
ChatGPTの新機能Code interpreterを使ったデータ分析の自動化
Code interpreterの概要
こんにちは。
2023年7月7日、ChatGPT pluginでCode interpreter機能が使えるようになりました。今日はデータの抽出から集計、さらには可視化まで、すべてを自動化するテストをやってみました。どうすればそれが可能になるのか?その鍵となるのが「Code interpreter」です。
これを使えば、データ分析を素早く、効率的に、そして何よりも自動化できます。では、早速見ていきましょう。
まずは何ができるのか公式サイトで調べました。
An experimental ChatGPT model that can use Python, handle uploads and downloads
Pythonを使用し、アップロードとダウンロードを処理できる実験的なChatGPTモデルとのことです。具体的に何ができるの実際にテストしていきます。
Code interpreterの活用イメージ
Code Interpreterはデータの抽出、集計、可視化を自動化するための強力なツールです。このツールを活用することで、データ分析のプロセスを大幅に高速化し、そのコストをほぼゼロにすることが可能になります。
Code Interpreterは、PythonやSQLといったプログラミング言語を理解し、それらのコードを実行します。さらに、ユーザーが入力したコードの結果をリアルタイムで表示することが可能です。
優れているのはCode Interpreterが自動化を実現する能力です。手作業で行う必要があったデータの処理を自動的に行えるため、作業時間を大幅に短縮できます。さらに、大量のデータを高速に処理し、グラフなどの視覚化も簡単に行えます。
では、早速見ていきましょう。
ステップ1: サンプルデータの作成
まずは、営業データを例にとります。月次の売上と受注率という2つのKPIを追跡することにしましょう。企業のパフォーマンスを視覚化することで、より良いビジネス意思決定を支える洞察を得ることができます。
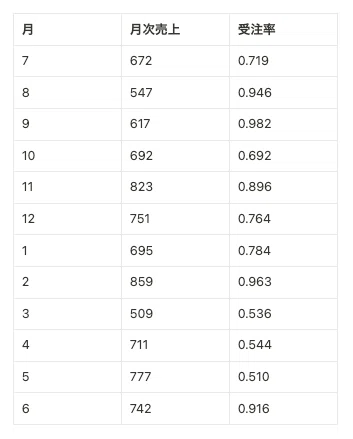
以下に、作成したサンプルデータを表示します:
import pandas as pd
from io import StringIO
# Raw data
data = """
月,月次売上,受注率
7,672,0.719
8,547,0.946
9,617,0.982
10,692,0.692
11,823,0.896
12,751,0.764
1,695,0.784
2,859,0.963
3,509,0.536
4,711,0.544
5,777,0.510
6,742,0.916
"""
# Convert to DataFrame
df = pd.read_csv(StringIO(data), sep=",")
# Save to CSV
df.to_csv("/mnt/data/Monthly_Sales_and_Order_Rate_Over_Time.csv", index=False)
df.head()これで適当に数字を作ってもらった数字がcsvとして保存ができました。
ステップ2:データの読み込み
次に、このサンプルデータをCode interpreterを使ってcsvとして読み込みます。これにより、手動でデータを操作する時間とコストを大幅に削減できます。
*Pythonの解説は省略
# Read the CSV file
data = pd.read_csv("/mnt/data/Monthly_Sales_and_Order_Rate_Over_Time.csv")
data.head()無事csvの読み込みができました。
ステップ3: データの可視化
最後に、データを可視化します。PythonのMatplotlibとSeabornライブラリを使って、データをグラフに描画します。データの可視化は、ビジネスの洞察を得るための重要なステップで、数値データだけでは把握しきれないパターンや傾向を視覚的に理解するのに役立ちます。
以下に、月次の売上(第一軸での棒グラフ)と月次の受注率(第二軸での折れ線グラフ)を描画したグラフを示します。
# visualize the data
fig, ax1 = plt.subplots(figsize=(10, 5))
# Monthly sales (bar chart on the first axis)
sns.barplot(x='month', y='monthly_sales', data=data, ax=ax1, color='skyblue')
ax1.set_ylabel('Monthly Sales', color='b')
ax1.set_xlabel('Month')
# Instantiate a second axes that shares the same x-axis
ax2 = ax1.twinx()
# Order rate (line chart on the second axis)
sns.lineplot(x='month', y='order_rate', data=data, ax=ax2, color='r', marker='o')
ax2.set_ylabel('Order Rate', color='r')
fig.tight_layout()
plt.title('Monthly Sales and Order Rate Over Time')
plt.show()
こんなグラフがすぐに作れます。
まとめ
これらのステップを組み合わせることで、完全自動化されたデータの抽出・集計・可視化を実現できます。
これにより、データの分析にかかる時間とコストを大幅に削減し、ビジネスの意思決定をより迅速かつ効果的に行うことができます。
以上が、Code Interpreterを活用した完全自動化によるデータの抽出・集計・可視化の一例です。皆さんも是非、自身の業務に活用してみてください。
この記事が気に入ったらサポートをしてみませんか?