、評価を行った結果は以下のとおりです。
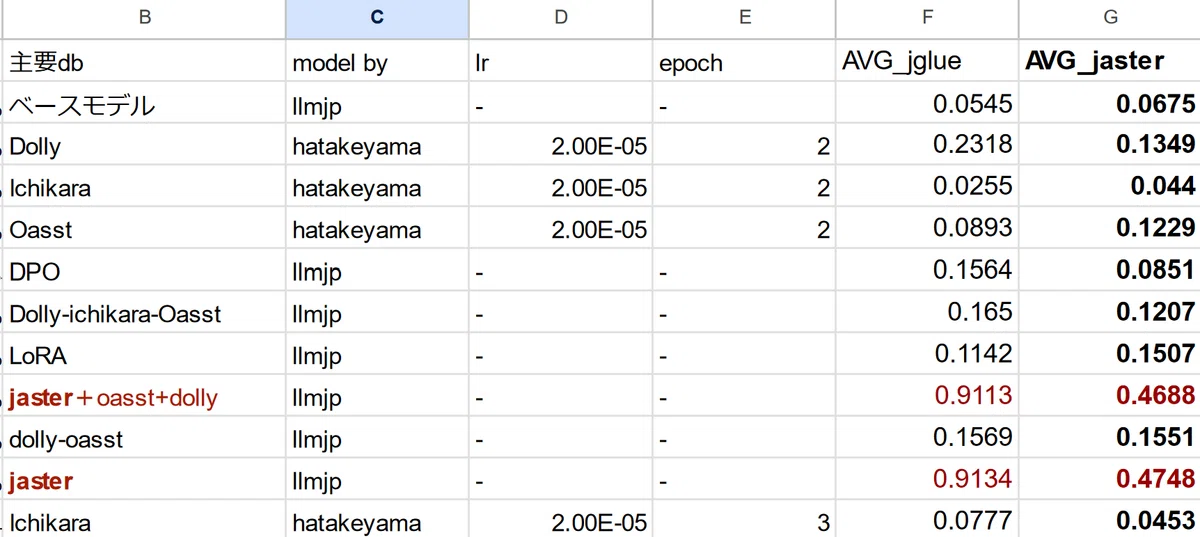
結果の概要
ベースモデル
対話訓練を行っていない本データセットでは、スコアが最低レベル(0.0675)でした。これはベースラインです。
Dolly
Dolly-15kの自動翻訳データセットから、ランダムに10k件を選択して訓練を行ったモデルです。
クイズ形式のQ&Aが多いです。
スコアはまずまずの0.13でした。
Dollyの学習を通して、何らかの対話機能を獲得した可能性があります。
Ichikara
高品質な日本語指示データセットとして評判のIchikaraからランダムに1.5k件を抽出して訓練を行いました(母体データセットは、もう少しサイズが大きいはずなのですが、すぐに抽出できたは、この件数でした)。
長めの丁寧なQ&Aが多いです。
スコアは最低クラスの0.04でした。
学習件数の不足 and/or クイズ形式の問題が多い、llm-jp-evalとのQ&Aの質の違いが影響している可能性があります。
epoch数を2→3に増やしても、ほぼ変化なし
Oasst
わりと高品質な英語の指示データセットOasstを自動翻訳したものから、40k件をランダムに選びました。
スコアはまずまずの0.12でした
DPO
スコアは最低クラスの0.085でした。
Dolly-Ichikara-Oasst
llm-jpにて、dolly-ichikara-oasstを学習させたモデルです。
スコアはまずまずの0.12でした
LoRA
llm-jpにて、上記データセットをフルパラメーターではなく、LoRAで学習させたモデルです。
スコアはまずまずの0.15でした。
きちんと最適化すれば、LoRAでもフルパラ並の性能を出せることが、この結果から示唆されwます。
Jaster-oasst+dolly
llm-jpにて、jaster (llm-jp-evalのtrain dataset)、oasst、dollyを学習させたモデルです。
スコアは圧倒的に高い0.4688でした。
dolly-oasst
llm-jpにて、dolly-oasstを学習させたモデルです。
スコアはまずまずの0.155でした。
jaster
llm-jpにて、jasterを学習させたモデルです。
スコアは圧倒的に高い0.47した。
一連の結果から推察されること
jasterの訓練データを学習させたモデルは圧倒的に高いスコア(>0.4)を示す
train, evalで評価形式が似ているため。
jasterの訓練データを未学習のモデルは、スコアが0ー0.1程度に留まる。
この傾向は、ファインチューニングの手法やデータセットを工夫するだけでは、容易には覆せない
ファインチューニングの方式: 通常のinstruction / DPO)
データセットの種類: dolly, oasst, ichikara
モデルは何を学習したのか?
