
AIテキスト分析ツール【UserLocalテキストマイニング】の使い方を解説!

テキストマイニング(Text mining)とは、大量の会話、文章などのテキストデータから目的に応じた情報を抽出することです。
テキストマイニングのツールを使うことで文章から有益な情報の「見える化」が可能となり、企業や組織全体で情報の共有もしやすくなります。
テキストマイニングは顧客主体のマーケティングが求められている現代では必須の分析手法と言えるでしょう。
-UserLocalテキストマイニング-
UserLocalテキストマイニングでできること
【言葉の出現頻度分析】
入力したテキストに登場する言葉の出現頻度を調べ、スコア化して表示。
名詞や動詞など、それぞれで確認できます。
【ワードクラウド】
ワードクラウドとは、テキストの中で出現頻度が高い単語を大きく、小さい単語を小さく表示することで、出現頻度を図で表す機能です。
視覚的に単語の出現頻度を確認できる方法として用いられます。
AIテキストマイニングにもこの機能が搭載されています。
【共起ネットワーク】
これは、単語同士のつながりを円と線によって図示したものを指します。
どの単語とどの単語が同時に使われやすいのかを視覚的に把握可能です。
UserLocalテキストマイニングの使い方📝
使用方法は簡単で、特に登録やインストールがなくWeb上のみで使用できます。
フォーム入力部分に分析したいテキストを入力、もしくはテキストファイルをアップロードすることで、分析が可能となっています。

今回はテストとして「走れメロス」をサンプルにしてみました。
ワードクラウド☁️
スコアが高い単語を複数選び出し、その値に応じた大きさで図示しています。
単語の色は品詞の種類で異なっており、青色が名詞、赤色が動詞、緑色が形容詞、灰色が感動詞を表しています。

単語出現頻度🫧
こちらは文章中に出現する単語の頻出度を表にしています。
単語ごとに表示されている「スコア」の大きさは、 与えられた文書の中でその単語がどれだけ特徴的であるかを表しています。
通常はその単語の出現回数が多いほどスコアが高くなりますが、 「言う」や「思う」など、どの文書にもよく現れる単語についてはスコアが低めになります。

