高速大容量の代表的処理が、画像処理

高速大容量の代表的処理が、画像処理
2024年1月24初稿
画像処理の特徴と言えば、高速な処理が必要≪カメラで撮影
した映像を時間的に即、加工して肉眼で見た時間と感覚的に
同時に処理する事が望まれる≫及び、画像は、2次元データ
≪例えば、VGA【アナログ時代のカメラ相当で画素数が、
横(640)×縦(480)⇒307200】、HDMI
ハイビジョンだと1080×720⇒777600、更に
今のが1Kと最近は称して2Kが2560×1440⇒
3686400、4Kが3840×2160⇒
8294400≫と莫大な画素数(データ数)に成る事は、
理解して頂いて居る筈です!
詰り、大量なデータを高速に処理する必要が有るのが、画像
処理なのです!
私が、解説する「画像処理ライブラリ」には、画像処理に
特化しただけで無く、
汎用に高速に大容量データを扱う部分として
「クラス【class Support】」と名称「サポート」と処理の
サポートをする部分が有ります!
先ずは、コレを解説して現在のコンピューターでの高速化
技術とは何かを説明します!
1.高速化理屈
1-1.遅く成る原因
(1)遅い基本的理由
現在のコンピューター技術に少しだけ、詳しい人は、
CPU≪セントラル・プロセッシング・ユニット≫の
クロック数(電子回路として同期的に動く物なのでクロック
でワンステップ動作する)を上げれば早く成るとの原理で強
冷却≪CPU内部でアナログ的なノイズで誤動作が発熱で起
こり易く成るを防ぐ≫する事が高速技術と思って居る生半可
な知識を持って居るでしょうが、世界ランカーのスーパー
コンピューターなら考える必要が有るが、今使用されている
CPUは、大概高速に通常の製品で高速に動作します!
では、何が、「遅く成る」原因でしょうか?!
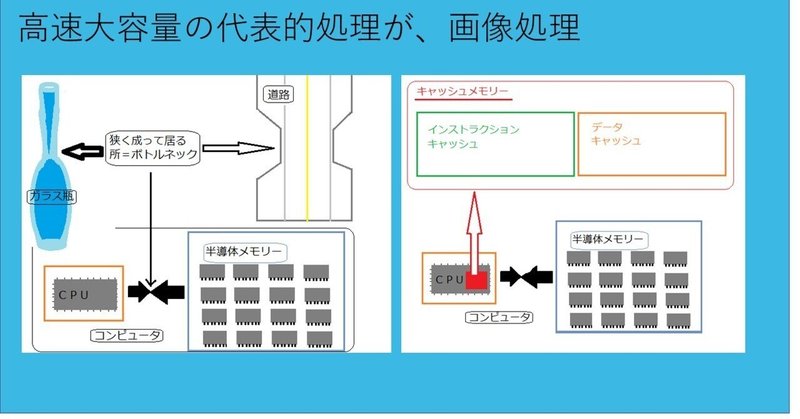
「ボトルネック」と言う単語を聞いた事が有ると思います!
ガラス瓶の様に中身を出す時に先端が細く成って居る為に
少しずつしか出て来ない⇒良く比喩的に「渋滞」の原因が
狭く成って居る部分とか使用され往々にしてボトルネックと
言われる事はご存じですね?!
では、コンピューターでは、どの部分かと言うと、CPUと
半導体メモリーとのデータの遣り取り入出力部分が、狭い為
に幾らCPUが高速に動いてもデータが来ないので遅いと言
う事です!
詰り「データーの渋滞」を解消する事が、高速化のミソで
す!!
(2)歴史的経緯
ボトルネックを解消する為に最初に考えたのは、詰まる原因
の首を太くする詰り、マルチビット化≪最初の半導体CPU
システムは、4ビットから始まりデータの幅を8ビット⇒
16ビット⇒32ビット⇒64ビットとビット幅を増やし、
8ビットCPUより16ビットCPUが高性能と言われた
時期が有った事もご存じですね!≫
ですが、ビット幅を増やすと弊害≪アナログ的な回路技術の
問題で全てのデータ線回路が時間的に揃わない⇒揃える為に
早く動く回路も遅くしか動か無い回路も遅い方に合わせる
必要が生じてビット幅を増やす事は頭打ちに成った≫、
次のアプローチが、「キャッシュ」技術です!高速に動作
出来るCPUチップ内に「キャッシュメモリー」を搭載して
使用頻度の高いデータは、CPUと半導体メモリー間の
データ入出力操作か発生し無い様にして結果、ボトルネック
を解消する事に成った!
