
Logstashを用いてPostgreSQLとElasticsearchをポーリングで同期した

1. はじめに
本記事では、Logstashを用いてPostgreSQLのデータをElasticsearchにポーリングで同期する仕組みの実装例を紹介します。
Logstashをどのような構成で取り入れて、どのように実装するのか、という一例をお見せできればと考えて執筆しております。(あくまで一例なため、実務で使用する際はご自身で最適な構成・実装を検討してください)
また、Logstashをメインとした記事なため、PostgreSQLやElasticsearch、kibanaの説明は省略します。
2. Logstashとは
2-1. Logstashの概要
LogstashとはElastic社が提供しているデータ取集ツールです。
公式サイト https://www.elastic.co/guide/en/logstash/current/index.html
Logstashを用いると、データの収集・変換・転送を容易に実現できます。このため、Logstashはデータ変換や解析等の用途で使用されます。
2-2. Pipeline内の処理内容
Logstashの処理内容は複数のステップに分かれており、一連のステップを連結した処理を「Pipeline」と呼んでいます。ステップは、Input(入力)・Filter(フィルター)・Output(出力)に分かれており、Input → Filter → Outputの順で処理を実行します。

また、各ステップの処理は、様々なプラグインを組み合わせて実装します。基本的には、Elastic社が提供している豊富なプラグインの中から適切なプラグインを選択しますが、独自にカスタマイズしたプラグインを作成・使用する事も可能です。
以下に各ステップの役割と処理の例を記載します。
Inputの役割
データの取得方法を指定します。
例. S3 input pluginを使用してS3からデータを抽出する。Filterの役割
データを変換します。
例. Inputで抽出したデータをCsv filter plugin等を用いてcsv形式からjson形式に変換する。Outputの役割
データの出力先を指定します。
例. Elasticsearch output pluginを用いて、Filterを経由してきたデータをElasticsearchに登録する。
3. システム構成
本記事では、PostgreSQLのデータをElasticsearchに同期するという実装を紹介します。これに伴い、データの形式をjsonに変換しなければなりません。(Elasticsearchはjson形式でデータ登録するため)
このため、今回はデータ変換の用途でLogstashを使用します。
3-1. システム構成図

