
プログラミング初心者がPythonでワインの品質を予測してみた

はじめに
はじめまして!
お読みいただきありがとうございます。
プログラミング初心者のゆかと申します。
プログラミングを学習したい!と思い、Aidemyさんに入校し、早5カ月…
学習の成果として、Pythonで教師あり学習の回帰分析を行い、
ワインの品質を予測してみました!
※教師あり学習の回帰分析とは?
予測したいデータに対し、すでにわかっているデータの関係性を元に推定するアプローチです。特に数値を予測するときに「回帰」と表現します。
プログラミングが全くわからない方にも
わかりやすい内容にしたいと思いますので
初心者の方にはぜひ、最後まで読んでいただけると嬉しいです!
実行環境について
実行環境はGoogle Colaboratoryを使用します✨
(実行当時のバージョンはPython 3.7.13です)
こちらはインストール不要で、誰でもすぐに使用できますよ!
まずはデータセットを準備!
予測をするにあたり、まずはデータが必要となります。
今回はKaggleという、企業や研究者がデータを投稿するプラットフォームより、以下のデータセットをお借りしました。
データセットをDLすると、アルコール度数や酸性度などのデータが入ったExcelファイルである事が確認できます。

英語で色々とワインの成分についての記載がありますが、
「quality」 = ワインの品質
である事だけ把握できればOKです!
(「quality」以外の項目によって、ワインの品質が決定付けられています)
このデータを使って何をするのか?

次に、このデータを利用して何をするのか?について把握します。
本記事の目標として、
①「quality」以外のデータから、「quality」の正しい数値(5、6など)を予測できるかどうか?
②予測できるとすれば、その精度はどれくらいになるか?(目標は60%~70%)
③複数の手法を比較して、一番精度の良い手法を探せるか?
この3つを達成することを目標として、予測を行っていきたいと思います!
早速コードを書いてみよう

