
ナレッジグラフ: 技術的概要とアプリケーション

ナレッジグラフとは何か?
ナレッジグラフは、現実世界のエンティティ(オブジェクト、イベント、状況、概念)とそれらの間の関係のネットワークです。コンピュータが理解できる形で知識を表現するデータのグラフと考えることができます。この情報は、グラフデータベースに保存され、グラフとして視覚化されることが多いです。ナレッジグラフは次のようなグラフ構造を使用します:
ノード: エンティティ(個人、場所、物体、アイデア)を表します。
エッジ: エンティティ間の接続または関連を表します。
この構造により、複雑なクエリの正確な解決が可能になります。関係を表現するために形式的なセマンティクスがよく使用され、これにより機械が理解できるようになります。特定のドメインのナレッジグラフは、そのスキーマを定義するためにオントロジーを使用することがよくあります。このオントロジーは、そのドメインのプロパティとそれらの相互関係を定義します。
以下のテキストを考えてみてください:
Mary had a little lamb, You’ve heard this tale before; But did you know she passed her plate, And had a little more! 日本語訳:メアリーさんは小さな子羊を飼っていました。この話を聞いたことがあるでしょう。でも、彼女が皿を渡して、もう少し食べたことをご存知でしたか?
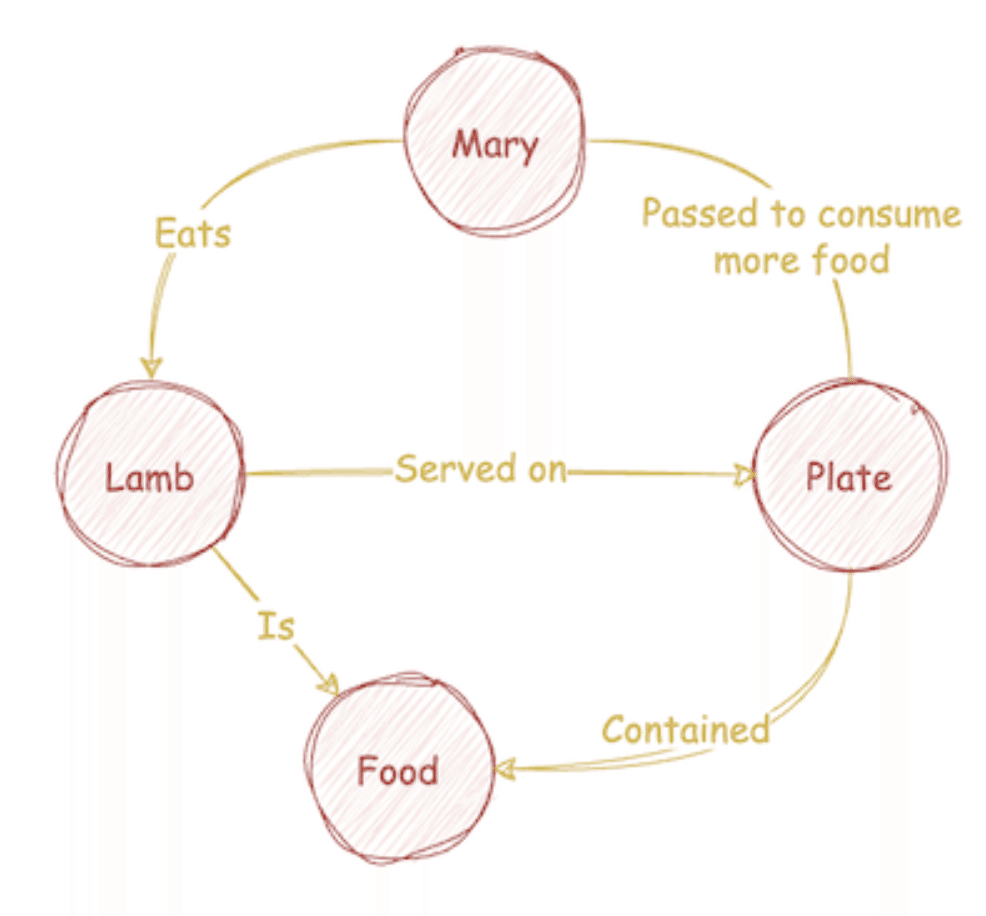
Towards Data Science “How to Convert Any Text Into a Graph of Concepts”より抜粋
ナレッジグラフによる推論と相互接続の強化
ナレッジグラフ(Knowledge Graphs, KGs)は、構造化された知識をグラフベースの形式で表現および活用することに優れており、ベクターデータベースや単純なテキストスニペットのような従来の方法の限界を超えています。ここでは、他の技術が苦手とするナレッジグラフの能力について説明します。
強化された推論と文脈化
KGsは「全データセット推論」を可能にします: 個別のスニペットだけでなく、データセット全体にわたる概念を結びつけます。
構造化されたエンティティと関係の表現: これにより、Retrieval-Augmented Generation (RAG) システムでのより正確で文脈に即した応答が可能になります。
医療分野の例: 病気、症状、治療、研究をリンクさせ、単なるキーワードマッチングを超えた包括的な回答を提供します。
マルチホップ推論と複雑なクエリ
複雑なクエリに対応: 複数のドキュメントにまたがるエンティティ間の関係を理解する必要がある場合に特に価値があります。
薬物と遺伝子の相互作用に関する例: ナレッジグラフはこれらのエンティティ間の関係をたどり、伝統的なRAGシステムが苦労するクエリにも効果的に対応します。
因果関係の解析や概念の進化の理解: これらのタスクにも重要です。