3-2. 各ステップの処理内容
Inputの処理処理
PostgreSQLに対してポーリングし、データ(idなど一部カラムのみ)を取得します。Filterの処理内容
Inputで取得したデータを基にjsonを作成・整形します。(※)Outputの処理内容
Filterで生成したjsonをElasticsearchに登録します。
※ jsonを作成する処理はJava API(別途予め作成済み。解説は省略)が担当します。Logstash内でjsonを作成すると、業務ロジックをLogstashが保有する事になってしまうため、避けたいという判断です。
なので、Filterステップでは、「API呼び出し」と「APIで作成されたjsonの整形」を行います。
4. 実装例の紹介
本章では、実装例を紹介していきます。
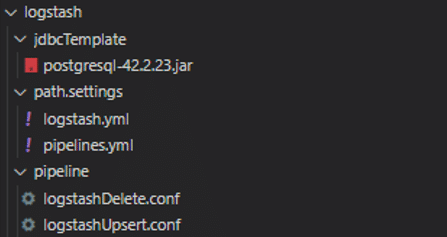
4-1. ファイル構成
ファイル構成は以下のようになっています。以降、各ファイルの実装/設定内容を解説します。
(JDBCDriverである「postgresql-42.2.23.jar」の解説は除きます)
4-2. logstash.yml
Logstash全体の設定ファイルです。複雑な設定をしていないため、設定ファイルの紹介のみとします。詳細が気になる方はhttps://www.elastic.co/guide/en/logstash/current/logstash-settings-file.htmlを参照ください。
http.host: "0.0.0.0"
config.reload.automatic: true
# 以下はElasticsearchにxpackを導入しているため必要な設定
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:<port>" ]
xpack.monitoring.elasticsearch.username: <username>
xpack.monitoring.elasticsearch.password: <password>4-3. pipelines.yml
Pipeline全体の設定ファイルです。作成したPipeline(upsert用とdelete用)のconfファイルの場所を指定します。
# upsert用のPipeline
- pipeline.id: my-pipeline_1
path.config: '<path>/pipeline/logstashUpsert.conf'
# delete用のPipeline
- pipeline.id: my-pipeline_2
path.config: '<path>/pipeline/logstashDelete.conf'他にも、並列で処理を実行するためにLogstash実行時に使用するCPU core数を指定するworkerの設定も可能です。
https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
また、別々のファイルで定義したInput・Filter・Outputの処理を連結する事が可能です。このため、Inputの処理は異なるが、FilterとOutputの処理は同一という場合、作成済みのFilter・Outputと連結する事が可能なため、Inputのみを記載したconfファイルを作成すればPipelineを完成させる事ができます。これにより、FilterとOutputの重複した実装を避けることが可能となります。
https://www.elastic.co/jp/blog/how-to-create-maintainable-and-reusable-logstash-pipelines
4-4. logstashUpsert.conf
PostgreSQLでデータをupdate・insertした際のLogstashの処理内容を記載しています。InputとFilter、Outputそれぞれ分けて説明します。
4-4-1. Inputの処理内容
PostgreSQLでupdateやinsertされたデータを取得します。処理の概要は以下です。
JDBCDriverのセット
重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
PostgreSQLにクエリを投げてデータを取得
ソースコードの全量です。以下、処理2と処理3を解説します。
input {
jdbc {
# 処理1. JDBCDriverをセット(説明省略)
jdbc_driver_library => ["<path>/postgresql-42.2.23.jar"]
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://host.docker.internal:<port>/app"
jdbc_user => <username>
jdbc_password => <password>
# 処理2. 重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
tracking_column => "updated_at"
use_column_value => true
tracking_column_type => "timestamp"
schedule => "*/10 * * * * *"
# 処理3. PostgreSQLに対するクエリを作成
statement => "
SELECT id, updated_at, row_number() over(ORDER BY updated_at) as rownum
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > :sql_last_value
AND delete_flag = false
ORDER BY updated_at
"
# 他にもデータ取得の量を制限するpagesizeの設定やログレベルの設定などがあります。
# 要件に合わせて様々なパラメーターを使用してみてください。
}
}処理2. 重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
処理2-1. 重複したデータを取得しないための設定(差分連携)
ポーリング実行時、前回ポーリングで取得したデータを重複して取得するのではなく、差分連携可能なように「tracking_column」を設定します。「tracking_column」とはポーリング実行する度に特定のカラムの値をtracking(追跡)する仕組みです。
今回は「updated_at」カラムをtracking_columnとして指定します。ポーリング実行の度に取得したデータの中で最も遅いupdate時刻をLogstash内に保存し、次回ポーリング時は、保存したupdate時刻以降のデータのみを取得するようにします。このことでデータの差分連携が可能となります。
jdbc {
# 処理2. 重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
tracking_column => "updated_at" # ポーリング時、追跡するカラムを指定(重複したデータを取得しないために指定)
use_column_value => true # ポーリング時、取得したデータの中で最も遅い時刻のupdateの時刻を保持しておく設定(trueで機能がonとなる)
tracking_column_type => "timestamp" # 追跡対象カラムのデータ型を記載
}処理2-2. ポーリングの実行間隔を指定
ポーリングの実行間隔は「schedule」プロパティで指定します。今回は10秒間隔でポーリング実行します。
jdbc {
# 処理2. 重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
schedule => "*/10 * * * * *" # ポーリング間隔を指定(詳細はhttps://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html#_schedulingを参照)
}処理3. PostgreSQLに対するクエリを作成
ポーリング時に実行するクエリを記載しています。先ほど、前回ポーリング時のupdateの値をLogstash内部に保存していると記載しましたが、その値をクエリ内で使用したい場合は、「:sql_last_value」と記載します。
jdbc {
# 処理3. PostgreSQLに対するクエリを作成
statement => "
SELECT id, updated_at,
row_number() over(ORDER BY updated_at) as rownum # 「rownum」は取得データに対して振り分けた行番号。Filterステップで使用
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > :sql_last_value # 「:sql_last_value」を用いる事で前回ポーリング時に取得したデータの中で最も遅いupdateの時刻を使用可能
AND delete_flag = false # deleteされていないデータのみを取得
ORDER BY updated_at
"
}4-4-2. Filterの処理内容
Inputで取得したデータを加工する処理を記載します。処理の概要は以下です。
Inputで取得したidを5件ずつのリストに集約
PostgreSQLから取得したidをBodyに詰めてJava APIにリクエスト
JavaAPIから返却されたjsonを整形
ソースコードの全量です。以下、処理1と処理3を解説します。
filter {
# 処理1. Inputで取得したidを5件ずつのリストに集約
ruby { code => 'event.set("task_id", event.get("rownum") / 5)' } # 5件ずつに分割する
aggregate {
task_id => "%{task_id}"
code => 'map["ids"] ||= []; map["ids"].push("\"" + event.get("id") + "\""); event.cancel();'
timeout => 1 # 1 secs timeout
push_map_as_event_on_timeout => true
}
# 処理2. PostgreSQLから取得したidをBodyに詰めてJava APIにリクエスト(説明省略)
http {
# idの配列をbodyに詰めて、jsonを生成するAPIにリクエストを飛ばします
url => "<jsonを生成するAPIへのurl>"
verb => "POST"
headers => { "Content-Type" => "application/json" }
body => '{ "ids": [%{ids}] }'
body_format => "text"
}
# 処理3. Java APIから返却されたjsonを整形
# 不要なフィールドを削除
mutate {
remove_field => ["headers", "@timestamp", "ids", "@version"]
}
# フィールドの入れ子を解消(一段階目)
split {
field => "[body][sampleUsers]"
target => "sampleUsers"
}
# bodyフィールドを削除
mutate {
remove_field => ["body"]
}
# フィールドの入れ子を解消(二段階目)
ruby {
# 「sampleUsers」を削除
code => "
event.get('sampleUsers').each {|k, v|
event.set(k , v)
}
event.remove('sampleUsers')
"
}
}処理1. Inputで取得したidを5件ずつのリストに集約
処理1-1. idを5件ずつにまとめる
Java APIの処理内では、idを元に全カラムの情報を取得するためにPostgreSQLに対してクエリを実行しています。このため、id一件ずつクエリを実行するとパフォーマンスが悪くなります。よって、特定の件数分のidをまとめてbodyに詰めてJava APIにリクエストを送るようにしました。
今回は、Ruby filter pluginを用いてidを5件ずつ分割します。(説明の都合上、まとめる件数は少なくしています)。実装コードは以下です。
ruby { code => 'event.set("task_id", event.get("rownum") / 5)' } # 5件ずつに分割上記の実装のイメージは以下になります。行番号を表すrownumを「5」で割った結果をtask_idに登録します。すると、5個の単位でtask_idが重複し、task_idによってデータを分割できるようになります。
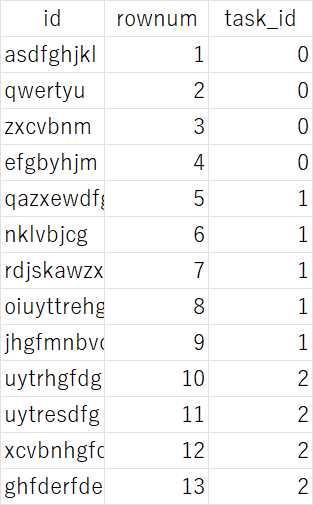
処理1-2.分割したidを一つの配列に格納する
続いて分割されたidを一つの配列に格納します。Aggregate filter pluginを使用します。
aggregate {
task_id => "%{task_id}" # task_id毎(5件毎)に処理を実行
code => 'map["ids"] ||= []; # 「ids」という空の配列を作成
map["ids"].push("\"" + event.get("id") + "\""); # 「ids」にidを登録
event.cancel();
'
timeout => 1 # 1 secs timeout
push_map_as_event_on_timeout => true
}rubyのプラグインで作成した「task_id」毎にAggregate処理を実行し、idやrownumを一つの配列にまとめます。処理のイメージは以下です。