現在の高速に動作するCPUは、大概、この機構を搭載して
居ます!
今回、解説する「画像処理ライブラリ」は、CPUに
キャッシュメモリーが搭載して居ると実力が発揮出来る様に
ソースコードを記述して居ます!!
1-2.キャッシュメモリーで解消
(1)インストラクションキャッシュ
安価なCPUでもキャッシュメモリー搭載と記載して有る
CPUには、必ず、機構として搭載して有るのが、
「インストラクションキャッシュ」⇒「コンピューターを
動作させる指示をインストラクションコード【命令】とし
てプログラムコードを半導体メモリーに格納して居るデータ
としての命令を読み込んで動作する事は、ストアドプログラ
ム方式【大天才フォン・ノイマンが現在のコンピューターの
元で彼の名前を冠されたノイマン型コンピューター】の基本
ですのでコンピューターを扱う人は当然、ご存知ですよね!
と小ネタを紹介したのは、現在のコンピューターの基本だか
らです!
そして大量のデータを処理する時は、ループ【繰り返し】
処理する事が多いと言う事もご存じですね?!
この画像処理ライブラリでは、勿論、ループが多く存在しま
す!」、だから、このインストラクションキャッシュを
最大限に活かすソースコードにして居ます!
void Support::up_fill(
int s, // 書き込むデータ 0..255
BYTE *pd, // メモリ領域へのPtr
int l // 書き込む大きさ
){
if( l >= 8 ){ // 8単位以上なら
l -= 8; // DownCuntを8単位進め
do{ // 8単位毎に
*pd++ = s; // データを書き込む
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
}while( ( l -= 8 ) > 0 ); //
l += 8; // DownCuntを8単位戻す
} //
while( --l >= 0 ){ // 残りを1単位毎に
*pd++ = s; // データを書き込む
} //
}
このコードを教科書的な記載にすると?!
void Support::up_fill(
int s, // 書き込むデータ 0..255
BYTE *pd, // メモリ領域へのPtr
int l // 書き込む大きさ
){
int i; // ループカウンタ
for( i = 1; i <= l; i++ ){ // for構文で繰り返し
*pd++ = s; // データを書き込む
}
}C++文法で記載して居ますが、C言語系に親しんで居る方
には分かる様に
void Support::up_fill(
int s, // 書き込むデータ 0..255
BYTE *pd, // メモリ領域へのPtr
int l // 書き込む大きさ
){で関数(Support::up_fill)⇒クラス「Support」の中の
「up_fill」との名称の関数で「up_」との先頭は、元々
C言語で開発して居た名残で大域定義の関数として
「汎用サポート用の意味」で「UnderProcess」
との位の意味の接頭語としていた物で「fill」で「埋める」
との意味でポインタ「BYTE *pd」と「BYTE型のポインタpd」
から始まるデータ領域を「int s」書き込むデータで長さ
「int l」個数書き込む事(埋め込む)を意味します!
ここで【BYTE】は、解説『エラーコード等各種単純定義』で
説明している
「typedef unsigned char BYTE;」と「バイト単位の画素」を
示して居ます。
そして本体のローカル変数「int i」をループカウンタとし
て「l個数分」の数を数える事にして
「for(i=1;i<=l;i++){*pd++=s;}」とfor文の構文で
「*pd++=s;」を「l個数分」繰り返します!とC言語の
教科書的な記載は、理解して頂けたと思います!
while( --l >= 0 ){ // 残りを1単位毎に
*pd++ = s; // データを書き込む
} //画像処理ライブラリでの記載「while(--l>=0){*pd++=s;}」
が、教科書的な記載「for(int i=1;i<=l;i++){*pd++=s;}」
と目的の動作「【*pd++=s;】を【l個数分】繰り返す」が
同じと理解して頂けたと思います?!両者の違いは
「変数l」の値が元の値と同じか変わってシマウかの違いで
画像処理ライブラリでの記載は変わっても影響が無い為に
採用しました!
メリットとしては、ローカル変数「int i」を使う必要が無
い事です!多少なりともコンパイラに取ってCPUの
レジスター割り振りは、速度を重視する機械コード生成に
影響するとの意味も有りますが、元々私が、ターゲット
CPUとした68Kシリーズ最後の高性能CPUで有る
「MC68060」に都合が良いコンパイラシステム
「MCC68K」で機械コード(実際にはアセンブラ表記)
の生成が一番、効率的に成るC言語のソースコードを研究
した為にコノ表記に辿り付いたのです!
