Data Lakehouse 対 Data Warehouse 対 Data Lake - 進化し続けるデータプラットホームの比較 | by Mariusz Kujawski | Jul, 2023 | Medium誌掲載記事

Clip source: Data Lakehouse vs Data Warehouse vs Data Lake - Comparison of data platforms | by Mariusz Kujawski | Jul, 2023 | Medium
データウェアハウス(DW, DWH):
構造化されたビジネスデータを一元管理する場所で、BIツールやアドホッククエリによってデータが消費さえる。(Azure Synapse、Redshift、BigQuery、Snowflakeなど)
データレイク:
Apache HadoopやHDFSを基盤とした、多様なフォーマットのデータを格納する場所で、Apache HiveやApache Sparkなどのツールでデータを分析
データレイクハウス:
Databricksが提案する新しい形態で、データウェアハウスとデータレイクの長所を組み合わせたもの
Data Lakehouse 対 Data Warehouse 対 Data Lake - データプラットホームの比較
Mariusz Kujawski
Jul 24

数十年にわたり、データウェアハウスは企業でデータプラットフォームを構築するための主要なアーキテクチャ手法でした。しかし、クラウド、ビッグデータ、Hadoopなどの技術の登場により、現代のデータプラットフォームの進化が加速しており、データレイクやデータレイクハウスなど、さまざまな選択肢が出現しています。
主要なクラウドプロバイダーによって発表された記事によれば、データレイクハウスは新世代のデータプラットフォームを代表しています。しかし、すべてのデータプラットフォームアーキテクトが自問すべきことは、データレイクハウスが特定のユースケースに最適なアーキテクチャなのか、それともデータレイクやデータウェアハウスを選ぶべきなのかという点です。
この投稿では、これらのアーキテクチャ間の違いを探り、どのシナリオでどれが最も効果的であるかを分析します。
Data Warehouse
データウェアハウスアーキテクチャ(DW、DWH)、別名エンタープライズデータウェアハウス(EDW)は、数十年にわたって主要なアーキテクチャ手法とされています。データウェアハウスは、構造化されたビジネスデータの中央リポジトリとして機能し、組織が貴重な洞察を得ることを可能にします。データをウェアハウスに書き込む前にスキーマを定義することが重要です。通常、データウェアハウスはバッチ処理を通じてデータが格納され、BIツールやアドホッククエリによってデータが消費されます。データウェアハウスの設計は、BIクエリの処理に特化していますが、非構造化データは処理できません。テーブル、制約、キー、インデックスなどがあり、データの一貫性をサポートし、分析クエリのパフォーマンスを向上させます。テーブルは、さらにパフォーマンスと有用性を向上させるために、次元テーブルと事実テーブルに分けられることがよくあります。
データウェアハウスの一般的な設計には、ステージングエリアが組み込まれています。このエリアでは、Informatica PowerCenter、SSIS、Data Stage、TalendなどのETLツールを使用して、さまざまなソースから生データが抽出されます。抽出されたデータは、ETLツールまたはSQL文を使用してデータウェアハウス内のデータモデルに変換されます。データウェアハウスを設計するためのいくつかのアーキテクチャ手法があり、これにはInmon、Kimball、Data Vaultの方法論が含まれます。
Data Warehouse design patterns
さて、いくつかの異なるデータウェアハウスの実装パターンを調査してみましょう。データウェアハウスを設計するためのいくつかのアーキテクチャ手法があります。この記事では、これらのアーキテクチャについて簡単に概説します。

エンタープライズデータウェアハウスの文脈では、複数の部門が独自のレポーティング要件を持っている場合、データマートの実装が必要になります。データマートとは、特定のビジネスドメインまたは部門のユニークなニーズに供給するために特別に最適化されたデータモデルです。例えば、マーケティング部門のレポーティングニーズは、会計部門のそれと大きく異なるでしょう。