②でAPIにリクエスト送る際は、idの配列をbodyに詰めてリクエストを投げます。
処理3. Java APIから返却されたjsonを整形
処理3-1. 不要なフィールドの削除
まず、Java APIから返ってくるjsonを確認しましょう。
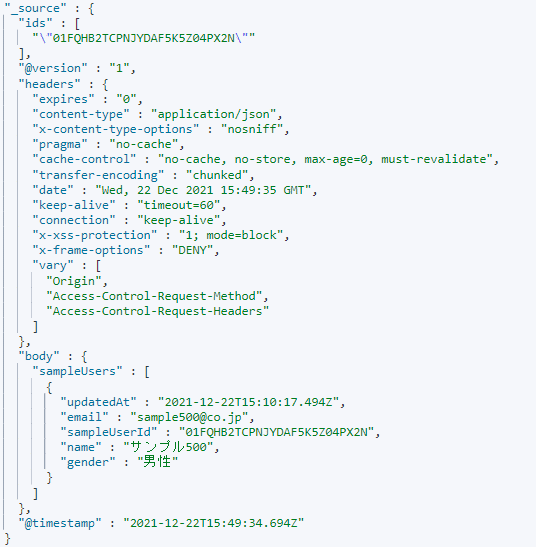
フィールドがたくさん付与されていることが分かるかと思います。しかし、Elasticsearchに登録する際に必要なフィールドは「body」のみです。「ids」や「@version」など不要なフィールドは削除しましょう。
その際使用するプラグインがMutate filter pluginです。不要なフィールドを配列形式で記載すると、mutateがフィールドを削除してくれます。実装コードは以下です。
mutate {
# []内の不要なフィールドを削除
remove_field => ["ids", "@version", "headers", "@timestamp"]
} 処理3-2. 「body > sampleUsers」の入れ子を無くす
不要なフィールドを削除しましたが、登録したい各カラムのユーザー情報(nameやgenderなど)が「body>SampleUsers」配下に入っており、入れ子な状態となっているため、「_source」直下に配置されるようjsonを整形します。Split filter pluginとRuby filter pluginを使用して実現します。