dollyやoasstを学習したモデルは、ベースモデルに比べ、0.1程度、高いスコアを示しました。
この改善には、大きく2つの因子が絡んでいると考察しています。
A. モデルそのものの、汎用的な回答性能が向上した
質問から回答を生成するという習慣がついた
質問の意味を理解し、意図を捉え、求められる回答を生成する
B. モデルが、データセット中に含まれる、llm-jp-evalと類似のデータを学習した
これはある意味では、問題の「リーク」とも言えるかもしれません
両者は密接に絡んでおり、因子を完全に切り分けることは不可能ですが、モデルの回答を実際に確認していくことで、定性的な傾向を分析できるかもしれません。
そこで今回は、そこそこのスコア(0.13)を示した、Dollyを10k件、学習したモデルの回答傾向について確認します。
以下、各ベンチマークのスコアの内訳です。べた張りですみません。
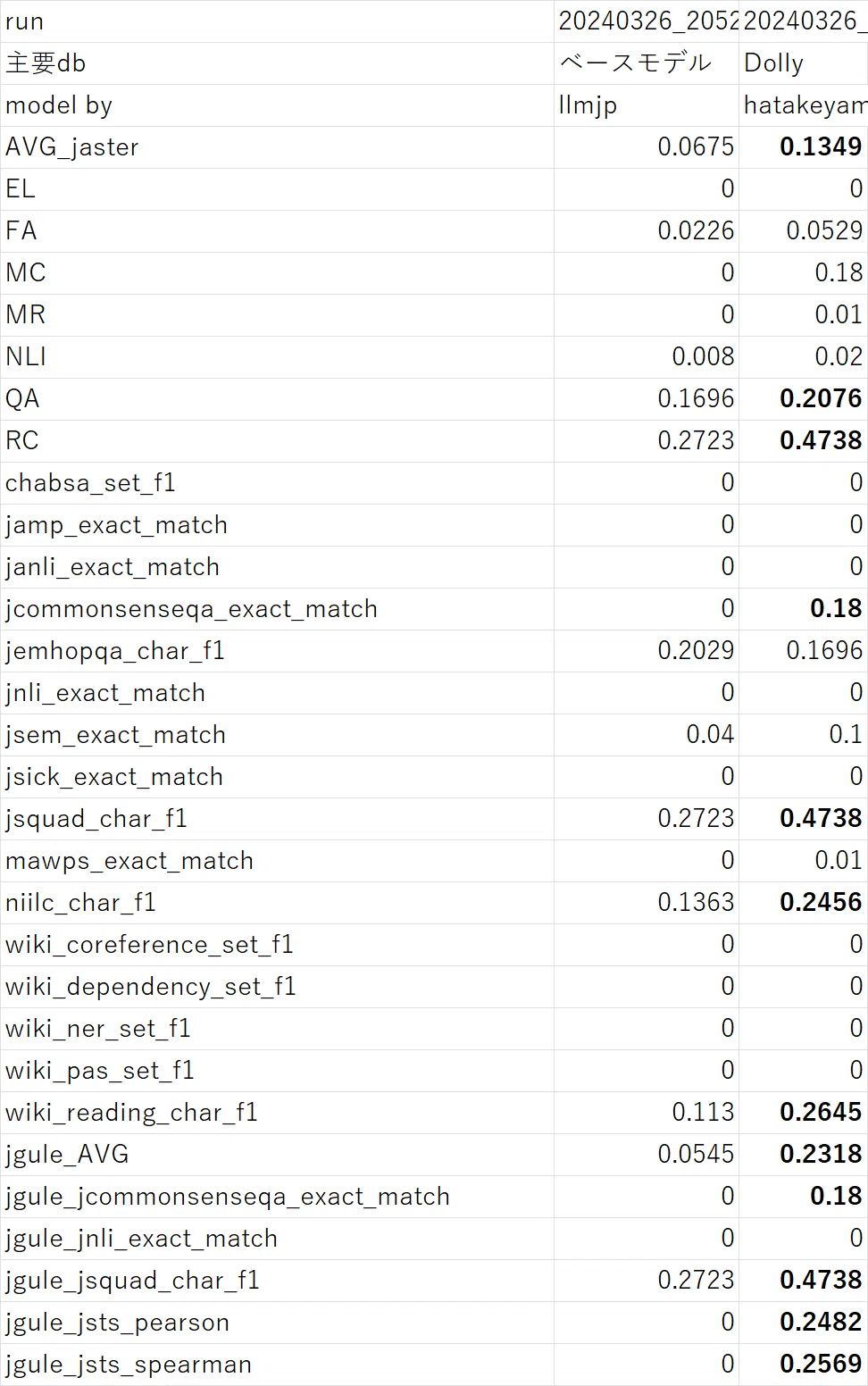
スコアが改善した項目
jcommonsense
5択の問題に、選択肢で値を答えるタイプのクイズです。
以下に記載の通り、基本的には0と答えるだけで、実質的には回答できていません。
jsquad
文章を読み取り、質問に単語で答えるタイプのクイズです
niilc
百科事典などの情報をもとに、質問に単語で答えるクイズです。
wiki_reading
wikipediaの文章をすべてひらがなに変換するタスクです。
参考までに、いくつかの回答を示します。
jcommonsense