もう1つの重要なデータプラットフォームのコンポーネントは、Operation Data Storage(運用データストレージ)であり、これはトランザクションシステムからの最新のデータを保存するために特別に設計されています。その主な違いは、履歴データが存在しない点にあります。Operation Data Storageは、ソースシステムからのデータの頻繁なインポートを容易にすることを目的としています。

Modern Data Warehouse
現代のデータプラットフォームにおいて、従来のデータウェアハウスは必要なのでしょうか?答えは「状況次第」です。例えば、銀行や保険会社のように規制報告やBIツールの利用が重要なプラットフォームを開発している場合、データウェアハウスは最適なアプローチとなります。これにより、特定の目的に対してデータが構造化、準備、最適化されることが確保されます。
Azure Synapse、Redshift、BigQuery、Snowflakeといったテクノロジーは、データウェアハウスとして利用できる標準的なデータモデルの作成を可能にします。Power BI、Tableau、Qlikなどの人気のあるBIツールとの統合により、必要なレポートを生成したり、XLSX、XML、JSONファイルなどの形式でデータを抽出することができます。また、DBT(Data Build Tool)やGCP Dataformフレームワークなどのツールを活用して、組織のレポーティング要件に対応するETLプロセスを確立することができます。
ただし、TensorFlow、PyTorch、XGBoost、scikit-learnなどの一般的な機械学習システムは、データウェアハウスとシームレスに統合されていない点に注意が必要です。さらに、既存のデータモデル内で実装されていない可能性のあるデータを分析する必要がしばしばあります。
Two-tier Data Warehouse: Pros and Cons

利点:
- データは構造化、モデリング、クリーニング、および準備がされています。
- データへのアクセスが容易です。
- 報告目的に最適化されています。
- 列および行レベルのセキュリティ、データマスキングがあります。
- ACIDトランザクションがサポートされています。
欠点:
- データモデルとETLプロセスの実装に変更を加える際の複雑さと時間がかかります。
- スキーマを定義する必要があります。
- プラットフォームのコスト(データベースプロバイダーとタイプに依存します)。
- データベースベンダー依存性(例えば、OracleからSQL Serverへの移行が複雑です)。
Data Lake History
新世代の登場により、生のデータを収集する習慣が生まれました。これは、例えば、データレイクモデルで使用されています。データレイクは、Apache Hadoop(2006年)とそのHadoop Distributed File System(HDFS)を基盤に、低コストのストレージとファイルAPIを活用しています。データは、効率的な圧縮率とクエリ性能で知られるオープンファイル形式(AvroやParquetなど)で保存されています。データレイクは、スキーマオンリードのアプローチを通じて柔軟性を提供しています。
新たなHadoopとMapReduceの技術の導入は、大量のデータを分析するためのコスト効果的なソリューションを提供しました。しかし、BIツールを使用して分析するために、データウェアハウスにデータのサブセットをロードするという代替オプションも存在しました。オープンソース形式の使用により、データレイクは機械学習やAIを含む幅広い分析ツールにアクセス可能になりました。それでも、データ品質、データガバナンス、データアナリストのMapReduceジョブの複雑さといった新たな課題が生じました。これらの課題に対処するために、Apache Hive(2010年)が導入され、データへのSQLアクセスを提供しました。ビッグデータプラットフォームとデータレイクのオープンソース性は、多数のツールの開発を促進しました。このプラットフォームは柔軟性を提供していましたが、使用されるツールの多様性によって複雑性も導入されました。その結果、「ポケモンかBingデータか?」というクイズがここで見つかり、プラットフォームに関する知識をテストすることができます。
データレイクの次のステージは、S3、ADLS、GCSなどのクラウド環境とデータストアの導入によって訪れました。これらは徐々にHDFSを置き換えました。これらの新しいデータストアはサーバーレスであり、アーカイブなどの追加機能とともにコストメリットを提供しました。クラウドプロバイダーは、Redshift(2012年)、Azure Data Warehouse、BigQuery(2011年)、Snowflake(2014年)を含む新しいタイプのデータウェアハウスを導入しました。これにより、データレイクとデータウェアハウスを組み合わせた2層アーキテクチャの実装が容易になりました。もう一つの重要な進展はApache Sparkであり、大規模なデータ処理を可能にし、Python、SQL、Scalaなどの人気のあるプログラミング言語をサポートしています。
Data Lake Architectures
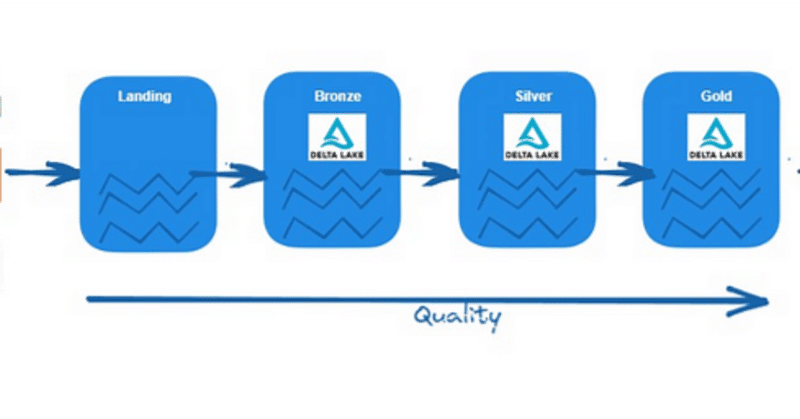
メダリオンアーキテクチャ
データレイク設計にはいくつかのパターンがありますが、現在最も人気のあるのはメダリオンアーキテクチャです。このアーキテクチャでは、ブロンズ層がソースからの生データを取り込み、それをParquetなどの共通データ形式でシルバー層に変換して保存します。最終的に、データは集約され、ゴールデン層に保存されます。