さて、画像処理ライブラリでの記載
「while(--l>=0){*pd++=s;}」デアル部分のコメントに
「残りを1単位毎にデータを書き込む」と有り、この部分
は、補足的な部分だと読んで頂けたかなと説明して実際に
大量のデータを操作する
if( l >= 8 ){ // 8単位以上なら
l -= 8; // DownCuntを8単位進め
do{ // 8単位毎に
*pd++ = s; // データを書き込む
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
}while( ( l -= 8 ) > 0 ); //
l += 8; // DownCuntを8単位戻す
} //に付いて解説すると、読解力の有る人は、
*pd++ = s; // データを書き込む
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //
*pd++ = s; //と「*pd++ = s;」を8個並べて有る事は理解してこの並べて
有る所自体の実行回数が「8分の1」で有る事は理解して
頂いていると思います?!何故この様に長々と記述したかと
の理由は、実際に必要なデータ操作の「*pd++ = s;」の
処理時間だけで無くループをコントロールする為の
「while(--l>=0){}」≪回数を数え、ループを続けるか
止めるかの処理≫もCPUの処理時間を浪費してシマウ?!
少しでも効率を考えたら、この処理時間を極小にして真水の
データ操作の「*pd++ = s;」の割合を高めたらと考えての
ソースコードを記載して見ました!
C言語に対して読解力の有る方には、最早、読んだだけで
理解して頂いているので今更、解説はその方々には、不要と
思いますが、「画像処理ライブラリ」の記載での特徴だけ
解説します!
if( l >= 8 ){ // 8単位以上なら
l -= 8; // DownCuntを8単位進め
do{ // 8単位毎に
・・・中身は省略・・・
}while( ( l -= 8 ) > 0 ); //
l += 8; // DownCuntを8単位戻す
} //
while( --l >= 0 ){ // 残りを1単位毎に
*pd++ = s; // データを書き込む
} //最初の「if( l >= 8 ){・・・}」ブロックでデータの
個数「l」⇒「寧ろ、個数と言う依り長さlengthの【l】との
意味で【l】としました」、「l>=8」との条件でデータ数が
8依り多い場合「l -= 8;」⇒「8画素単位データ」を処理
するとして一旦、8を減少、そして「do{・・・中身は省略
・・・
}while( ( l -= 8 ) > 0 );」とdo~while構文
「中身を実行した後でループ続行判断」でその判断が、
「( l -= 8 ) > 0」とループが出来るのが、8以上だから
8を引いても0以上ならばループが出来ると判断する事で
中身「*pd++ = s;を8文並べた列」を実行するのです!
そしてループが、終了した時点で「l += 8;」で数を戻すの
は、判断に使用した「}while( ( l -= 8 ) > 0 );」で
8減じるのでループを抜けた時点で「-7から0」と成り、
残りのデータ数が8未満の場合の処理として
「while( --l >= 0 ){*pd++ = s;}」が正しく処理できない
為の補正です!
コンピュータアルゴリズム作成とか使用に成れている御貴兄
には、同じ動作を行うモット分かり易い記述が可能ではと思
われると思いますが、C言語で作成時、ターゲットにした
MC68060で動作するコードを作成するコンパイラ
MCC68Kで生成された機械コード(アセンブラ表記)の
クロック数合計が最小に成る様に試行錯誤した為ですので
悪しからず!
更に解説!この解説文章では、インストラクションキャッ
シュに付いて記載しています!インストラクションキャッ
シュを有効に使う秘訣は、生成された機械コードが小さく成
る様にする事が肝要です!
キャッシュメモリーは、高速化技術ですが、ヘタに使用する
と「遅く成る」現象が発生します≪キャッシュミスと称され
る現象で原因は、キャッシュメモリー内に目的のデータ(
インストラクションキャッシュでは機械命令コード)が入っ
て無く外れた為に大幅なデータの取り込みがCPU外部の
半導体メモリーとの間で行われる為に想定外の時間ロスが
発生する≫事が起こりますので必要な機械コードの塊≪
ループしている中身≫が、キャッシュに格納されて居る事が
機械命令コード必要成るから、コンパクトに機械命令コード
の塊が生成される事が必要に成ります!
