続報1 厚労省データ処理の根本的な誤謬と、流氷原を漂流する巨大客船

はじめに
先日の記事「厚労省・新型コロナ陽性者データに内在する不可解な矛盾」は、思いもかけぬ大変な反響とサポートをいただき、ありがとうございました。特に、第一線の研究者の方々からは、非常な危機感を共有いただけるコメントをいただけたことを、非常に心強く思っています。
一方で、一部の方からは、ただの注釈にそこまで目くじらを立てなくても、といった類の批判をいただいていたことも事実です。
19日の検査実施人数累積のマイナスについて
さて、私が先の記事を書いていたのは19日ですが、その当日付けのデータで、今度はなんと「PCR検査実施人数」が累積でマイナスになるという事態が発生していたことをTwitterで教えていただきました。

厚労省の注釈によれば、この減少は「千葉県が人数でなく件数でカウントしていたことが判明したため、千葉県の件数を引いたことによる」ためです。
しかし、これこそ絶対にやってはいけない処理方法であることは、データの扱いに慣れている人なら自明のことです。なぜなら、このやり方では、過去についても現在についても、正しいデータが全くわからなくなるからです。
具体的に示します。グラフを取れば、こんなことになります。
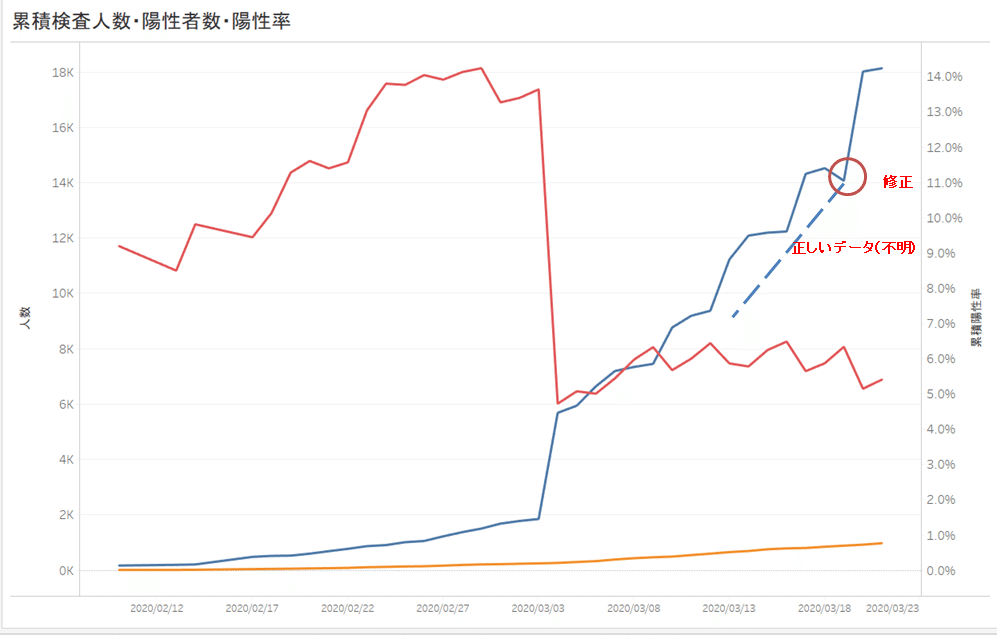
3月4日の検査数の急増と、それに伴う計算上の陽性率の急落については、ひとまず置いておきます。注目いただきたいのは、右の○印、累積人数のマイナスです。繰り返しますが、これは論理的にあり得ないことです。
ですが、この修正によって過去の日付の正しい時系列データが一切わからない状態になっています(点線部分)。感染症対策において、時系列データは最も重要なものの1つです。過去の履歴が正しいからこそ、そのときの増加傾向がわかり、感染状況が把握できるし、現在の封じ込め政策が成功しているのか否かも判断できるのです。
さらに。厚労省は基本的に「累積」のデータしか示していないという事実があります。ということは、その当日の検査数や陽性者数は、前日との差分で示されている訳です。それが、それぞれの数字の下についた括弧内の数字です。
ところが、厚労省は平気で、検査人数14,072人の下に、(-453)という論理的にあり得ない人数を書いてしまっている。つまり、「前日の誤った情報」と「本日の(たぶん)正しい情報」との差分をここに記しているのです。言い換えれば、この「-453」人の中に、データ修正による見かけ上の人数減と、当日にPCR検査をした人数とを混ぜて発表してしまっているということです。
そして厚労省は千葉県データの二重カウントが何件あったかを、公表していません。つまり、3月19日の検査人数は、まったくの闇の中なのです。
厚労省によるデータ処理の根本的誤謬
なぜこんなことが起きたのでしょうか。
それは厚労省が、「その都度、自分の手元にある最新の、より正しいと思われる累積情報」だけを、公開すれば良いと考えているからです。昨日の情報は間違ってたとしても、それはそのまま放置して、今日のなるたけ正しい(今のところ)情報を公開すれば良いと、甘く考えているのです。
