カスタムコードを含むTransformerモデルをHuggingFaceに登録する手順メモ

はじめに
大規模言語モデルを作っていると、モデル内部のコードをいじることがあります。
そのようなカスタムコードを含むモデルをHuggingFaceのリポジトリに登録して利用するための手順を習得するのに苦戦したので、備忘録も込めて記載します。
以下のサイトを参考にしました。
デモコード
本記事の実装コードはこちらです。
Configとモデルを登録する
今回は、Mixture of Experts (MoE)的な言語モデルを実装してみます。
以前に検討したアルゴリズムとなります。
Config
Configファイルが必要なようです。MoEConfig.pyを適当に作ります。
from transformers import PretrainedConfig
from typing import List
class MoEConfig(PretrainedConfig):
model_type = "moewrapper"
model_list = [
"kanhatakeyama/01b_model_30b_token",
"kanhatakeyama/01b_model_30b_token",
]
def __init__(
self,
**kwargs,
):
super().__init__(**kwargs)
ここで、model_list は、MoEとして読み込むHuggingFaceのレポジトリ名です。
モデル本体
PreTrainedModelクラスを継承することで作成します。
・重要なのは、super().__init__(config) で、pretrainedmodelのinitを実行することのようです。
・initより下のコードは、moe関連です。
(generateによる推論時、内部でtransformerを読み込んだを逐一呼び出し、入力に対するperplexityが最小となるモデルを選択し、出力を計算するアルゴリズムです)
・self.modelに適当なtransformerを指定しておかないと、モデルをpushするときにエラーが出ました(なので、適当なモデルを登録しています)。
from transformers import PreTrainedModel
from .MoEConfig import MoEConfig
from transformers import AutoModelForCausalLM
import torch
import numpy as np
class MoeModel(PreTrainedModel):
config_class = MoEConfig
verbose = True
fix_mode = False
def __init__(self, config):
super().__init__(config)
self.model_list = []
for model_name in self.config_class.model_list:
self.append_model(model_name)
self.set_model_id(0)
def append_model(self, model_name):
print("loading ", model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16
)
self.model_list.append(model)
def set_model_id(self, model_id):
self.model = self.model_list[model_id]
def calc_perplexity(self, tokenized_input):
ppl_list = []
for model in self.model_list:
ppl_list.append(perplexity(model, tokenized_input))
return np.array(ppl_list)
def fix_model(self, model_id):
self.set_model_id(model_id)
self.fix_mode = True
def set_flexible_mode(self):
self.fix_mode = False
def generate(self, input_ids, attention_mask,
**generate_kwargs):
if not self.fix_mode:
ppl_array = self.calc_perplexity(input_ids)
best_model_id = np.where(ppl_array == min(ppl_array))[0][0]
self.set_model_id(best_model_id)