それでは早速コードを書いていきましょう!
予測をするにあたり、必要なモジュールを記述していきます。
今回、予測に使用する手法は「線形回帰」「ラッソ回帰」「リッジ回帰」の3つとします。
この3つを比較し、最も精度の高い手法を探していきたいと思います!
# 必要なモジュールを記述します。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge*import pandas as pd = pandas というデータ解析ライブラリを読み込む
*from sklearn.model_selection import train_test_split = データを訓練用(学習用)とテスト用に分割する
*from sklearn.linear_model import LinearRegression = 線形回帰という手法を利用する
*from sklearn.linear_model import Lasso = ラッソ回帰という手法を利用する
*from sklearn.linear_model import Ridge = リッジ回帰という手法を利用する
3つの手法についての簡単な説明は以下のようになります。
(書いてみたものの、私にもまだ良くわかりません…)
線形回帰とは:データの特徴の傾向を直線に表して、株価の予測や家賃の予想などの数値のデータを求める手法
ラッソ回帰:最小二乗コスト関数に対して、重みの合計を足したもの(L1正則化項という)
リッジ回帰:正則化された線形回帰の一つで、線形回帰に「学習した重みの二乗(L2正則化項)」を加えたもの
さて、必要なモジュールが記述できたら、
次にDLしたワインのデータを読み込みます。
#データの読み込み
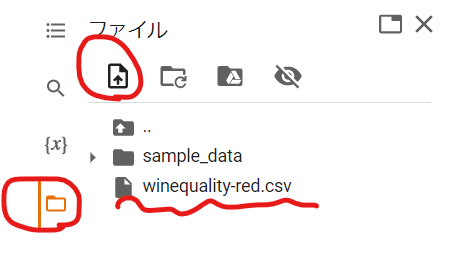
df = pd.read_csv("/content/winequality-red.csv")*Google Colaboratory上で作業を行う場合ですが、
以下のように、セッションストレージにアップロードを実施した上、
パスをコピー&上記のコードのようにペーストして下さい!
私はここがわからず、自分のPCから引っ張ろうとしてました…とほほ
次に、「説明変数」と「目的変数」の記述をしていきます。
Googleで検索すると、どのサイトも小難しく書いてあるこの変数ですが…
「説明変数」(x)= ワインの品質を決定付ける quality以外の項目
「目的変数」(y)= quality(ワインの品質、今回予測したいのがコレ!)
簡単に説明すると、以上のようになります💡
そして、この2つをコードで記述してみると…
#xに説明変数
x = df.drop(columns='quality')
#yに目的変数
y = df['quality'] はい!こうなります!
しかし、私のようなプログラミング初心者は一筋縄ではないので、
「説明変数(x)はquality以外のはずなのに、どうしてqualityが入っているの?」
と疑問に思うかと思います…
実は、df.drop(columns='quality') は、quality を除外する というコードになっているのです。
drop=落とす columns=列 という単語に着目していただくと、
列からqualityを落とす…とイメージしていただけると思います✨
そして、目的変数(y)については、qualityと記述していきます。
これで、説明変数と目的変数の記述は完了です!
次に、読み込んだデータを「学習データ」と「テストデータ」に分割します。
全て学習データにしてしまうとテストができませんし、
全てテストデータにしてしまっても、
学習していないので結果が出せませんよね。
そのため、データを分割する処理を行っていきます!
#学習データとテストデータに分割
train_X, test_X, train_y, test_y = train_test_split(x, y, test_size=0.2)また難しそうなコードが出てきましたが、知れば意外とカンタン💡
train (学習データ)と test (テストデータ)を合わせて100%とし、
test_size=0.2 でテストデータを20%と指定することによって
学習データを80%、テストデータを20%に分割する、というコードになります!
次に、手法を3つ使用するにあたり、
それぞれの手法での結果を比較し、最も精度が良いものを出力するためのコードを記述します。
max_score = 0
best_model = ""こちらのコードについては、後の内容と関連するため一旦省略します👌
そしていよいよ、3つの手法の記述を行っていきます…!
まずは線形回帰です。
# 線形回帰
model = LinearRegression()
#学習データでモデルを作る
model.fit(train_X, train_y)
#テストデータでsocreを出す
score = model.score(test_X, test_y)model = LinearRegression() で線形回帰を使います!という事を表明し、
model.fit(train_X, train_y) で、学習データよりモデルを作ります。
そして、score = model.score(test_X, test_y) と記述する事によって、
なんと!線形回帰での予測ができてしまいます。
しかし、これだけでは予測した値が表示されないので、
線形回帰だけで結果を表示する場合は
print(score)と追記してみましょう。すると…
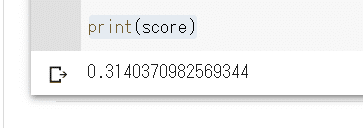
この数値は、qualityが5のワインなら、
その他のデータからきちんと5と予測できるかどうか、
という精度を表す数値になっています。
1に近づくほど良い結果になりますので、これではあまり良くなさそうですね…
という事で、残り2つの手法についても記述&比較していきましょう!
線形回帰のコードに戻り、こちらに少々修正を加えます。
# 線形回帰
model = LinearRegression()
#学習データでモデルを作る
model.fit(train_X, train_y)
#テストデータでsocreを出す
score = model.score(test_X, test_y)
#もしmax_score < scoreならmax_score = scoreと更新する
if max_score < score:
max_score = score
best_model = "線形回帰"先ほど結果を表示するために追記した、
print(score)
を削除し、
if max_score < score: max_score = score best_model = "線形回帰"
と追記をします。
if max_score < score: max_score = score best_model = "線形回帰"
については、
先に記述しておいた、max_score = 0 が関わってきます。
簡単に説明すると、線形回帰で予測した値が、
max_score で定義した0より大きければ、max_scoreを更新する
という意味になります。
さらに、best_modelで線形回帰と定義しておく事により、
後々、ベストスコアの数値と手法名を表示させられるという事になります。
(これについては説明が難しいのですが、最後まで読んでいただけるとわかるかも…)
このような形で、残り2つの手法についても同じように記述を行っていきます。
# ラッソ回帰
model = Lasso()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
if max_score < score:
max_score = score
best_model = "ラッソ回帰"
# リッジ回帰
model = Ridge()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
if max_score < score:
max_score = score
best_model = "リッジ回帰"これで、予測は終了です!
しかしこのままだと、結果や精度の高い手法名が表示されず、わからないので…
print("モデル:{}".format(best_model))
print("決定係数:{}".format(max_score))最も良い手法に更新されているはずのbest_modelと
最も良い結果に更新されているはずのbest_scoreを、
printを使って出力していきます…!
ドキドキ…
予測は成功!しかし、望まない結果に…
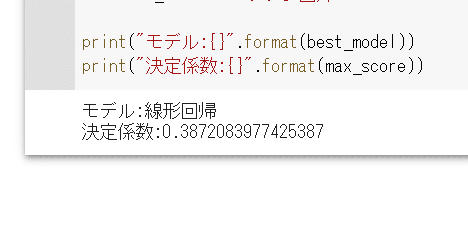
予測に成功しましたーー!!!!
これで目標①~③がまとめて達成できました💡
しかし、数値を見てみると…
決定係数が1に近づくほど精度が良いはずです…が、
一番良い手法でもこのような結果となりました…
目標は最低60%~70%なので、
結果の数値が0.6以上にならなければいけないのです。
こ、このままでは終われない…!(〇イデミーさんに怒られる!)
という事で、目標②・③についてはやり直しです(辛い)
一旦冷静になるために、ここまでのコードを以下にまとめてみました。
import pandas as pd
from sklearn.model_selection import train_test_split
# 必要なモジュールを記述します
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
#データの読み込み
df = pd.read_csv("/content/winequality-red.csv")
#xに説明変数
x = df.drop(columns='quality')
#yに目的変数
y = df['quality']
#学習データとテストデータに分割
train_X, test_X, train_y, test_y = train_test_split(x, y, test_size=0.2)
max_score = 0
best_model = ""
# 線形回帰
model = LinearRegression()
#学習データでモデルを作る
model.fit(train_X, train_y)
#テストデータでsocreを出す
score = model.score(test_X, test_y)
#もしmax_score < scoreならmax_score = scoreと更新する
if max_score < score:
max_score = score
best_model = "線形回帰"
# ラッソ回帰
model = Lasso()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
if max_score < score:
max_score = score
best_model = "ラッソ回帰"
# リッジ回帰
model = Ridge()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
if max_score < score:
max_score = score
best_model = "リッジ回帰"
print("モデル:{}".format(best_model))
print("決定係数:{}".format(max_score))他の手法を考えよう