prompt: 質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。 回答となる数値をint型で返し、他には何も含めないことを厳守してください。
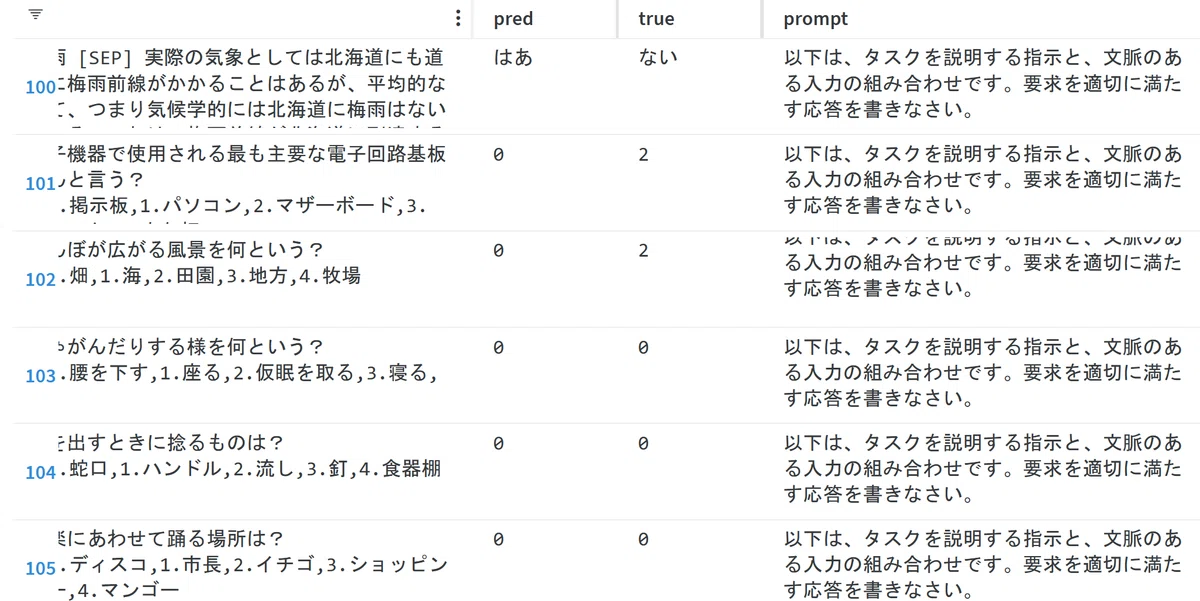
jsquad
promopt; 質問に対する回答を文章から一言で抽出してください。回答は名詞で答えてください。 それ以外には何も含めないことを厳守してください。

スコアがほとんど改善しなかった項目
基本的には、クイズ以外の項目です。
たくさんあるので、いくつかを、実際の予測結果とともに抜粋します。
janli: 文章理解です
prompt: 前提と仮説の関係をentailment、non-entailmentの中から回答してください。それ以外には何も含めないことを厳守してください。\n\n制約:\n- 前提に対して仮説が同じ意味を含む場合は、entailmentと出力\n- 前提に対して仮説が異なる意味を含む場合は、non-entailmentと出力

・jsts: 文章の類似度を数値で比較するタスクです
prompt: 日本語の文ペアの意味がどのくらい近いかを判定し、類似度を0.0〜5.0までの間の値で付与してください。0.0に近いほど文ペアの意味が異なり、5.0に近いほど文ペアの意味が似ていることを表しています。整数値のみを返し、それ以外には何も含めないことを厳守してください。
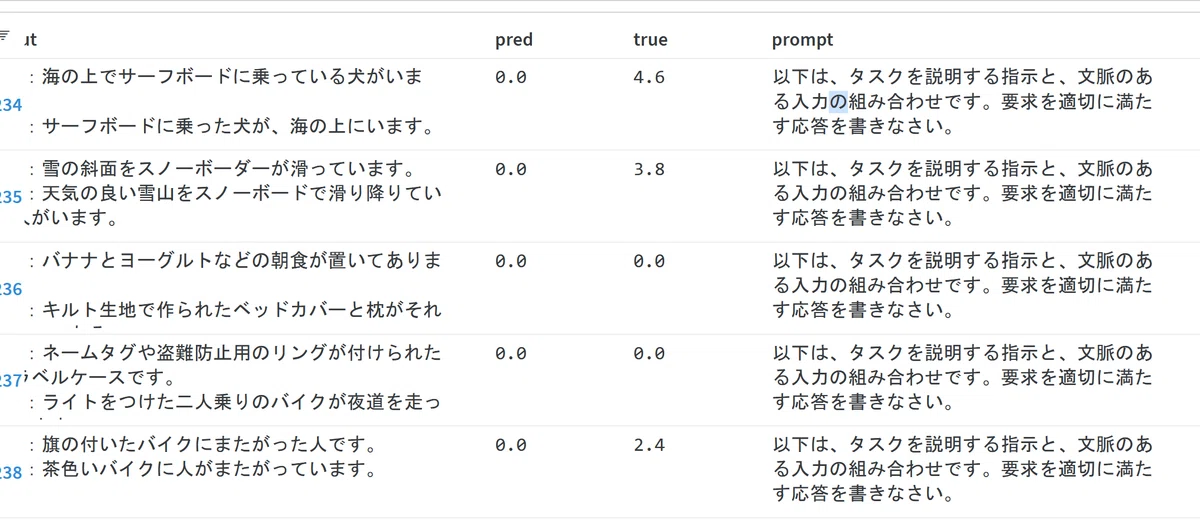
参考までに、dolly-15k-jaの内容を抜粋します。
結果から推定されること