if self.verbose:
print(f"model {best_model_id} will be used")
print("ppl array: ", ppl_array)
ret = self.model.generate(input_ids=input_ids,
attention_mask=attention_mask,
**generate_kwargs)
return ret
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def perplexity(model, tokenized_input) -> torch.Tensor:
with torch.inference_mode():
output = model(tokenized_input.to(device), labels=tokenized_input)
ppl = torch.exp(output.loss)
return ppl.item()
フォルダ構成
一覧のファイルは、MoEフォルダに入れておきます。また、モジュールとして認識させるために、空の__init__.pyを入れておきます。
呼び出しと登録
作成したconfigとmodelを呼び出して、登録するだけでOKでした。楽ちんです。
登録
#モデルロード
from MoE.MoEConfig import MoEConfig
from MoE.MoEModel import MoeModel意味があるのかよくわかりませんが、configを読み込んだりしておきます。
#コンフィグの保存
cfg=MoEConfig()
cfg.save_pretrained("custom-cfg")
#コンフィグの読み込み確認
cfg=MoEConfig.from_pretrained("custom-cfg")モデルを読み込んで動作を確認します。
#モデルの読み込み
model=MoeModel(cfg)
from transformers import pipeline
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
#動作確認
model_name=cfg.model_list[0]
max_new_tokens=10
repetition_penalty=2.0
tokenizer = AutoTokenizer.from_pretrained(model_name)
pipe=pipeline("text-generation",
#model=model.model_list[0],
model=model,
tokenizer=tokenizer,
max_new_tokens=max_new_tokens,
repetition_penalty=repetition_penalty,
pad_token_id=50256,
)
pipe("こんにちは")HuggingFaceに登録します。ログインしておきましょう。
#登録 cfg.register_for_auto_class()
model.register_for_auto_class("AutoModelForCausalLM")
#HuggingFaceに登録 (TestMoE)というファイル名にします
model.push_to_hub("TestMoE")登録が無事に完了すると、HuggingFace上でも閲覧できます。
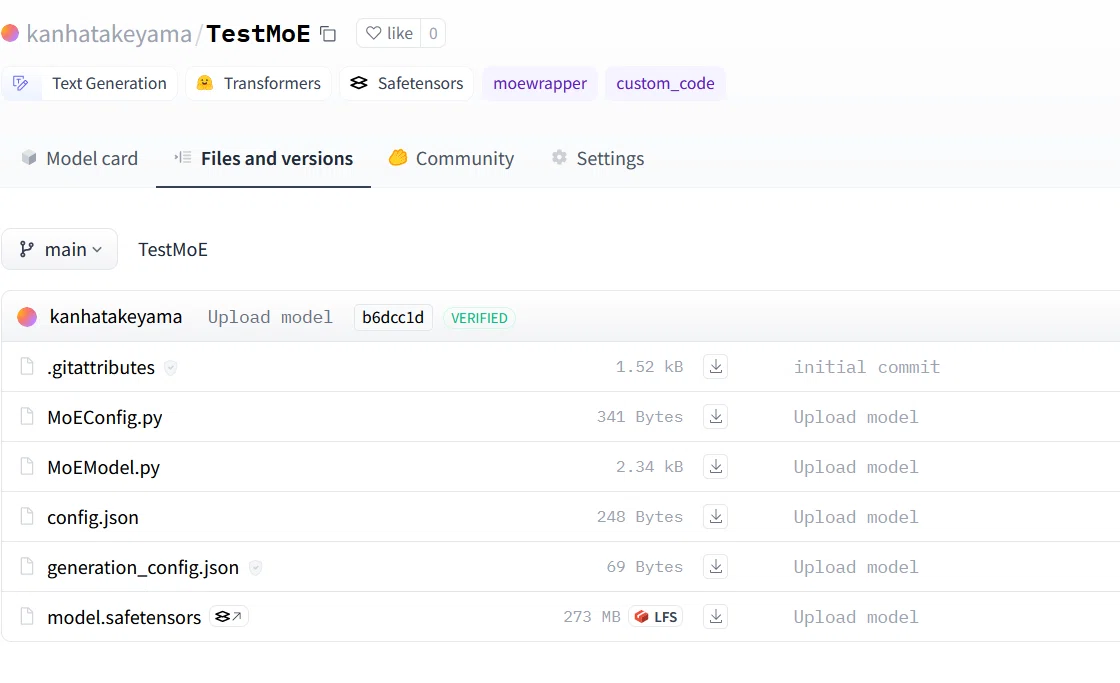
モデルの読み込み
HuggingFaceのレポジトリからダウンロードして実行します。
カスタムコードなので、trust_remote_code=Trueを忘れずに入れておきます。
#HFモデルの読み込み
hf_model=AutoModelForCausalLM.from_pretrained("kanhatakeyama/TestMoE",
trust_remote_code=True
)
#huggingfaceからダウンロードしたモデルの動作確認
pipe=pipeline("text-generation",
model=hf_model,
tokenizer=tokenizer,
max_new_tokens=max_new_tokens,
repetition_penalty=repetition_penalty,
pad_token_id=50256,
)
pipe("こんにちは")
無事に動くと、出力が出てきます。
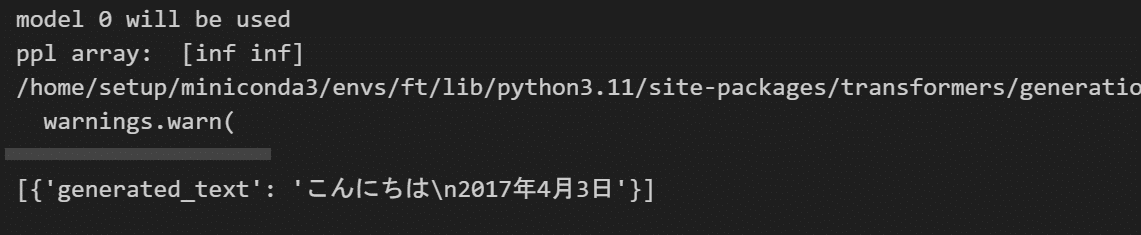
終わりに
かなり突貫というか、雑ですが、とりあえず、カスタムコードを含むモデルをHuggingFaceに登録して利用できるようになりました。
この記事が気に入ったらサポートをしてみませんか?