さて、気を取り直して、
最適な手法を探し、精度60%~70%を出す!
という目標を達成するためにできる事を考えていきましょう。
プログラミング初心者には、一体どんな手法があるのかもわかりません。
前述した3つ以外の手法以外に、他にどんな事ができるのか…
パパっと楽に一番良い手法がわかるものはいかなあ~と考えた結果、
先に挙げた3つの手法を含め、
手法を総当たりする方法を試してみる事にしました!
※ここから先のコードについては、
説明が難しくなるため、詳細は割愛させていただきます💦
import pandas as pd
from sklearn.model_selection import train_test_split
# 必要なモジュールを記述します
from sklearn.utils import all_estimators
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
import warnings
#データの読み込み
df = pd.read_csv("/content/winequality-red.csv")
#xに説明変数
x = df.drop(columns='quality')
#yに目的変数
y = df['quality']
##アルゴリズム総当たり
#"classifier"タイプの全てのアルゴリズムを取得する。
allAlgorithms = all_estimators(type_filter = "classifier")
#K分割クロスバリデーション用オブジェクト。
#今回は5分割ですがここを変えると結果も変わります。
kfold_cv = KFold(n_splits = 5, shuffle = True)
#警告の無視
warnings.filterwarnings('ignore')
#全てのアルゴリズムで、5通りのデータの分け方で学習した場合の精度を出力。
for(name, algorithm) in allAlgorithms:
try:
clf = algorithm()
if hasattr(clf,"score"):
scores = cross_val_score(clf, x, y, cv = kfold_cv)
print(name, "の正解率")
print(scores)
#エラーを出したアルゴリズムは無視する。
except Exception:
passここで4行目に記述した
from sklearn.utils import all_estimators
にて、scikit-learn(ライブラリ)の全手法を使用する事を宣言し、allAlgorithms = all_estimators(type_filter = "classifier")というコードを使い、
総当たりを実行してみる事にします。
AdaBoostClassifier の正解率
[0.478125 0.5125 0.553125 0.578125 0.55485893]
BaggingClassifier の正解率
[0.653125 0.66875 0.646875 0.653125 0.66144201]
BernoulliNB の正解率
[0.3875 0.384375 0.446875 0.44375 0.43887147]
CalibratedClassifierCV の正解率
[0.59375 0.571875 0.5875 0.5875 0.55485893]
CategoricalNB の正解率
[ nan 0.5625 nan nan 0.5799373]
ComplementNB の正解率
[0.50625 0.4875 0.496875 0.44375 0.47962382]
DecisionTreeClassifier の正解率
[0.659375 0.615625 0.58125 0.546875 0.59247649]
DummyClassifier の正解率
[0.421875 0.421875 0.45 0.45625 0.37931034]
ExtraTreeClassifier の正解率
[0.55625 0.625 0.634375 0.59375 0.63636364]
ExtraTreesClassifier の正解率
[0.703125 0.696875 0.671875 0.715625 0.69592476]
GaussianNB の正解率
[0.53125 0.56875 0.503125 0.575 0.52978056]
GaussianProcessClassifier の正解率
[0.546875 0.575 0.590625 0.559375 0.57680251]
GradientBoostingClassifier の正解率
[0.665625 0.68125 0.65625 0.6625 0.65517241]
HistGradientBoostingClassifier の正解率
[0.678125 0.690625 0.6625 0.6625 0.67398119]
KNeighborsClassifier の正解率
[0.521875 0.44375 0.534375 0.54375 0.48589342]
LabelPropagation の正解率
[0.59375 0.5375 0.553125 0.625 0.5799373]
LabelSpreading の正解率
[0.578125 0.559375 0.590625 0.5875 0.52351097]
LinearDiscriminantAnalysis の正解率
[0.575 0.5875 0.628125 0.575 0.59874608]
LinearSVC の正解率
[0.515625 0.5625 0.540625 0.3875 0.40125392]
LogisticRegression の正解率
[0.578125 0.60625 0.540625 0.5875 0.60188088]
LogisticRegressionCV の正解率
[0.609375 0.5625 0.628125 0.546875 0.59874608]
MLPClassifier の正解率
[0.56875 0.55625 0.58125 0.56875 0.56739812]
MultinomialNB の正解率
[0.4375 0.421875 0.421875 0.446875 0.46081505]
NearestCentroid の正解率
[0.24375 0.2625 0.284375 0.296875 0.28840125]
NuSVC の正解率
[nan nan nan nan nan]
PassiveAggressiveClassifier の正解率
[0.509375 0.490625 0.56875 0.53125 0.2539185]
Perceptron の正解率
[0.31875 0.428125 0.396875 0.2625 0.52351097]
QuadraticDiscriminantAnalysis の正解率
[0.54375 0.584375 0.565625 0.55625 0.56426332]
RadiusNeighborsClassifier の正解率
[nan nan nan nan nan]
RandomForestClassifier の正解率
[0.665625 0.6875 0.68125 0.68125 0.72413793]
RidgeClassifier の正解率
[0.578125 0.571875 0.596875 0.603125 0.55799373]
RidgeClassifierCV の正解率
[0.58125 0.596875 0.5375 0.590625 0.56739812]
SGDClassifier の正解率
[0.53125 0.415625 0.146875 0.5375 0.09404389]
SVC の正解率
[0.5125 0.475 0.509375 0.521875 0.51410658]出力結果はこのようになりました!
1に近い手法はどれかなあ~と、確認してみると、
「RandomForestClassifier の正解率」が最も1に近い数値とわかりますね💡
目標を達成できる数値になっていますので、
これならいけるかも~!!!!と希望を持って、
RandomForestClassifierなる手法を試してみる事にします!
これは良さそう!RandomForestを試してみよう