ブロンズ/ロウゾーン:
この層では、データは元の形式(JSON、CSV、XMLなど)で保存されます。ここでのデータは不変であり、読み取り専用のファイルとなっています。ファイルはソースシステムごとのフォルダに整理されるべきです。この層へのユーザーアクセスは制限する必要があります。
シルバー/クレンズドゾーン:
この層では、データが豊富になり、クリーンアップされ、Parquet、Avro、Delta(これらの形式は良好な圧縮比と読み取り性能を提供する)などの共通形式に変換されます。ここでデータを検証、標準化、調和させることができます。また、データ型とスキーマも定義されています。この層はデータサイエンティストやその他のユーザーにアクセス可能です。
ゴールド/キュレーションゾーン:
これは消費層であり、データ取り込みやデータ処理よりも分析に最適化されています。ここでのデータは集約されるか、次元データモデルで整理されます。このデータに対してSparkを使用してクエリを実行するか、データ仮想化を行うことができます。この場合、パフォーマンスが問題になる可能性があります。また、ダッシュボードでユーザーエクスペリエンスを向上させるために、BIツールにデータをインポートすることもできます。
Evolution of Data Lake merges with Data Warehouse as a two-tier architecture
メダリオンアーキテクチャの代わりに、上で触れた二層式データウェアハウスをさらに詳しく探ってみましょう。このアプローチでは、データレイク内のブロンズとシルバーにデータを保存した後、分析目的でデータウェアハウスにデータをロードします。データのロードには、Bulk loadsコマンドや外部テーブルを使用できます。BigQuery、Redshift、Snowflake、Synapseなどは、この機能を持っており、データレイクのファイルからデータを読み取り、ELTプロセスによって変換します。特にParquetファイルを使用すると、スキーマが定義されており、読み取り性能も高いため、統合が向上します。

アーカイブゾーン:データストレージのコストを削減するために、別のバケットでアーカイブ層を作成することもできます(ストレージのタイプを変更してコストを削減できます)。