隠れた関係の発見と洞察の生成
知識を相互接続されたネットワークとして表現: 隠れた関係の発見と新しい洞察の生成が可能です。
関連する概念のコミュニティを特定: 影響力のあるノードを強調し、異なる分野間の未知の接続を明らかにします。
生物学的材料とベートーヴェンの交響曲第9番の構造的類似性の例: KGsの同型マッピングを通じて複雑さの共有パターンを強調します。
柔軟性と適応性
スケーラブルで相互運用可能な設計: 膨大な情報を収容し、既存のデータソースとの統合が可能です。
継続的な拡張と強化: 新しいデータの追加により、進化する知識と洞察を取り込むことができます。
しかし、ナレッジグラフの構築と効果的な利用には、データの特性、ビジネスニーズ、特定のタスクに対する慎重な考慮が必要です。特定のアプリケーションに対してはナレッジグラフは大きな利点を提供しますが、シンプルなシナリオや小規模であまり相互接続されていないデータセットに対しては過剰な場合もあります。
ナレッジグラフの作成プロセス
ナレッジグラフを作成するプロセスは一般的に次のステップを含みます:
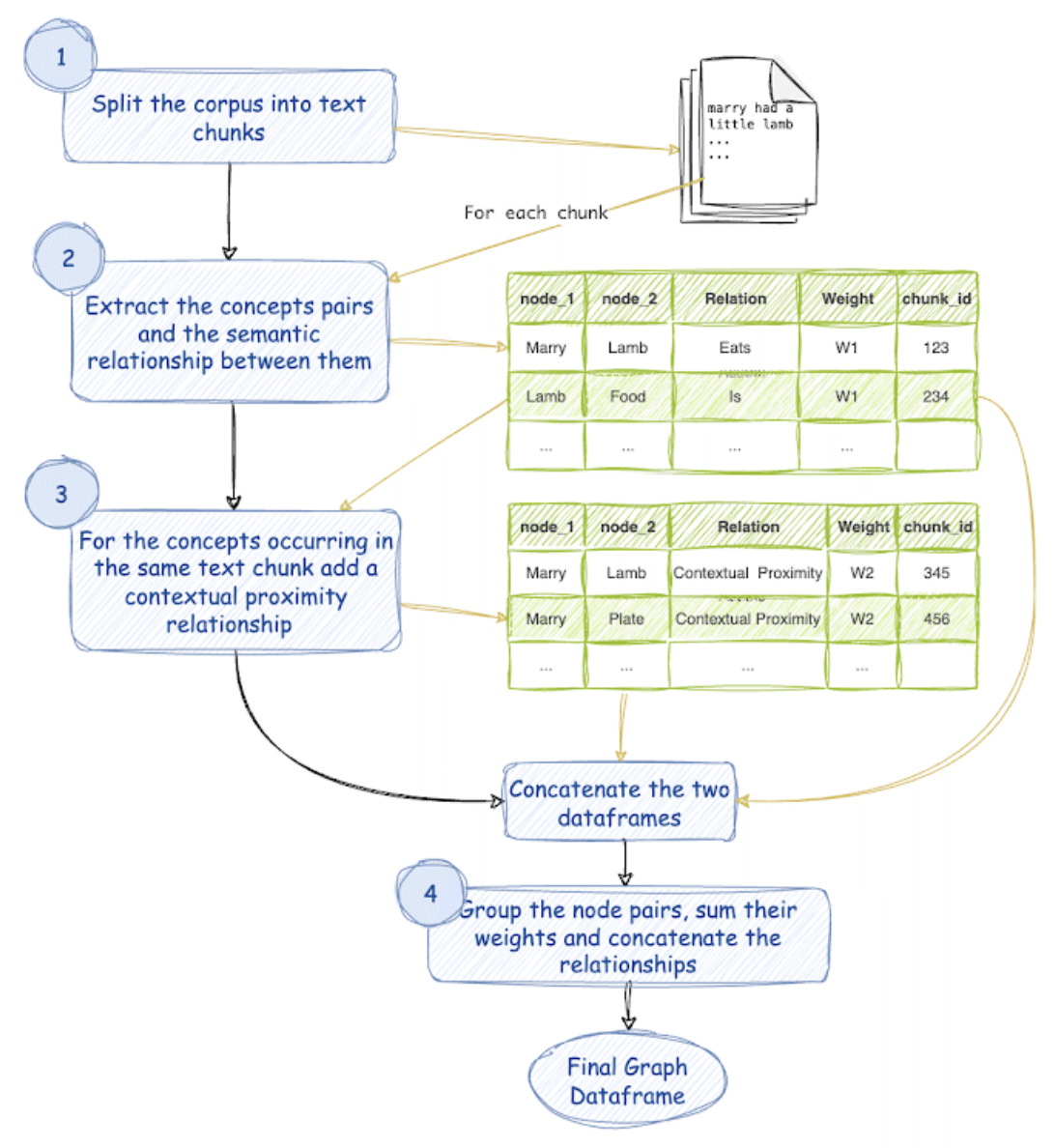
コンセプトとエンティティの抽出
キーコンセプトとエンティティの特定: テキストから主要な概念とエンティティを特定します。これらがグラフのノードとなります。
ノードの関係の抽出
抽出された概念とエンティティ間の関係の決定: これらがグラフのエッジを形成します。
データ入力
ノード(概念)とエッジ(関係)の入力: 適切なグラフデータ構造やグラフデータベース(例:PythonのNetworkX)に入力します。
データの可視化
グラフの可視化: 概念とエンティティ間の関係を明確かつ直感的に理解するためにグラフを可視化します。
ナレッジグラフのアプリケーション
AIシステム
レコメンデーション システム
ナレッジグラフは、ユーザーの好みやアイテムの特性を理解することでレコメンデーションを改善します。例えば、ナレッジグラフはユーザー、映画、監督、俳優、ジャンルに基づいて映画を推薦することができます。ナレッジグラフベースのレコメンダシステムには次のものがあります:
KPRN (Knowledge-aware Path Recurrent Network)
ナレッジグラフのパスを活用して、ユーザーとアイテムの相互作用の洞察を向上させます。シーケンシャルな依存関係をモデル化し、新しい重み付けプーリング操作を通じて説明性を提供し、最先端の方法を上回るパフォーマンスを発揮します。
MKR (Multi-task feature learning approach for Knowledge graph enhanced Recommendation)
ユーザーとアイテムの相互作用に基づいてナレッジグラフをモデル化し、潜在的なユーザーとアイテムの相互作用を学習します。MKRはナレッジグラフの構造情報に焦点を当て、より正確なレコメンデーションを行います。
MKGAT (Multi-modal Knowledge Graph Attention Network)