ランダムフォレストとは、どういった手法なのでしょうか?
ランダムフォレストとは:
決定木をたくさん作って多数決する(または平均を取る)ような手法
…相変わらず、書いてみたものの良くわからない内容ですが、
どうやら回帰ではなく、クラス分類用の手法のようです💡
回帰で予測を行う予定でしたが、
ここからは分類問題に切り替えて予測を行っていきます。
それでは早速試していきましょう!
3つの手法を試した時と同様に、
ランダムフォレストのモジュールを追加し、実行してみます。
import pandas as pd
from sklearn.model_selection import train_test_split
# ランダムフォレストのモジュールを追加します
from sklearn.ensemble import RandomForestClassifier
#データの読み込み
df = pd.read_csv("/content/winequality-red.csv")
#xに説明変数
x = df.drop(columns='quality')
#yに目的変数
y = df['quality']
#学習データとテストデータに分割
train_X, test_X, train_y, test_y = train_test_split(x, y, test_size=0.2)
#ランダムフォレスト
model = RandomForestClassifier()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
print(score)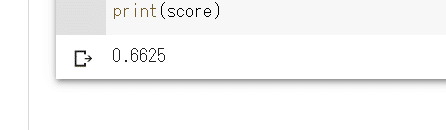
総当たりで試したように、目標範囲内の結果が出ました!
0.66となるため、目標②~③も達成できましたー-!!!!
という事で、本記事の目標は達成できましたが、
もっと精度を良くできないかな?と考えました。
精度を向上させる方法は、果たしてあるのでしょうか…?
検証のため、もう少しおかわりをやっていきたいと思います!
もう少し精度を高めたい…そんな時には