まずは、Split filter pluginを用いて「body > sampleUsers」フィールド配下をコピーし「sampleUsers」配下に複製します。また、本処理を実行することにより「body」フィールドが不要となるため、mutateプラグインで「body」フィールドを削除します。
split {
# 「body > sampleUsers」フィールド配下をコピーし「sampleUsers」フィールド配下に複製する
field => "[body][sampleUsers]"
target => "sampleUsers"
}
mutate {
# bodyフィールドを削除
remove_field => ["body"]
} これにより以下のような構造となり、入れ子が一段階解消されます。
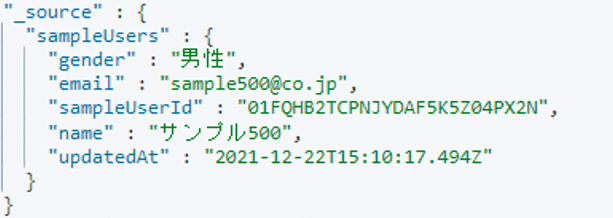
最後にRuby filter pluginを使用してさらに入れ子を一段階します。「sampleUsers」配下のユーザー情報を「key, value」の形式で取得し、「_source」配下にセットしています。また、Split filter pluginの時と同様に、不要になった「sampleUsers」をremoveしています。(Ruby filter pluginで行っている事はやや複雑ですが、ご覧いただければと思います)
ruby {
# 「sampleUsers」を削除
code => "
event.get('sampleUsers').each {|k, v|
event.set(k , v)
}
event.remove('sampleUsers')
"
}これにより以下のような構造となり「_source」配下にユーザー情報が配置されるようになりました。