プロダクト/ラボゾーン:この層は、データエンジニアやアナリストが独自の構造や計算を構築するためのサポートを提供します。分析やML/AIの目的で使用されます。

センシティブゾーン:このデザインは、データレイク内で機密データを扱う必要がある場合に使用されます。通常、この層には特定のユーザーのみがアクセスでき、データレイクの他の部分よりもアクセスが制限されています。
このように、二層式データウェアハウスは、データの柔軟性とコスト効率を最適化する多くのオプションを提供します。特に、Cloudプロバイダが提供するさまざまなストレージタイプを活用することで、データのアーカイブ化のコストを最適化する良い方法となります。

Folders organization in Data Lake
データスワンプ(データが管理されずに混乱する状態)を防ぐためには、データレイク内でシンプルかつ自己説明的なフォルダ構造を確立することが不可欠です。適切な階層構造を実装し、フォルダが人間が読みやすく、容易に理解できるようにすることが重要です。また、データレイクの開発プロセスを開始する前に、命名規則を明確に定義することも必要です。
フォルダ構造の簡潔性:これにより、データレイクの適切な利用が容易になり、アクセス管理にも役立ちます。
クエリエンジンの理解:フォルダ構造をどのように構築するかを理解することで、クエリエンジンがデータをより効率的に解釈できます。
ブロンズとシルバー層のデータ整理:推奨されるアプローチは、ブロンズ層とシルバー層で示されているように、データを整理することです。
このような戦略を採ることで、データレイクが効率的に運用され、データスワンプのリスクが軽減されます。特に、命名規則やフォルダ構造の明確な定義は、データ管理の基本となります。

この階層構造を実装することで、クエリエンジンのためのパーティション化されたデータを効果的に管理します。データを構造化された階層で整理することにより、クエリエンジンは特定のパーティションに効率よくナビゲートし、アクセスすることができ、これによりパフォーマンスが最適化され、データ取得能力が向上します。

特定のテーブルに対してフルロード戦略を採用する場合、パーティションを設定せずにフォルダ構造を作成することが可能です。テーブル全体がそのままロードされるようなケースでは、データが特定の基準に基づいてセグメント化されていないため、パーティションは必要ないかもしれません。代わりに、シンプルなフォルダ構造を確立して、完全なデータセットを整理および保存することができます。

ゴールドレイヤーを考慮する際には、ドメイン指向の構造を確立することが有益です。このアプローチは、アクセス管理を容易にするだけでなく、データレイクの利用を高めます。データをドメイン固有のカテゴリー、たとえば顧客、製品、または販売などに整理することで、ユーザーは特定のビジネスニーズに対応する関連データを簡単にナビゲートし活用することができます。
Lakehouses(レイクハウス)に向けた取り組み
初めて「Lakehouse」という用語に出会ったとき、私は従来のデータレイクアプローチとの違いが何かを疑問に思いました。当時、AWSはAthenaやRedshiftの外部テーブル、Glueカタログなどの機能を導入し、さまざまなAWSサービス間でのメタデータ共有をスムーズにしました。この開発により、ゴールドレイヤー内でデータモデルを作成し、データウェアハウスで見られるようなクエリ機能を提供することが可能になりました。Spark SQL、Presto、Hive、および主要なプロバイダーによって実装されたExternal TablesなどのSQLエンジンの利用可能性により、データレイクのクエリが容易になりました。ただし、データ管理、トランザクションのACIDサポート、インデックスを通じた効率的なパフォーマンスを実現するといった分野での課題は依然として存在しています。
データ・レイクハウス
Databricksによって実装されたデータ・レイクハウスアーキテクチャは、データレイクの第二世代を代表し、データレイクとデータウェアハウスの両方の強みを組み合わせた独自のデータプラットフォーム設計手法を提供します。これは、データウェアハウスとデータレイクの両方を収容する単一の統合プラットフォームとして機能します。データ・レイクハウスアーキテクチャは、従来のデータウェアハウスのようにACIDトランザクションをサポートするだけでなく、データレイクで見られるストレージのコスト効率とスケーラビリティも提供します。このアーキテクチャは、データレイクのすべてのレイヤーへの直接アクセスを可能にし、効果的なデータガバナンスのためのスキーマサポートを含みます。さらに、データ・レイクハウスは、パフォーマンスと機能を向上させるために、インデックス、データキャッシング、タイムトラベルなどの機能を導入しています。構造化されたデータと非構造化データの両方を引き続きサポートし、データはファイル形式で保存されます。
レイクハウスアーキテクチャを実装するために、DatabricksはDeltaと呼ばれる新しいタイプのファイル形式を開発しました(この投稿の後半でファイル形式の詳細について説明します)。Deltaの代わりとして、IcebergやApache Hudiなどの他のファイル形式も利用でき、同様の機能を提供します。これらの新しいファイル形式は、Sparkがデータロード戦略を改善する新しいデータ操作コマンドを活用できるようにします。データ・レイクハウスでは、テーブル内の行を更新する際に、データセット全体をテーブルに再ロードする必要がありません。