「もう最適な手法を見つけた事になっているし、これ以上やる事ないでしょ?」
たった1時間前の私は、そう考えていました…
しかし!
データを見直せば、もっと精度が上がるらしいという事を耳にしました。
とはいえ、どうやってデータを見直すのか?
そもそもデータのどこを見直すのか?という事ですが、
着目すべき点が、quality(目的変数)にあるようなのです。
qualityにはワインの品質を表す数値(4や5など)がありますが、
データ内に、どの数値が、いくつあるのかを確認する必要がありそうです。
品質は0~10の11段階で評価されているようですが、
内訳を確認していきましょう!
#出現頻度を数えるカウンターを設定します。
counter = [0]*11
#目的変数(quality)をyとします。
for i in y:
counter[i] += 1
#quality(i)が出現するとcounterのi番目に1を足します。
print(counter)
結果が出ました!
quality 0~3、9~10を見てみると、データが0件でした。
こういった出現頻度の少ないデータが含まれていると、
なんと、精度が落ちる原因になるようです…
0件以外のデータをグラフ分布させるとこんな感じです。
import matplotlib.pyplot as plt
count_data = df.groupby('quality')["quality"].count()
print(count_data)
count_data.plot()
plt.show()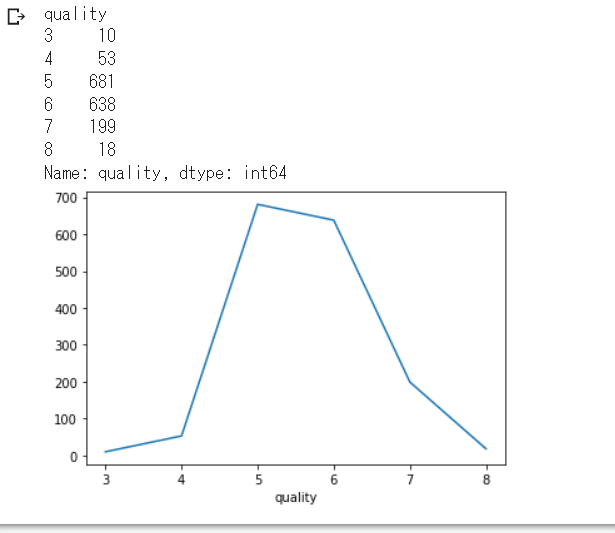
まずは精度向上の為、データが0件のものを整理していきましょう!
以下のコードを使って、評価を0~4(ふつう)、
5~7(おいしい)、8~10(とてもおいしい)の3段階に分けなおします。
new_label = []
for i in list(y):
if i <= 3:
new_label += [0]
elif i <= 7:
new_label += [1]
else:
new_label += [2]
y = new_labelqualityが3以下なら0、7以下なら1、
その他は2と分類する、というコードになります。
「RandomForestを試してみよう」で記述したコードに、
上記のコードを入れ込みます。
(目的変数設定の下に入れてみてくださいね)
import pandas as pd
from sklearn.model_selection import train_test_split
# 必要なモジュールを追記してください。
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestClassifier
#データの読み込み
df = pd.read_csv("/content/winequality-red.csv")
#xに説明変数
x = df.drop(columns='quality')
#yに目的変数
y = df['quality']
new_label = []
for i in list(y):
if i <= 3:
new_label += [0]
elif i <= 7:
new_label += [1]
else:
new_label += [2]
y = new_label
#学習データとテストデータに分割
train_X, test_X, train_y, test_y = train_test_split(x, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(train_X, train_y)
score = model.score(test_X, test_y)
print(score)これですべての処理が終わりました…!
このコードを実行してみると、結果はどうなるでしょうか?

0.98という高値が出ました!
つまり、98%予測に成功しているという事になります!
結果を予測するだけでなく、精度を向上させる事にも成功しました✨
おわりに

まともな結果を記事にすることができ、大変ほっとしています💦
取り組み始める前は、
「初心者なのに予測なんてできるのかな…」
「微妙な結果しか出なかったらどうしよう…」と考えていましたが、
様々な知識によるお力添えで、精度を98%まで上げる事に成功しました!
予測をし、最適な手法を探す方法を学べただけではなく、
データの見直しをするという事の重要性を理解する事ができました。
今回学んだ事を活かし、次なる目標の
プログラミング中級者を目指して頑張りたいと思います!
お読みいただいた方、
ここまでお付き合いいただき、ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?