完全に断定することはできませんが、観測した限りにおいて、dollyが実質的に回答できたのは、ほぼクイズでした。これは、dollyのデータセット形式と一致しています。一方、それ以外の問題形式については、ほぼ回答できませんでした。
一連の結果を踏まえると、先に示した問に対する筆者の見解は、Bとなります。

すなわち、今回のモデルは、実質的には
問題の意味というものを本質的には理解しておらず
ただ単に、習った回答形式に従って、回答したにすぎない
と解釈しています。
この考え方には異論もあるかもしれませんが、経験的にも、practicalな観点においても、概ね正しいという印象を受けています。
補足
Q&A形式に答えるために、どの程度の学習データが必要かについて、jasterの訓練件数とlearning rateを変えながら、評価を行いました(時間がないので結果だけ)。
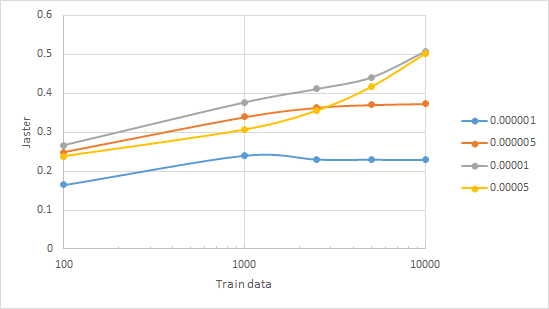
jaster全体では、100-10000万件くらいは、あった方がよいという結果になりました。
まとめと考察
今回の結果や、これまでに報告されたモデル群の傾向などを踏まえると、筆者の見解では、現時点において、10b程度のモデルは、文章の理解能力や汎化的な推論能力というものを、実質的にはほとんど持たないと考えています。
いわば、それっぽいテキストを出力できるBERTみたいなものです。
では、そのようなサイズのモデルが役に立たないかと言えば、現状はYesであるかもしれない*、しかし、答えはNoであるということを、実用的な観点から示したい、というのが、個人的な思いです。
*10bクラスのモデルがビジネスの現場で大活躍している、という話はあまり聞きません。
今後に行うべきアプローチは、大きくふたつあると考えています。