データ・レイクハウス・アーキテクチャ
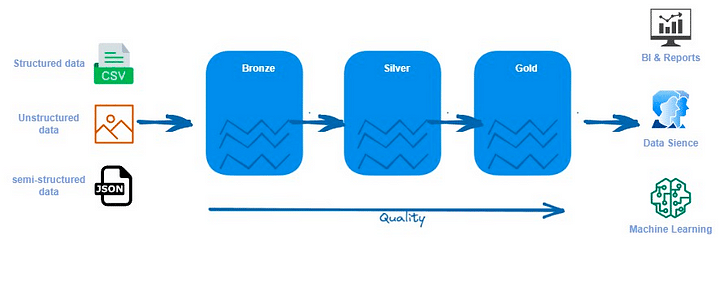
データ・レイクハウスは、主にメダリオン・アーキテクチャを使用してデータを整理します。前述したように、データ・レイクハウスにはブロンズ、シルバー、ゴールドの3つのレイヤーがあります。データ・レイクハウスの場合の主な違いは、ファイル形式です。データの保存にはDelta形式を使用します。Databricks以外のツールで作業する場合、主要なデータ形式としてIcebergまたはHundiを使用することもできます。以下で説明するいくつかの方法で、レイクハウス内のデータを整理することができます。
ブロンズレイヤー
ソースから「そのままの状態」でデータを取り込むために使用します。データはソースシステムに整列しており、ストレージ内で整理されています。ソースからデータをインポートする場合、Delta形式で保存します。データは、取り込みツールによって取り込まれ、ネイティブ形式で保存される場合もあります。これは、Deltaをサポートしていない場合や、ソースシステムがデータを直接ストレージにダンプする場合に該当します。
シルバーレイヤー
クリーン化、統一、検証、参照データまたはマスターデータで豊富なデータを保持します。好ましい形式はDeltaです。テーブルは依然としてソースシステムに対応しています。このレイヤーは、データサイエンス、アドホックレポート、高度な分析、およびMLによって消費されることがあります。
ゴールドレイヤー
ビジネスユーザー、BIツール、レポートによって利用されるデータモデルをホストします。Delta形式を使用します。このレイヤーには、計算と豊富なビジネスロジックが含まれています。シルバーから特定のデータセットのみを持つことも、集計データのみを持つこともあります。このレイヤーのテーブルの構造は、主題指向です。
データ・ヴォールトとレイクハウス
レイクハウスを整理する別のアプローチは、データ・ヴォールトの手法を活用することです。この方法は、大量のデータ、複数のデータソース、頻繁な統合変更に対処する組織に特に適しています。データ・ヴォールトのパターンは似ていますが、データモデリングと組織に重要な変更が含まれています。
データモデリング:
データ・ヴォールトでは、データはハブ、リンク、サテライトといった特定のコンポーネントに分割されます。これにより、データの柔軟性とスケーラビリティが向上します。
組織の変更:
データ・ヴォールトを使用すると、データの組織とアクセスが容易になります。特に、多くのデータソースと頻繁な統合変更がある場合、この方法は効率的です。
このように、データ・ヴォールトとレイクハウスを組み合わせることで、より柔軟でスケーラブルなデータプラットフォームを構築することが可能です。特に、大規模なデータと複雑な統合要件を持つ組織にとっては、このアプローチが有用である可能性が高いです。