今回、説明に使用した「Support::up_fill()」は、
BYTE単位でデータの列を書き込みと言う比較的簡単な機能の
メソッドですが教科書的な記載でのループ制御部分の処理
時間が「画像処理ライブラリ」の「Support::up_fill()」の
記述では、約8分の1に成って居る事は理解出来たと思いま
す!
何故、「約」なのかヒョットシテ理解されて無い方に解説す
ると≪データ数が8の倍数で無くても動作する様に残りの
部分を動作させる機構を含んで居る≫からです?!
そしてコンピュータアルゴリズム作成とか使用に成れている
御貴兄には、同じ動作を行うモット分かり易い記述が可能で
はと思われると思いますが、
C言語で作成時、ターゲットにしたMC68060で動作
するコードを作成するコンパイラMCC68Kで生成された
機械コード(アセンブラ表記)が最も効率的な機械命令
コードが生成サレル様に試行錯誤した為ですので悪しから
ず!
ここまでの話でコンパクトな機械命令コードで生成された
「Support::up_fill()」がインストラクションキャッシュに
全て入って居る状態で動いている時は、機械命令コードの
読み出しを半導体メモリーから行う事が無いので無駄な
真水(*pd++ = s;で半導体メモリーのデータ書き込み)以外
の半導体メモリーへのアクセスが、実質的に発生し無いので
高速に動作する事は理解して頂けたと思います!
尚、「Support::up_fill()」は、典型的な例です?!
同じ様に単純に繰り返す処理は、同じ様な複数個≪
主に4回・8回と2のべき乗回数を使用≫繰り返す処理には
同じ様な機構で構成されたソースコードにしていますので
高速化の為のテクニックだと考えて下さい!
(2)データキャッシュ
高性能を謳って居るCPUには、当然の様に搭載されている
のが、データキャッシュです?!
この「画像処理ライブラリ」は、データキャッシュが、
効率的に動いて初めて本領を発揮するソースコードが多数含
まれています!
勿論、ご存じの様にキャッシュメモリもCPUチップと同じ
半導体の中に組み込まれて初めて意味を持つので半導体
チップに占めるキャッシュメモリーの部分には物理的な限界
があります!とココまで記載すると理解力の有る御貴兄なら
ば、キャッシュメモリーを有効に使う様なデータアクセスを
考えているのだと分かると思いますが?!
具体的には、先ず、例として、データ幅を同じ処理するの
ならば、教科書的なアルゴリズム依り小さくする事が考え
られます!
劇的な効果が合った処理は、教科書的な方法としても基本な
ので載せている「Filter::LabelingImage()」関数では、
VGA画像サイズ時代で処理可能と考えたラベル画像(
1~65535と図形にラベル番号と称する固有番号を付け
【ラベル付けと称する】、後段でそのラベル付けされた
図形の面積とかの幾何学的特徴算出に使用する基本的な処理
)を使用する為にラベル画像のデータ幅が16ビットとして
使用して居ましたが、これでは最終的なラベル付けされる前
の仮ラベルと称するラベルが容易に更に大きなHDMIハイ
ビジョン画像では、対応出来ないので、16ビットの次が倍
の32ビットと無駄に大きなデータ幅を使用する事にCPU
チップ事情で成るのだと考え、逆に8ビットデータ幅で処理
すれば、データ幅が小さく成るのでデータキャッシュの使用
効率が高く成るとの理由で「Filter::MeasureNumber()」
関数を初めとする「Filter::Measure○○○○()」系関数を
記載しましたが、これは、クラス「class Filter」の解説で
解説します!
2.補足
主に、クラス「Support」の中の「up_fill」を俎上に上げて
解説しましたが、
このクラス「Support」は、「up_fill」の様に基本的な汎用
処理を高速に動作する記載していますが、それ以外にも、
裸のCPUチップを組み込み装置に組み込む為の基本的な
処理を記載しています!
近々クラス「Support」の解説は行いますので乞うご期待と
記載して置きます!
3.期待
最近、トヨタ自動車やソニーグループなど日本の主要企業
8社が共同で設立した「Rapidus(ラピダス)」が
ビヨンド2nルール半導体開発体制を整えると
話題だ⇒そこでエッセイ『期待:ビヨンド半導体開発構想
』を期待≪高速化処理機構も考慮して欲しい≫を込めて
発表しました!
文末
この記事が気に入ったらサポートをしてみませんか?