4-4-3. Output
Filterで整形したデータをElasticsearchに登録します。処理は「Elasticsearchの設定値を記載する」のみです。
ソースコードの全量です。特別難しい設定はしていないため、解説は省略します。
output {
elasticsearch {
# Elasticsearchの設定値を記載する
user => <username>
password => <password>
hosts => "http://elasticsearch:<port>"
index => "sample_user" # データを登録するindexを指定
document_id => "%{[body][sampleUsers][sampleUserId]}" # document_idを指定。bodyフィールドからsampleUserIdを取得する。
}
}4-5. logstashDelete.conf
PostgreSQLでデータをdelete(論理削除)した際のLogstashの処理内容を記載しています。ほとんどの処理が「logstashUpsert.conf」と同一なため、解説は省略します。
大きな違いはJava APIを経由してjsonを作成する必要が無いという点です。Elasticsearchからデータを削除する際に必要な情報は「id」のみなためです。
「logstashUpsert.conf」との差分をコメントに記載します。
input {
jdbc {
# 処理1. JDBCDriverをセット
「logstashUpsert.conf」と同一
# 処理2. 重複したデータを取得しないための設定(差分連携) & ポーリングの実行間隔を指定
「logstashUpsert.conf」と同一
# 処理3. PostgreSQLに対するクエリを作成
statement => "
SELECT id, updated_at
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > :sql_last_value
AND delete_flag = true # deleteされているデータのみを取得
ORDER BY updated_at
"
}
}
filter {
json {
source => "message" # クエリ実行の結果をjsonにparse
}
# jsonを整形
「logstashUpsert.conf」と同一
}
output {
elasticsearch {
# Elasticsearchの設定値を記載する
「logstashUpsert.conf」と同一
action => "delete" # actionをdeleteに設定し、削除を実行
}
}5. 動作確認
では、実際にLogstashを起動してデータ同期ができているのかを確認したいと思います。
5-1 事前準備
動作確認の前に2点作業を行います。
① 同期元となるPostgreSQLのテーブルを確認
テーブル名「sample_users」
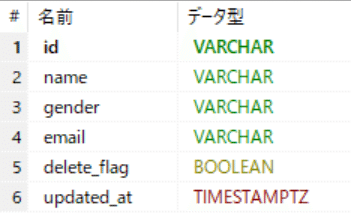
カラム一覧(pkは「id」カラム)
登録済みデータ(下記画像は一部)

計500件データを登録しています。男性が251人。女性が249人です。また、delete_flagがtrueなユーザーは250人。falseなユーザーは250人です。
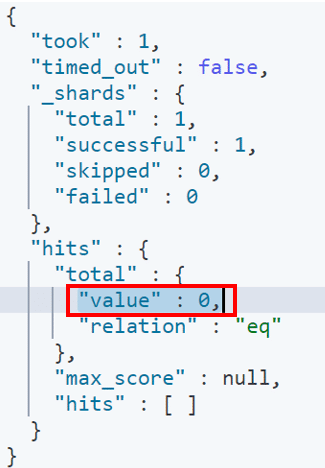
② Elasticsearchに対してインデックス作成とマッピング定義を行う
kibanaを用いてインデックス作成とマッピング定義を行います。
インデックス名: 「sample_users」
mapping定義

Elasticsearchにデータが登録されていない事を確認します。
5-2. logstashUpsert.confの動作確認
Logstashを起動します。起動成功とポーリング開始のログが出力されました。
[2021-12-05T07:27:24,947][INFO ][logstash.javapipeline ][my-pipeline_2] Pipeline started {"pipeline.id"=>"my-pipeline_2"}
[2021-12-05T07:27:24,957][INFO ][logstash.javapipeline ][my-pipeline_1] Pipeline started {"pipeline.id"=>"my-pipeline_1"}
[2021-12-05T07:27:25,025][INFO ][logstash.agent ] Pipelines running {:count=>3, :running_pipelines=>[:".monitoring-logstash", :"my-pipeline_1", :"my-pipeline_2"], :non_running_pipelines=>[]}
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/cronline.rb:77: warning: constant ::Fixnum is deprecated
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/cronline.rb:77: warning: constant ::Fixnum is deprecated
[2021-12-05T07:27:30,898][INFO ][logstash.inputs.jdbc ][my-pipeline_2][bbae2c777b58fce14151e21e76b05ef310f8e178564be80653210df2f40122ef] (0.021660s)
SELECT id, updated_at
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > '1970-01-01 00:00:00.000000+0000'
AND delete_flag = true
ORDER BY updated_at
[2021-12-05T07:27:30,902][INFO ][logstash.inputs.jdbc ][my-pipeline_1][93fbe6660a8e61eda7a16258f6ec694926e2062944c227d61ae2486dac3049ae] (0.028308s)
SELECT id, updated_at, row_number() over(ORDER BY updated_at) as rownum
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > '1970-01-01 00:00:00.000000+0000'
AND delete_flag = false
ORDER BY updated_atポーリング実行されたため、Elasticsearchにデータが登録されているか確認してみましょう。
Elasticsearchにデータが同期されている事をkibanaで確認します。

