ChatGPTでStable DiffusionをDifyで使用するための設定方法を翻訳させてみた。

わかりやすく解説してと付け加えて、ChatGPTで翻訳させた内容は以下の通り。
ステップ 1: 必要なハードウェアの確認
GPUの有無: Stable Diffusionは画像生成にGPUを推奨していますが、GPUがない場合でもCPUを使用して画像を生成できます。ただし、CPUだと処理速度が遅くなる点に注意が必要です。
ステップ 2: Stable Diffusion WebUIのセットアップ
1.WebUIリポジトリのクローン:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webuiこれにより、公式のStable Diffusion WebUIリポジトリがローカルマシンにコピーされます。
2.ローカルでの起動:
Windows
cd stable-diffusion-webui
./webui.bat --api --listenLinux
cd stable-diffusion-webui
./webui.sh --api --listenこれらのコマンドは、Stable Diffusion WebUIをAPIモードで起動し、外部からアクセス可能にします。
3.モデルの準備:
モデルのダウンロード例として、「pastel-mix」をHuggingFaceからダウンロードし、WebUIのモデルディレクトリに配置します。
git clone https://huggingface.co/JamesFlare/pastel-mix4.モデル名の取得:
ブラウザで http://your_id:port/sdapi/v1/sd-models を開き、使用するモデル名を確認します。例えば、"pastel-mix_pastelmix-better-vae-fp32" のような形式です。
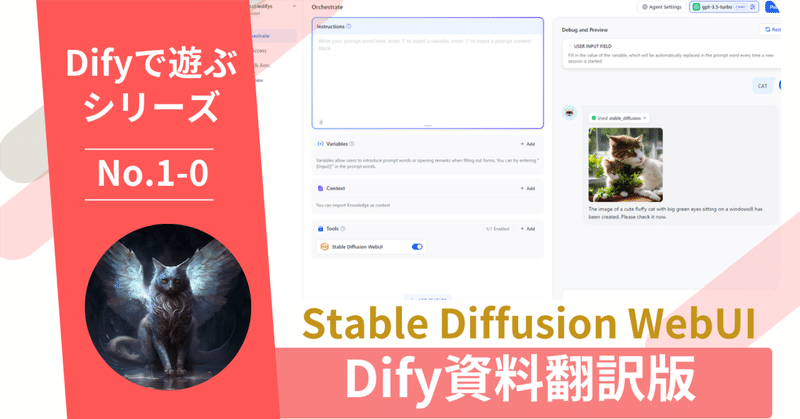
ステップ 3: DifyでのStable Diffusionの統合
Difyの設定画面に移動し、「Tools」>「StableDiffusion」>「To Authorize」に先ほど取得した認証情報とモデル設定を入力します。
ステップ 4: 使用開始
設定が完了したら、DifyでStable Diffusionを使用して画像を生成できます。
以上が、DifyでStable Diffusionを設定して使用するための手順です。これにより、テキストプロンプトから画像を生成する機能を簡単に利用できるようになります。
この記事が気に入ったらサポートをしてみませんか?