2つの側面に基づいてナレッジグラフを構築します:隣接エンティティの情報を抽出してエンティティ情報を豊かにし、トリプレットをスコアリングして推論関係を構築します。MKGATは、構造化データで豊かにしたナレッジグラフを使用してレコメンダシステムにおいてより正確なレコメンデーションを実現します。
質問応答システム(チャットボット、等)
ナレッジグラフを活用して、マルチホップ推論を通じて情報を結合し、正確で複雑な回答を提供します。
情報検索
エンティティ関係を分析して検索エンジンの正確性と説明性を向上させ、クエリとドキュメントの関連性を高めます。
技術的課題
ナレッジグラフ埋め込み
ナレッジグラフのエンティティと関係を低次元のベクトル空間で表現する方法ですが、既存の方法には次のような限界があります:
追加情報の無視: 多くの方法はナレッジグラフ内の表面的な事実(トリプレット)のみを考慮し、エンティティタイプや関係パスなどの情報を無視しているため、パフォーマンスが不十分です。一部の研究者は追加情報を取り入れていますが、この情報を効果的に活用して埋め込み精度を向上させることは依然として課題です。
スケーラビリティの問題: ナレッジグラフが大きくなるにつれて、特に追加情報を取り入れる埋め込みモデルは、増大する複雑性と計算需要に対応するのが難しくなります。
ナレッジ取得
ナレッジグラフをモデル化および構築する方法に焦点を当てたこの方法は、いくつかの限界があります:
低い精度: これにより、不完全またはノイズの多いナレッジグラフが生成され、下流のタスクに支障をきたします。ナレッジ取得ツールの信頼性を確保することが重要な課題です。
ドメイン固有のナレッジグラフ生成の難しさ: 生データからエンティティとプロパティを抽出してドメイン固有のナレッジグラフを生成することは効率的ではありません。ドメイン固有のスキーマは知識指向である一方、構築されたスキーマはデータ指向です。
マルチモーダルナレッジグラフ構築の課題: 既存のナレッジグラフは主にテキスト情報によって表現されています。画像、ビデオ、音声など他のモダリティをナレッジグラフに統合することは依然として大きな課題です。
ナレッジグラフの補完
既存のナレッジグラフを拡張して新しいトリプレットやエンティティを予測および追加することに焦点を当てています。現在の方法には次の限界があります:
クローズドワールド仮定への依存: 多くの方法は既に存在するエンティティと関係を用いて新しいトリプレットを予測するのみです。オープンワールド技術が出現していますが、外部データソースの複雑さとノイズのために精度が低いです。
静的ナレッジグラフ仮定: 既存の方法は時間とともに変化するナレッジグラフの動的な進化を捉えていません。時系列ナレッジグラフ補完方法が出現していますが、時間的ダイナミクスを捉えるためにタイムスタンプを効果的に組み込むことは依然として課題です。
ナレッジフュージョン
異なるソースからの知識を統合することに焦点を当て、しばしばエンティティのアライメントを通じて行います。課題には次のものがあります:
データの複雑性、多様性、量: 多様で膨大なデータソースからエンティティを正確にアラインし、知識をフュージョンすることは依然として大きな障害です。
ナレッジ推論
ナレッジグラフ内の既存の事実から新しい知識を推論することに焦点を当てています。既存の方法には次の限界があります:
大規模ナレッジグラフにおける未踏のマルチホップ推論: 既存のモデルは主に比較的小規模なナレッジグラフでのマルチホップ推論に焦点を当てており、数百万のエンティティを持つ大規模ナレッジグラフの規模と複雑さに対応するのは困難です。
マルチホップ推論の計算コスト: マルチホップ推論で複数の関係やエンティティをたどることは計算コストが指数関数的に増加し、効率的に探索および実装することが難しくなります。
推論された知識の検証: 推論された知識は不確実であり、新しいトリプレットの真実性を検証し、既存の知識との衝突を検出する必要があります。マルチソースナレッジ推論が出現していますが、さらなる研究が必要です。
ナレッジグラフとRetrieval-Augmented Generation(RAG)
ナレッジグラフをRetrieval-Augmented Generation(RAG)システムと組み合わせることは、AIにとって画期的です。これにより、大規模言語モデル(LLM)の精度、文脈理解、推論能力が向上します。ナレッジグラフはデータを相互に接続されたエンティティと関係として構造化し、生成された応答の正確性と文脈的な関連性を確保するフレームワークを提供します。この統合は、生成AIの企業導入において、特に情報検索を伴うタスクでモデルの出力精度と幻覚に対する懸念を解決するために重要です。
ナレッジグラフとRAGの組み合わせの主な利点
データ検索の向上
文脈理解: 従来のキーワードマッチングに頼るRAGシステムとは異なり、ナレッジグラフを統合することで、ユーザーのクエリの文脈をエンティティと概念の関係を活用して理解できます。これにより、より関連性の高い情報を検索できます。
マルチホップ推論: ナレッジグラフはマルチホップ推論を可能にします。これは、システムがグラフ内の複数の関係をナビゲートし、初期クエリに直接関連していない回答を見つけるプロセスです。これは、さまざまな情報源から情報を統合する必要がある複雑なクエリに特に有用です。
効率的な情報統合: ナレッジグラフは集計メトリクスや因果関係を事前計算および保存するため、RAGシステムはこの情報を効率的に取得できます。たとえば、広範なテキストデータを分析する代わりに、質問応答のRAGシステムはナレッジグラフ内の関連するプロパティとセマンティクスを持つエンティティに集中でき、効率が向上します。
推論の強化と幻覚(ハルシネーション)の減少
LLMsのための構造化知識: LLMsはトレーニングデータの限界により、不正確な情報を生成する「幻覚」に苦しむことがあります。ナレッジグラフは、現実のエンティティと関係に関する構造化された事実データを提供することで、これらの幻覚の可能性を減らし、LLMの出力の信頼性と信頼性を向上させます。