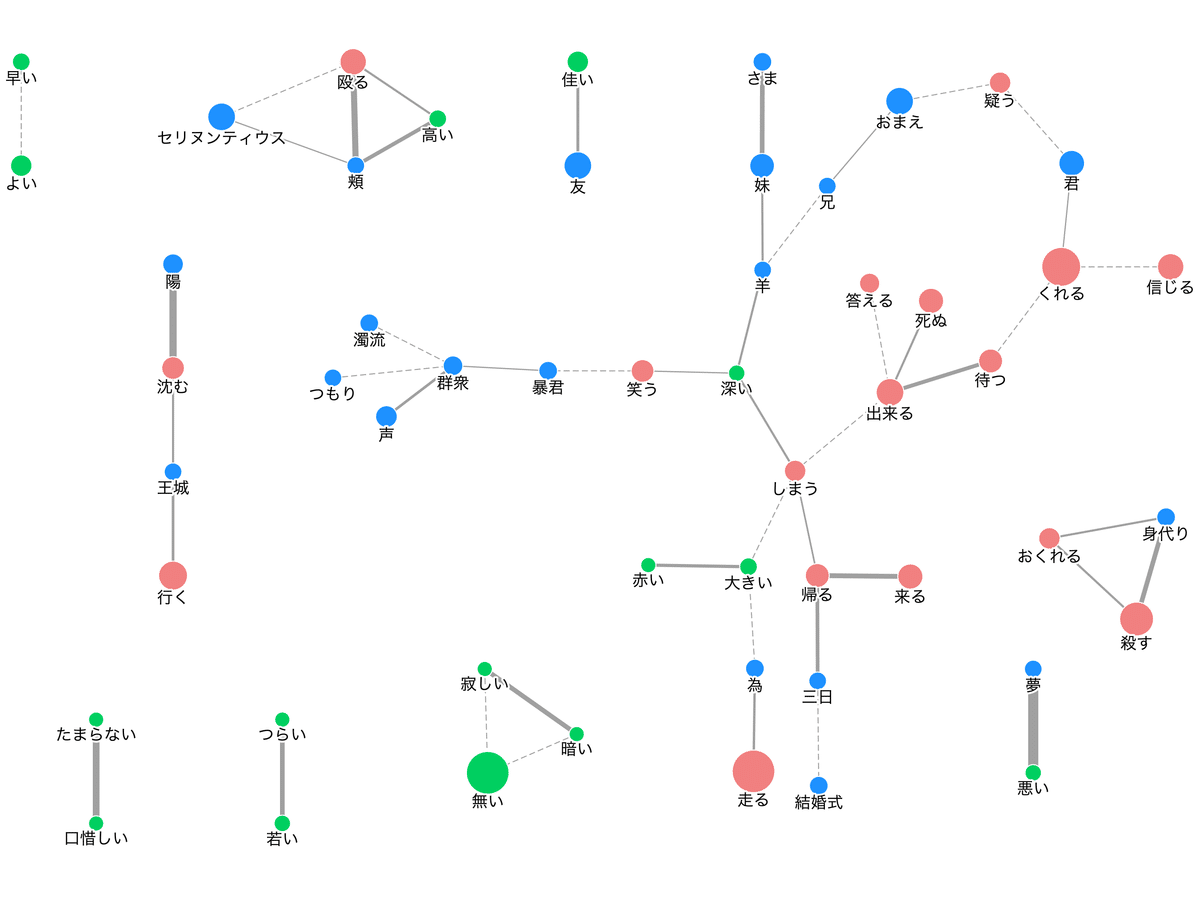
共起キーワード🌀
文章中に出現する単語の出現パターンが似たものを線で結んだ図です。
出現数が多い語ほど大きく、また共起の程度が強いほど太い線で描画されます。
共起とは、一文(改行や「。」などで区切られた各文)の中に、単語のセットが同時に出現するという意味です。
2次元マップ🗾
文章中での出現傾向が似た単語ほど近く、似ていない単語ほど遠く配置されています。
距離が近い単語はグループにまとめ、色分けしています。

感情分析AI🤖
文書全体を分析し、感情の傾向を可視化しています。
「ポジネガ」は、文章に含まれるポジティブな感情の文とネガティブな感情の文の存在比を示しています。
「感情」は、文章に含まれる各感情の度合いを数値に換算しています。
なお、各感情の数値は、全ての感情の平均値を50%とした偏差値です。

ダイジェスト📜
文書中の重要な文のみを抜粋して表示します。
抜粋する際の行数は3行・5行・10行から選択できます。

ハイライト✏️
文書中の重要な部分をハイライトして表示しています。
「マーカー」表示では重要部を赤くハイライトしています。
「ヒートマップ」表示では、赤(重要度高)・黃(重要度中)・青(重要度低)で文の重要度を色分けをしています。
「モノトーン」表示では、重要部の文ほど濃く大きく表示しています。

このような解析結果を見るだけで、大体の主人公や重要人物、ストーリーを把握することができます。
2つのテキストを比較📂
このように2つのテキストを一度にデータ化して、見比べることが可能となっています。
一目で伝えたい内容の重要度がわかるのが、利点です。

2つの文書に出現する単語を、それぞれどちらの文書に偏って出現しているかでグループ分けし、表にしています。
グループ中の単語は出現頻度が多い順に並ぶ傾向があります。

音声入力🎤
音声での入力からの分析も可能となっています。

このように大量の文章データをクラウド上で分析・可視化することで、気づきを得ることができるAIサービス「UserLocalテキストマイニング」。
自由記述のアンケート結果やお問い合わせデータ、SNSのクチコミデータを分析し、ビジネスのプレゼン資料や、傾向対策に利用することができます。
この記事が気に入ったらサポートをしてみませんか?