ブロンズレイヤー
ソースシステムからのデータをそのままの構造で取り込む責任があります。追加のメタデータ列、たとえばロード時間やバッチIDなどを追加できます。このレイヤーは、履歴データ、デルタロード、および変更データキャプチャを保存します。ソースシステムからデータをインポートする場合、パフォーマンスを向上させるためにDelta形式で保存することが望ましいです。データが異なる形式で到着する場合、ランディングおよびステージゾーンを実装するか、追加のランディングレイヤーを設けることで、ソースシステムからのデータ受信を容易にできます。このようなシナリオでは、データはそのネイティブ形式で保存され、その後ブロンズ/ステージゾーンでDelta形式に変換されます。Databricks AutoLoaderツールは、ブロンズ/ステージゾーンでの変換プロセスを効率化するために使用できます。
シルバーレイヤー
しばしばエンタープライズリポジトリと呼ばれ、ブロンズレイヤーからのクリーニング、マージ、および変換されたデータを格納します。このデータは、ユーザーによって即座に消費され、レポート、高度な分析、およびMLプロセスをサポートします。データモデリングの観点から、このレイヤーは第3正規形を採用し、データヴォールトの原則を活用して、敏捷な開発と急速な変化に適応します。データヴォールトモデルには通常、3種類のエンティティが含まれます:
ハブは、顧客、製品、注文などのコアビジネスエンティティを表します。アナリストは、ハブに関する情報を取得するために自然/ビジネスキーを使用します。ハブテーブルの主キーは通常、ビジネスコンセプトID、ロード日、およびHash、MD5、およびSHA関数を使用して達成できる他のメタデータ情報の組み合わせによって派生します。
リンクは、ハブエンティティ間の関係を表します。それはジョインキーのみを持っています。これは、次元モデルのFactless Factテーブルのようなものです。属性の欠如 - ジョインキーのみ。
サテライトテーブルには、ハブまたはリンクのエンティティの属性があります。彼らはコアビジネスエンティティに関する記述情報を持っています。たとえば、製品ハブには、タイプ属性、コストなどの多くのサテライトテーブルがあります。
テーブルは、顧客、製品、または販売などのドメインに基づいて整理されます。
ゴールドレイヤー
データウェアハウスモデルまたはデータマートの基盤として機能します。Kimballの方法論などの次元モデリングのアプローチに従い、このレイヤーはレポーティング目的に焦点を当てます。ユーザーは、このレイヤーからデータを消費するためにBIツールを活用するか、アドホックレポーティングを実行できます。ゴールドレイヤー内には、異なる部門の特定のデータモデリングニーズに対応するためのデータマートも設立できます。プロジェクトまたはユースケース、たとえばC360、マーケティング、または販売などによってデータを整理することで、スタースキーマ構造を使用してデータ消費が容易になります。
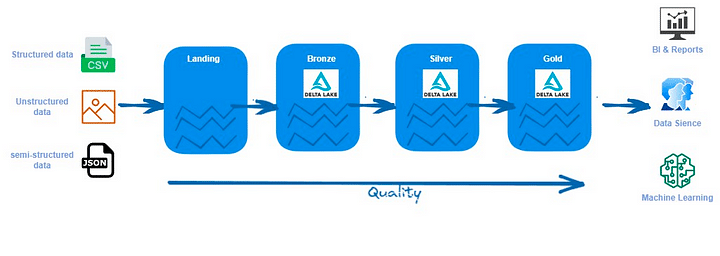
データの一時的な受け皿として機能する補足的なレイヤー: Landing Layerをもつレイクハウス
レイクハウスファイルフォーマット
Delta
信頼性と高性能なデータ処理を提供することを目的とした、Databricksによって導入されたオープンソースのデータストレージ形式です。ACIDトランザクション機能、バージョニング、スキーマ進化、効率的なデータ取り込みとクエリ操作を提供します。Deltaは一般的にApache Spark環境で使用され、バッチとストリーミングの両方のデータワークロードをサポートしています。データの圧縮、データのスキップ、タイムトラベルクエリなどの機能を提供し、効率的なデータ管理と分析を可能にします。
Iceberg