データが同期されていました。「logstashUpsert.conf」が正常に動作している事を確認できました。
次は、PostgreSQLで男性のdelete_flagを全てtrueに変更して、その情報がElasticsearchに同期されるのか「logstashDelete.conf」の動作確認のために確認してみましょう。
5-3. logstashDelete.confの動作確認
PostgreSQLで以下のクエリを実行し、全ての男性のdelete_flagをtrueに変更します。

logstashDelete.confが実行されたログが出力されました。
[2021-12-05T07:36:30,320][INFO ][logstash.inputs.jdbc ][my-pipeline_2][bbae2c777b58fce14151e21e76b05ef310f8e178564be80653210df2f40122ef] (0.003356s)
SELECT id, updated_at
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > '2021-12-05 07:35:42.551000+0000'
AND delete_flag = true
ORDER BY updated_at
[2021-12-05T07:36:40,198][INFO ][logstash.inputs.jdbc ][my-pipeline_1][93fbe6660a8e61eda7a16258f6ec694926e2062944c227d61ae2486dac3049ae] (0.002799s)
SELECT id, updated_at, row_number() over(ORDER BY updated_at) as rownum
FROM sample_users
WHERE updated_at < NOW()
AND updated_at > '2021-12-05 07:08:54.557000+0000'
AND delete_flag = false
ORDER BY updated_atポーリング実行されたため、Elasticsearchに同期されているか確認しましょう。

kibanaを確認すると、データ件数が166件に減少しており、genderも女性のみになっています。「logstashDelete.conf」が正常に動作している事を確認できました。
6. 苦労した点・工夫した点
6-1. 苦労した点: Pipelineの処理をブレークポイントで止められない
今回の実装で最も苦労した点は、Filterでのjsonの整形処理です。どのようにフィールドの入れ子を解消するのか、という実装の苦労はもちろんですが、それよりも動作確認に苦労しました。ブレークポイントを貼ってLogstashの処理を途中で止めることができないため、処理結果や出力されたログを見てどの処理が悪かったのかの仮説を立て、Logstashを再起動しつつ試行錯誤する必要がありました(※)
もし、Pipelineの処理をブレークポイントで止める方法をご存じの方がいらっしゃればご教示いただければと思います。
※ logstash.ymlにて以下を設定する事でPipelineの変更を検知してLogstashを自動で再起動してくれますので、是非有効活用してください。
# Pipelineの変更を検知してLogstashを自動で再起動する
config.reload.automatic: true6-2. 工夫した点: 複数件のidをまとめてbodyに詰めた
今回の実装で工夫した点は、FilterでJava APIにアクセスする際に複数件のidをまとめてbodyに詰めるようにしたという点です。この工夫により、Java APIへのアクセス回数を減らすことができ、Java API内でのクエリ実行回数も減らすことができました。
Logstashのプラグインは豊富なため、このような非機能要件を比較的手軽に満たすことができます。特にRuby filter pluginは自由にrubyのコードを書けるため実装の幅が大きく広がります。(rubyのキャッチアップが必要になるのですが)
7. 最後に
以上、Logstashを用いてPostgreSQLのデータをElasticsearchにポーリングで同期する仕組みの実装例の紹介でした。
実は、本実装のみだとデータの同期漏れが発生するケースがあります。また、upsertとdeleteでconfファイルを分割しなくてもよい方法がある等、本実装はまだまだ改善の余地があります。
Logstashはシンプルに見えて実は奥が深いツールだと思いますので、是非皆さん色々と触ってみてください。
本記事がどなたかの参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?