しかし、正しいデータ運用としては、「データの誤りが見つかったら、過去に遡って修正」しなければならない。つまり、データの「バージョン管理」と「日次データ更新」は、完全に分けて考えないといけないのです。
しかしながら、厚労省は両者を完全に混同してしまっている。だから、過去も現在もまったくわからない、意味不明のデータが出来上がる。それが表われているのが、先のグラフの3月4日の検査数のジャンプです。東洋経済の「新型コロナウイルス 国内感染の状況」によれば、この時点から「これまでの疑似症サーベイランスに加えて濃厚接触者への検査も公表数に含められ」たことが原因です。しかし、過去データを遡って公表しないため、計算上の陽性率もまた見かけ上急落してしまっています。
これでは、感染状況についてまともな分析をしようがありませんし、まして、データに基づく政策判断などしようがありません。専門家も一般市民も依拠して分析している厚労省発表の情報は、「データ」と呼べる代物ではなく、ただの「日報」なのです。そして、それ以外に信頼できるデータがほとんど存在しないのが現状なのです。
以上のようなデータ処理の根本的な間違いが、先の記事で指摘した「外国人数の累積」でも表われていたのでしょうか?そうかもしれません。少なくとも、一部はそれで説明できる可能性があります。逆に言えば、先日指摘した「外国人累積」のマイナスは、厚生省データそのものの信頼性に関わる問題だったのです。
以上のことは、コロナウイルス対策における政府のデータ軽視・科学軽視の姿勢を同時に、国民への説明責任の放棄という姿勢をも示しています。
漆黒の流氷原を漂流する巨大客船
最後にもう1つだけ、ある恐ろしい可能性を指摘しておきます。
ここまで不可解なデータ処理を行っているのを見たデータ分析者なら誰でも、「元データを出せ」と言いたくなることでしょう。
検査者ベースの元データさえあれば、過去の正しい検査数の時系列データも、検査者属性ごとの陽性率の推移も、検査者における日本国籍/外国籍の偏りも、すべて簡単に割り出せるはずです。なにせ人数で言えば15000件程度のデータです。最悪、Excelファイル1つで済む程度のデータ量なのです(Excelの使用を推奨しているわけではありません)。
最低限の信頼できるデータベースが整っていないのに、実効再生産率などのより高度な分析にそもそも意味があるはずがないし、そこに国の命運をゆだねることは、素人のタロット占いで政策を決めるのと変わりありません。(私のあるフォロワーさんが、疫学調査ではなくて易学調査だと言っていたのは、言い得て妙だと感心しました)。
しかし、厚労省の公表する情報を見る限り、そもそも「元データ」なんか存在しないんじゃないか、という疑念をどうしてもぬぐいきれません。厚労省のデータの扱いの杜撰さと無理解を見る限り、すべての検査者と検査データを把握していて、その上でわざと子供だましのデータを公表している、とはちょっと思えないのです。
だとすれば、私たちは、羅針盤も地図もない漂流船に乗っているのと同じことになります。
漆黒の新月の夜、ひたすら酒宴の準備を続ける船長たちが支配する、流氷原を漂流する巨大客船。それが日本国の今なのかもしれません。