
#D-TW05 ツイッターデータを集めて掃除の方法を考える後編 (How do I clean data - Second part)

(English Follows)
前回は実際に集まったデータの掃除(クリーニング)についての前編として、いろいろな方法でいらないデータを消していく!編を書きました。「分析に必要のない」ツイートを地道に地道に見つけて潰していこうという心躍る(?)話でした。さて今回は前回にもまさる地道な内容となっているような気がします。乞うご期待(??)
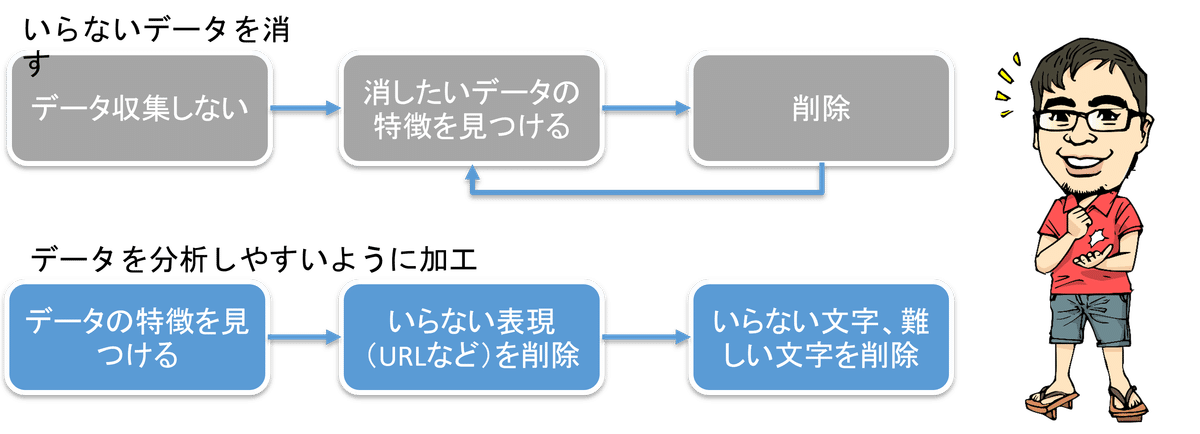
集めたツイートを吟味
いらない表現を削除
文字削除と標準化
集めたツイートを吟味
まずは前回で集めたツイートを分析しましす。。。いや、ざっと見ていってどんな特徴があるのかを調べていきます。例えばの例を上げてみます。

今回は分析に使いづらいもの、必要ないものは削除。分析がしやすいように整えるの2つを前回と同じく100点を目指さない方式で潰していきます(不安)。まず、もちろんのことではありますが1のように顔文字が頻出してきます。消したい。。。どうやって??いわゆる絵文字みたいなものも多いです(2のような)。これは本当はうまく分析に使ってみたいところではありますが、結構顔の解釈も人によって違ったりして難しいので一旦削除します。画像が貼り付けてあるツイートはAPIで取ると、そのURLが入ってきてました(ほう)。URLは全削除かな。。4番の「♀」記号のような消したい文字みたいなものも有ったりします。さて一個一個消していきますか。
いらない表現を削除
細かいものを省くと3つくらい見つかりました。URLとリンクされた記事のタイトルあとはハッシュタグという感じです。ハッシュタグとURLはシンプルに見つけたら消すというロジックを書きましたがトリッキーなのはリンクされた記事のタイトルです。5番のようなやつなのですが、例えばYoutubeの動画をリンクするとその動画のタイトルが、ツイートの一部として表示されてしまっているのです。APIから帰ってくるデータの中にそのタイトルだけの項目が有ったので、それとマッチングして削除しました。
文字削除と標準化
ここも地味だった。。。顔文字、絵文字、記号などは削除これがなかなか手こずりました。一気に全部消す、顔文字削除みたいな方法がうまく全部をカバーできなくて、範囲指定と余ったものを一個一個消すという地道な方法を取りました。良い方法があったら教えて下さい(お願い)。最後に分析のときに例えば一番目と1番目は同じ単語として認識されてほしいのでそのようなゆらぎのある表現をできるだけ統一するようにしました。これも地道に。
ここまでやってようやくデータを分析する手前に到達しました。長い道のりでした。でも、、、やっぱり嫌いじゃない。
I wrote about how do we clean up data in the last article as the first part. Such exciting "non-sexy" jobs are introduced to delete tweets which you don't need for my analysis (Manually one by one). Then this second part of course is as sexy as the last one… Please take a look.

Take a close look at tweets one by one
Delete unnecessary expressions
Delete unnecessary characters and normalization
Take a close look at tweets one by one
Ok. What you basically would do is examine raw data to find what are in tweet data you cleaned at the past part. Well it is not the analysis but more like "Snow shoveling". You do till you see the ground… I listed some of the examples I found (Below).

Basically you delete all which is not necessary for your analysis purpose. Then you normalize data to make your analysis consistent. Again for this project, I don't go to get full mark but 70%-80% accuracy. Filling up rest of 20% would take too long time and I won't be able to finish it (No doubt).
The 1st example is well known and trouble some emoticons… Japanese people are so creative and created so many of them(How?). They are too difficult to be used for analysis. 2nd one is Emoji. Again I wanted to use them to analyze emotions in tweets but its a bit trouble some. Thirdly when tweets have images attached, API give "URL" in the tweet text. There are also special characters like "♀" which you might want to delete. Let make it one by one…
Delete unnecessary expressions
I found 3 major ones for may analysis purpose. URL, referred titles and hashtags. URLs and Hashtags are simple. You simply delete all of them from tweets. "Referred titles" are relatively tricky. When you refer to YouTube video for example, twitter insert the title of the movie in your tweet like example 5. In this case, you will also find the title in "referred title" column from data you get from API. So you match them to delete the text from tweets.
Delete unnecessary characters and normalization
It would be easy to imagine that you want to delete emoticons, emoji and special characters but I couldn't find very simple way to delete them. I programmed to delete them one by one. Let you know if you know the easy way to do this (Seriously). Second one include a bit of cultural context. To express "1" for example, Japanese has "1", "1(multi byte)" and "一(Kanji)", you would want to count them as the same words. So you have to normalize them. Well One by One(Again)…
Now finally we are ready to start analyzing data (Finally, Finally, Finally). It was tough and not sexy but well I love it…
この記事が気に入ったらサポートをしてみませんか?