大規模なデータレイクに特化して設計されたNetflixによるオープンソースのテーブル形式です。主な焦点は、優れたパフォーマンスとスケーラビリティを確保しながら、ACIDコンプライアンス、タイムトラベル機能、スキーマ進化を提供することです。Icebergは、Apache SparkやPrestoなどの一般的なクエリエンジンとよく連携します。効率的なデータ操作、列レベルの統計、メタデータ管理などの機能を提供します。Icebergは、大規模なデータセットに対して高速で一貫性のある信頼性の高い分析を実行することができます。
Apache Hudi
Uberによってオープンソース化され、列指向のデータ形式に対する増分更新をサポートするように設計されました。主にApache SparkとApache Flinkからデータを取り込むことをサポートしています。また、Apache Kafkaなどの外部ソースから読み取るためのSparkベースのユーティリティも提供しています。Apache Hive、Apache Impala、およびPrestoDBからのデータの読み取りがサポートされています。また、HudiテーブルスキーマをHive Metastoreに同期する専用のツールもあります。
UniForm
今後登場するDelta Lake 3.0は、すべての3つのOTFに対してUniversal Format(UniForm)を提供することを目指しています。目標は、Delta LakeテーブルをHudiまたはIcebergテーブルとしてアクセス可能にすることです。UniFormは現在プレビュー中であり、制限があります。
データレイク & データウェアハウス または Lakehouse
Lakehouseは採用する最良のアプローチなのか、という問いに対する答えは、「状況次第」です。
あなたのアーキテクチャに決定する際に考慮すべきさまざまな要因があります。例えば、BigQuery、Snowflake、Synapse、またはRedshiftで作業するつもりであれば、2層アーキテクチャを採用することは賢明な選択です。これにより、データレイクの利点を活かしながら、DBMSデータベース内でデータモデルをホストすることができます。Lakehouseの概念はまだ比較的新しく、他のアーキテクチャパラダイムほど成熟していないことに注意が必要です。データレイクとデータウェアハウスの両方を活用することで、各プラットフォームの強みを活かし、チーム内の異なるスキルセットにアクセスすることができます。たとえば、データエンジニアリングチームはPythonとSparkを使用するかもしれませんが、データウェアハウスに専念しているチームはSQLを使用することができます。
データウェアハウスエンジンを選択する際には、徹底的な分析を行う価値があります。これには、同時実行性、オートスケーリング、ストレージからの計算の分離、Delta、Iceberg、Hudiなどのファイル形式との統合、非ネイティブクラウドプロバイダーとの限定的な互換性、ゼロコピークローニング、パフォーマンスチューニング、コスト、GISサポート、およびメンテナンス努力などの要因が含まれる場合があります。データウェアハウスは、データの一貫性とガバナンスの面で堅牢な機能を提供しています。データ検証、データ品質チェック、データガバナンスポリシーの施行などの組み込みメカニズムが備わっています。これらの機能は、厳格なデータガバナンスとコンプライアンス要件を持つ組織にとって非常に重要です。
複雑なETLプロセスを扱う場合や、データプレゼンテーションに大量の計算パワーが必要ない場合、2層アーキテクチャは適切な選択です。このような場合、データ処理のためにSparkとデータレイクを活用し、データを提供するためにオープンソースのデータベースであるPostgreSQLを組み合わせて使用することが効果的なアプローチです。
この記事が気に入ったらサポートをしてみませんか?