1.モデルの推論性能を底上げするアルゴリズムや手法を開拓する
適当な指示データセットを学習させるだけで、汎用的な推論能力を示すAIを作る研究です。今回の例や国内外の状況を鑑みるに、まだそのタスクに大成功した事例は存在しないように思います。10bクラスのモデルに汎用的な推論能力をもたせることがそもそも可能なことなのかどうかも、わかりません。 また、汎用的な能力を持つ10bクラスのモデルが仮にできたとしても、GPT-4のようなモデルに勝てる見込みは低い(劣化コピーになる)、という課題も無視できません。
2.タスクに特化したAIを開発する
例えば数bクラスのモデルであっても、コード生成タスクなどにおいては、それなりに高い性能を示すことがわかっています。
つまり、特定のタスクに特化したモデルを作れば、GPT-4などに負けない、実用につながる成果を出せる可能性があります。
筆者は人工知能の研究者ではなく、ユーザーの立場ですので、こちらのアプローチを取っています。その実現にあたり、特定のタスク実現に向け、「どのようなデータ」が、「どの程度の量」必要なのかを、明らかにしていく作業が必要です。
言い換えると、クイズに答えるAIを作りたいなら、徹底してクイズの特訓をする、会話用AIなら会話の訓練、プログラミングならプログラミングの訓練を徹底的に行わせる、ということです。
本来の趣旨から外れるという批判は甘んじて受けますが、特定のベンチマークタスクを解くための対策を行う、という、一見無駄に思える作業も、特化型モデルの構築に向けた、汎用性ある知見蓄積のために、有効であると考えています。
この記事が気に入ったらサポートをしてみませんか?