説明可能なAI: ナレッジグラフは、RAGシステムの推論プロセスをより透明にします。グラフ構造は、システムが回答に至るまでに使用した接続と経路を明確に示します。この説明可能性は、ヘルスケアや金融などの重要な領域でAIシステムに対する信頼を構築するために重要です。
適応性と動的学習
複雑な情報アーキテクチャの処理: ナレッジグラフは、複雑な基礎構造を持つ複数の情報源にまたがる情報を扱う場合に特に有益です。たとえば、法的研究において、ナレッジグラフは法律のケース、法令、判例をリンクさせ、正確かつ効率的な法情報の検索を促進します。この相互接続された構造は、推論を強化し、従来のドキュメントベースのRAGシステムよりも包括的な分析を可能にします。
継続的な更新: ナレッジグラフは動的であり、新しいデータが利用可能になると常に進化します。これにより、RAGシステムは最新の情報を維持でき、急速に変化する分野で重要です。
企業におけるナレッジグラフRAGシステム
ナレッジグラフが特に価値を持つシナリオ:
概念の集約: 複数のドキュメントやデータソースから情報を統合して完全な理解を形成する必要がある場合、ナレッジグラフは不可欠です。たとえば、ベンチャーキャピタルファンドは、ナレッジグラフを使用して人物、産業、ファンドをニュース記事などの外部データソースと結びつけることができます。
ドメイン固有の専門知識: 企業は、競争優位性を維持するための戦略的資産としてナレッジグラフをますます認識しています。特定の業界内で独自の知識とデータを構造化することで、企業はRAGシステムを活用してこの情報をより効果的に利用、操作、相互作用することができます。
ナレッジグラフ+RAGの導入例
医療
ナレッジグラフは、病気、症状、治療法、および研究を結びつけることができます。これにより、医療従事者や患者は質問に対してより詳細な回答を得ることができます。たとえば、アルツハイマー病に関する問い合わせでは、新しい薬、臨床試験、および専門家の意見に関する情報を提供できます。
法律サービス
ナレッジグラフは、法的ケース、法令、判例、および法理を結びつけ、法律アプリケーションに役立ちます。RAGシステムは、現行法と関連する判例を使用して正確な法的助言を取得および生成することができ、法的研究や意思決定を支援します。
カスタマーサポート
ナレッジグラフは、製品の機能、トラブルシューティング情報、および顧客ポリシーを結びつけ、カスタマーサポートに役立ちます。RAGシステムは、顧客の質問に対して正確かつ具体的な回答を提供し、カスタマーサービスの質と効率を向上させます。たとえば、テクノロジー企業のカスタマーサービスシナリオで、顧客が「充電の問題」について尋ねた場合、RAGシステムはナレッジグラフを使用して、デバイスモデルと顧客の履歴に基づいてハードウェアまたはソフトウェアの問題かどうかを判断します。
教育サービス
ナレッジグラフは、概念、歴史的イベント、科学理論、および伝記情報を結びつけることができます。これにより、学生や教育者は質問に対して包括的かつ正確な説明と学習資料にアクセスできます。
この記事が気に入ったらサポートをしてみませんか?